
DPUs for storage: a first look
We previously wrote an introduction on what DPUs are. Feel free to read it first if you missed it! Now it's time we start to explore their real potential in a concrete benchmark, and showcase how it could be used in the future.
The hardware
To make our initial tests, we used:
- 1x Dell PowerEdge R7515 (2U, EPYC 7262 @3.20GHz, 8C/16T, 64GiB RAM)
- 1x Kalray K200LP DPU card on a PCIe4 port

A computer in your computer
For those wondering, the card is running on Linux. There's roughly 5 "clusters", running 16 cores each:
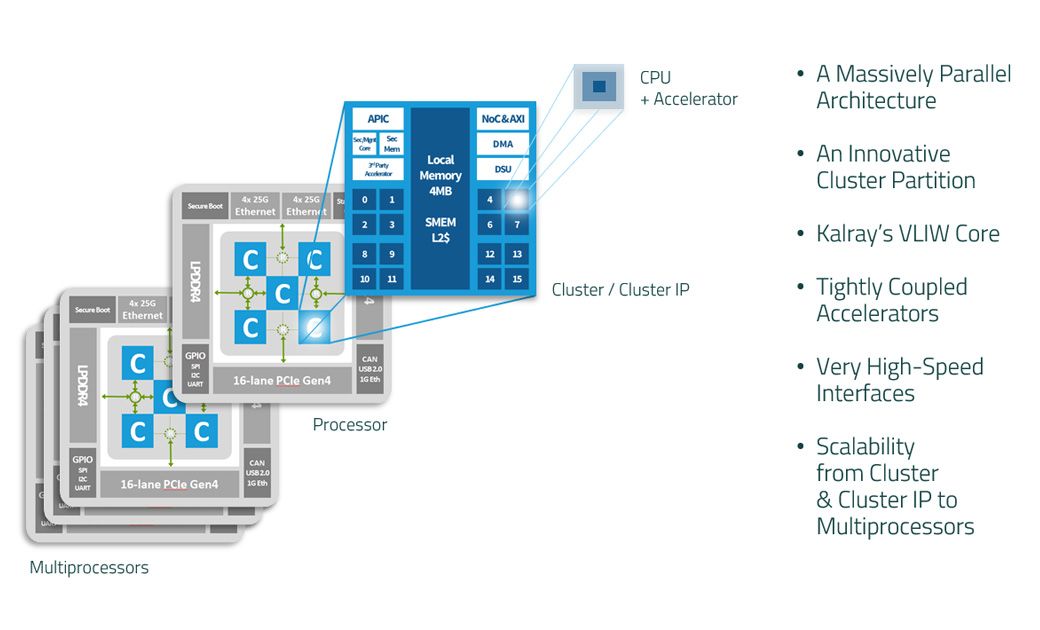
One "cluster" is running the management OS. You can connect to it, issuing a top command just for fun:
top - 14:21:20 up 9 min, 1 user, load average: 6.00, 5.10, 2.74
Tasks: 179 total, 2 running, 177 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0/0.0 0[ ]
%Cpu1 : 100.0/0.0 100[|||||||||||||||||||||||||||||||||||||||||||||||||||||]
%Cpu2 : 67.5/32.5 100[|||||||||||||||||||||||||||||||||||||||||||||||||||||]
%Cpu3 : 27.0/73.0 100[|||||||||||||||||||||||||||||||||||||||||||||||||||||]
%Cpu4 : 0.0/0.0 0[ ]
%Cpu5 : 0.0/0.0 0[ ]
%Cpu6 : 100.0/0.0 100[|||||||||||||||||||||||||||||||||||||||||||||||||||||]
%Cpu7 : 0.0/0.0 0[ ]
%Cpu8 : 0.0/0.0 0[ ]
%Cpu9 : 0.0/0.0 0[ ]
%Cpu10 : 1.9/1.3 3[|| ]
%Cpu11 : 0.0/0.0 0[ ]
%Cpu12 : 0.0/0.0 0[ ]
%Cpu13 : 0.0/0.0 0[ ]
%Cpu14 : 100.0/0.0 100[|||||||||||||||||||||||||||||||||||||||||||||||||||||]
%Cpu15 : 100.0/0.0 100[|||||||||||||||||||||||||||||||||||||||||||||||||||||]
GiB Mem : 37.0/2.9 [ ]
GiB Swap: 0.0/0.0 [ ]
Benchmarks
Benchmarks are a complicated thing. On VM storage for example, the current XCP-ng storage stack performance can only scale with multiple VM disks to reach the potential maximum of a local drive, a NAS or a SAN. With one disk, the bottleneck will be the CPU for one process, because one process = one virtual drive.
So one VM disk will be obviously vastly inferior to the overall pool performance, which doesn't matter in reality, when you run dozens of VMs at the same time (meaning more than dozens of disks in total). Obviously, we'll do more benchmarks in real situations when we have enough NVMe drives and space to do it! Those future results will be more accurate, but today it's just to get an order of magnitude.
Setup
The system is running on XCP-ng 8.2, fully patched.
In order to be sure there's no potential bottleneck on an NVMe drive, we'll rely on the "embedded" NVMe drives in the card itself. In short, those are small "virtual" NVMe drives in RAM, exposed as NVMe PCIe devices, 512MiB in size. This way, we are sure to NOT be limited by a real/classical NVMe drive speed.
You can see them in the lsblk command in the dom0:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme1n1 259:5 0 512M 0 disk
nvme2n1 259:6 0 512M 0 disk
nvme3n1 259:4 0 512M 0 disk
nvme4n1 259:7 0 512M 0 diskWe'll benchmark the "fake" nvme1n1 drive, in 3 ways:
- Using the "legacy" storage stack: creating a Storage Repository and then a virtual drive in it, attaching the Xen PV drive to the guest, then running
fioin it. - Attaching the "virtual" NVMe drive via PCI passthrough to the guest, then running
fiothe same way. - Using an Ubuntu LiveCD and directly test the drive without any virtualization stack, just mount it and run
fiofrom the live system.
We used fio benchmarks with 4k block size, 64 in IO depth on top of libaio, both for random read and random write.
Results
In theory, we should have used a bare metal host with a similar kernel, but it was faster to just start an Ubuntu Live CD and do the benchmark anyway. We can consider it a draw: we have bare metal performances in our VM, and twice the performance of the legacy stack (but remember, for one disk alone).
Obviously, this is just a very short demonstration. We'll do a lot more when we'll have the peer-to-peer feature available (see below).
Conclusion
So you've had a glimpse at how the DPUs will change the storage landscape. Note that we only covered the storage part, and only for local NVMe drives (yes, it will be possible to rely on NVMe-oF targets in the future, seeing the drives as local NVMe!).
What's also interesting: we are not limited by the dom0 performance anymore! A more recent VM (with latest kernel for example) can enjoy even better performance on "almost" real hardware. And it also means less x86 CPU cycles used for storage, and more for compute, while enjoying faster storage.
To recap, the final workflow will look like this:
- First, you will ask the DPU card to take control of one or more real NVMe drive(s) inside your machine (eg a 512GiB Optane drive). This step is done once for all.
- From there, you can dynamically order the DPU to give you a virtual NVMe drive of the size you like (eg 20GiB). It will instantly appear as a traditional NVMe drive, visible with
lspcifor example. - Finally, the drive will be attached to your VM as a regular PCI passthrough device.
Obviously, all steps will be fully automated and exposed via the Xen Orchestra UI.
In the end, you'll enjoy baremetal NVMe disk performance in your VM, while keeping its agility. Yes, you read it correctly: the plan is to provide something equivalent to vGPU's with live migration capabilities. But for the storage, a kind of "vNVMe" solution that will outperform any other virtual machine storage performance currently known.
Next challenge: P2P mode
Our big next challenge will be to make the DPU peer-to-peer mode working on Xen, so we can put the physical NVMe "behind" the DPU, on the same host. This might require some advanced modifications, but this is an active topic for us in 2022.

Acknowledgements
A big thanks to Kalray for lending us the card! We are working closely together to tackle the challenges of delivering a solution fully integrated, from the hardware to the software.


