Remove backup bottleneck: please report
-
@Slugger said in Remove backup bottleneck: please report:
If hosts are talking https by default, can they be switched to http using something similar to this?
This would be a huge improvement for disk migrations. I did and do many migration in the next days. This is what I found on CLI:
# ps aux | cat | grep sparse_dd root 32352 2.3 0.1 158188 28520 ? Ssl 23:07 0:59 /usr/libexec/xapi/sparse_dd -machine -src /dev/sm/backend/24236a41-7f7d-8edb-99df-6eb8ba26b715/cf04f6a0-1d79-4846-918e-97184cd68d16 -dest http://XX.XX.XX.XX/services/SM/nbd/187a0b1a-d927-f06f-0a3c-ec5e69414660/481306d1-3057-4ceb-9b7b-19b6e4f3dbe2/063a4c43-8abf-b2ee-dd78-29f46df34084?session_id=OpaqueRef%3addc8eaf8-aaaa-43a6-bff1-20c4a91ef371 -size 214748364800 -good-ciphersuites !EXPORT:RSA+AES128-SHA256 -legacy-ciphersuites RSA+AES256-SHA:RSA+AES128-SHA:RSA+RC4-SHA:RSA+DES-CBC3-SHA -ssl-legacy -prezeroedIt seems to connect using http but has
-ssl-legacyin the command, I assume is uses SSL under the hood.Would be nice to avoid these additional layers at all.
-
Hello @all
I try the new new compression with may small envirment its running. I am using for XO a HP620 Thin client. The direct export with the new compression is working. A very small VM with 30GB HDD (4GByte in use) the transferrate was between 5MByte/s to 18MByte/s. A bigger one with 300GByte (200 in use) ther was the rate mostly araound 20MByte, but the transfer was moving to a USB2 HDD.
It looks very fine next i will try a transfer to a local disk or a USB3.0 HDD
-
Wow, switching to
httpmade quite a difference! By rough calculation, time to do a continuous replication is about 1/4 of what it previously was.My XOA is connected to a 1Gbps interface and so are the various XCP servers. This is a dedicated network for VM server management / VM replication.
As comparison, a 1.76TiB VM took 11 hours 28 min to do it's initial replication when running on
https. But oncehttpswas turned off, a different VM which is 4.28TiB, took 19 hours and 58 minutes. It was the first time I was able to do an initial replication on this VM as previously, it would take more than 24 hours and XCP would kill the job.Smaller continuous replication jobs (deltas) are also faster. 40-60 minutes to do a 120GiB delta with
https, onhttptook 25 minutes.I can probably gain more by moving the replication to a 10G network - or at least XOA will be able to deal better with concurrent replication jobs between different servers since it all funnels through XOA.
-
In you case,
stunnelwas probably a bottleneck, yes.What's the CPU model on your dom0? Also if your dom0 CPU usage is high, you have less computer power for
stunnel, explaining the perf diff you have in your case (but it's not universal) -
CPU are Intel E5-2609 v4 @ 1.70GHz in this case.
Overall stats show CPU below 50% usage overall, load average between 3-4 during continue replication job.
Dom0 top show 2-3 load average.
-
Yes so on a low frequency CPU,
stunnelis indeed a bottleneck. It's far less the case on CPU with higher clock")
-
I realize this topic is ~9 months old, but I have been struggling getting XOA to take advantage of the 10GB network it's running on and the all SSD-based storage system it has at its disposal.
I finally came across this post--and for the first time in a year, I've found something that actually increases backup speeds beyond the dismal speeds I've been stuck with.
When I switched everything to HTTP, I went from backing up 100GiB in an hour to just under 19 minutes--a 3 fold increase!! And all that from something as simple as putting HTTP in front of the Server IP. Woot!
The CPUs involved in this are not slouches XEON D's with 8 cores... so I don't think it's a DOM0 slowdown.
I still don't feel I am getting everything out of the system, but that is remarkably better.
Thank you for this tip. Wish there was a prominent section dedicated to increasing backup speeds. I'd pin this post to the very top as the gains from doing this far exceed messing around with concurrency and other settings...
Thanks gang!
-
Thanks for the feedback. In your case, Xeon D is likely causing slowness on HTTPS. I'll update the doc for putting this advice
-
@olivierlambert Hmmm... this comes from a test lab box, no other activity occurring, VMs are powered off for duration of these backup tests (except the XOA vm, which runs on a different box then the one being backed up), so there's zero load and I don't see the CPU ever getting over even 10% in dom0.
Have the same issue/see the same results on dual 24 core E5s. Granted those are also 2.2GHZ. What would be minimally acceptable CPU to overcome that 3x performance penalty of stunnel? I guess I should read up on the stunnel limitations more.
Could it be I'm not giving the XOA vm enough CPU/RAM? Or the wrong topology? I've looked for guidance on that too and haven't seen much online about it (especially in regards to speed).
Either way, I am excited that we can start taking advantage of that 3x increase in speed. Security can be handled by a VLAN/separate storage network, so really not concerned about using HTTP instead of HTTPS.
Any tips on how to configure storage/networks to take advantage of every bit of juice available would be awesome.
Thanks again for all you and your teams have done!!
-
@julien-f is doing a ton of work to rewire all backup code in a way it could be split into small bits, so we'll be able to get an easier code to improve and benchmark relatively soon
For example, we should have a stream "waiting" info to find which part in the chain is slowing things done. It's really hard without that to know where the bottleneck is.
Might be a limit in
stunnelbut as soon we got our "stream probe" we'll be able to pinpoint it more exactly.Also, with and without HTTPS, are you seeing an XOA CPU usage change?
-
@olivierlambert Havent looked at that in a while... I'll run a test here shortly.
-
BTW, this is not quite the exact same setup as before (there are some test vm's idling in the background and I am only backing up a single VM). That said DOM0 on both the host running the VM being backed up and the host running the XOA box were in the 10%-15% range for the duration of the tests and idling around 2-4%
While the peaks in CPU under HTTPS do show slightly higher, the biggest thing I see is the wide divergence in the CPU on the two cores under HTTPS. Under HTTP, they look to be in lock step. Also note that the RAM usage on the XOA box jumps to full after about 25% of the way through the job. XOA was given 2 sockets with 1 core socket and 4GB ram.
Oh, and you can see we aren't even maxing 100MBps, let alone a 10GB. Disks involved are single SSDs, SATA6. So I dont expect to see 10GBps but still. Shouldn't I expect to see way more than 50? Those SSDs can easily do 500.
HTTP/ XOA performance. 3 mins for 18.89GIB
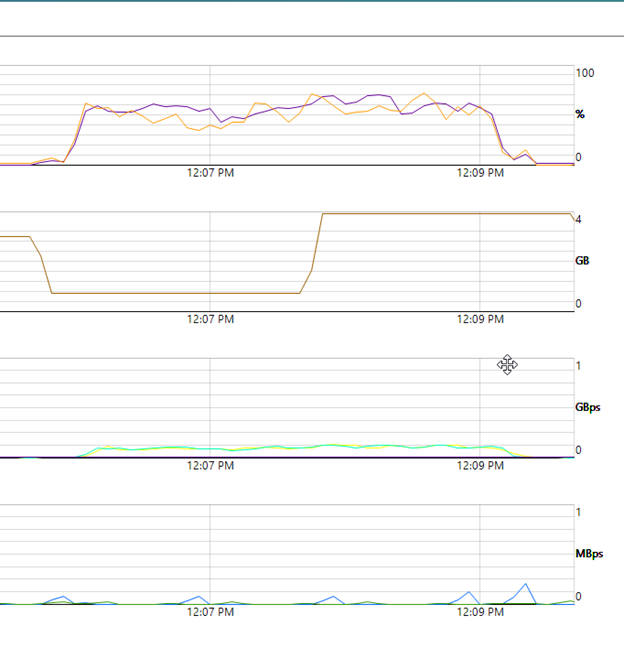
HTTPS/ XOA performance. 7 mins for 18.89GIB
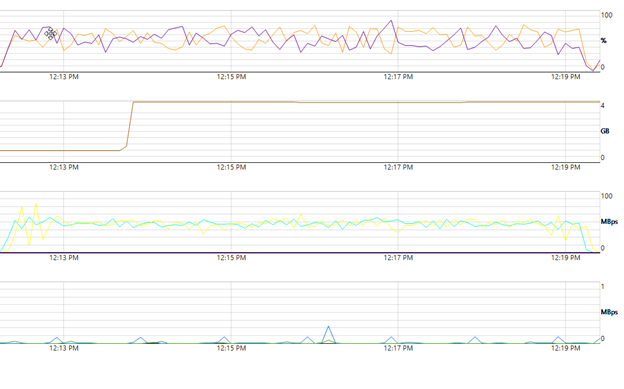
-
Using Netdata would deliver for more insight on what's happening, both on the host and XO
-
Hello,
Http ~7 times faster than https on our system for cr jobs. Https ~50MB/sec. Http ~350MB/sec.
xo from source 5.60
xcp-ng 8.0
10 gbit connection everywhere
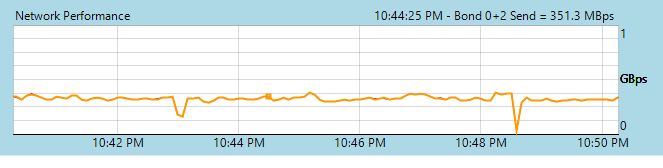
-
@rizaemet-0 said in Remove backup bottleneck: please report:
Http ~7 times faster than https on our system for cr jobs. Https ~50MB/sec. Http ~350MB/sec.
Wow, 350 is really a nice speed!
-
For me, switching to http seems to have increased the backup speed by about 3.5 times as well. However I feel like it's still pretty slow. I went from a reported transfer speed average of 3.26 MiB/s to 11.59 MiB/s across 16 VMs running on a pool consisting of two 8.1 XCP-ng hypervisors and a 5.61 Xen Orchestra Community VM backing up to an NFS share on a Synology RackStation over a 10 Gb/s storage network. When testing the speed with which I am able to write to the NFS share from the XO VM with dd it's averaging write speeds of about 95 MB/s.
Anything else I can do to try and figure out where the next bottleneck is?
-
That's slow indeed

It's not trivial. A lot of things could cause that. However, you can test by:
- changing backup concurrency to find a sweet spot (one VM, then 2 VM etc.)
- give more memory to the dom0
- give more memory to the XO VM
- having an SSD on the backup storage
- having an SSD on the storage repository
-
I will for sure attempt and see how fast it is to backup only one VM at a time... actually I guess I don't know the answer to this but when XO does a delta backup to an NFS remote does it attempt to transfer all VM snapshots at the same time or does it do it sequentially one after the other?
-
-
Thank you so much for this info, I can't believe I didn't see this in all of my research. With the information from that document I take it back. I am getting full bandwidth since 12 machines get backed up at a time. The individual VM transfer speed in the backup reports was a bit misleading to me since I didn't realize that 12 are uploaded to storage at a time.
My initial finding still stands though, going http completely removed the one bottleneck that we had in our backup infrastructure and made it 3.5 times faster then before.