Alert: Control Domain Memory Usage
-
Today another customer called:
He had a host (pool master) with 16GB Dom0 mem and uptime of 119 days.
Currently all my affected Systems were using megaraid_sas and iscsi and 10g intel nics.
megaraid_sas is found in @MrMike and @inaki-martinez mods too.
This is the customers lsmod:
Module Size Used by tun 49152 0 ebtable_filter 16384 0 ebtables 36864 1 ebtable_filter nls_utf8 16384 0 cifs 929792 0 ccm 20480 0 fscache 380928 1 cifs iscsi_tcp 20480 16 libiscsi_tcp 28672 1 iscsi_tcp libiscsi 61440 2 libiscsi_tcp,iscsi_tcp scsi_transport_iscsi 110592 3 iscsi_tcp,libiscsi bonding 176128 0 bridge 196608 1 bonding 8021q 40960 0 garp 16384 1 8021q mrp 20480 1 8021q stp 16384 2 bridge,garp llc 16384 3 bridge,stp,garp ipt_REJECT 16384 3 nf_reject_ipv4 16384 1 ipt_REJECT xt_tcpudp 16384 8 xt_multiport 16384 1 xt_conntrack 16384 5 nf_conntrack 163840 1 xt_conntrack nf_defrag_ipv6 20480 1 nf_conntrack nf_defrag_ipv4 16384 1 nf_conntrack libcrc32c 16384 1 nf_conntrack iptable_filter 16384 1 dm_multipath 32768 0 sunrpc 413696 1 sb_edac 24576 0 intel_powerclamp 16384 0 crct10dif_pclmul 16384 0 crc32_pclmul 16384 0 ghash_clmulni_intel 16384 0 pcbc 16384 0 aesni_intel 200704 0 aes_x86_64 20480 1 aesni_intel crypto_simd 16384 1 aesni_intel cryptd 28672 3 crypto_simd,ghash_clmulni_intel,aesni_intel glue_helper 16384 1 aesni_intel dm_mod 151552 285 dm_multipath ipmi_si 65536 0 ipmi_devintf 20480 0 intel_rapl_perf 16384 0 ipmi_msghandler 61440 2 ipmi_devintf,ipmi_si i2c_i801 28672 0 sg 40960 0 lpc_ich 28672 0 acpi_power_meter 20480 0 ip_tables 28672 2 iptable_filter x_tables 45056 7 ebtables,xt_conntrack,iptable_filter,xt_multiport,xt_tcpudp,ipt_REJECT,ip_tables hid_generic 16384 0 usbhid 57344 0 hid 122880 2 usbhid,hid_generic sd_mod 53248 9 isci 163840 0 ahci 40960 0 libsas 86016 1 isci libahci 40960 1 ahci scsi_transport_sas 45056 2 isci,libsas xhci_pci 16384 0 ehci_pci 16384 0 igb 233472 0 libata 274432 3 libahci,ahci,libsas ehci_hcd 90112 1 ehci_pci xhci_hcd 258048 1 xhci_pci e1000e 286720 0 megaraid_sas 167936 12 scsi_dh_rdac 16384 0 scsi_dh_hp_sw 16384 0 scsi_dh_emc 16384 0 scsi_dh_alua 20480 1 scsi_mod 253952 15 isci,scsi_dh_emc,scsi_transport_sas,sd_mod,dm_multipath,scsi_transport_iscsi,scsi_dh_alua,iscsi_tcp,libsas,libiscsi,megaraid_sas,libat a,sg,scsi_dh_rdac,scsi_dh_hp_sw ipv6 548864 545 bridge crc_ccitt 16384 1 ipv6 -
@dave can you open a ticket please? So we can also take a look remotely via a support tunnel.
-
We also have 10GbE Intel interfaces on the affected servers, not using iscsi yet on these servers.
So I think the comon factors right now would be the sas megaraid and 10GbE Intel nics?
-
We also have the same setup, running on affected hosts with iSCSI pool devices connected
Module Size Used by tun 49152 0 iscsi_tcp 20480 5 libiscsi_tcp 28672 1 iscsi_tcp libiscsi 61440 2 libiscsi_tcp,iscsi_tcp scsi_transport_iscsi 110592 3 iscsi_tcp,libiscsi dm_service_time 16384 4 arc4 16384 0 md4 16384 0 nls_utf8 16384 1 cifs 929792 2 ccm 20480 0 fscache 380928 1 cifs bnx2fc 159744 0 cnic 81920 1 bnx2fc uio 20480 1 cnic fcoe 32768 0 libfcoe 77824 2 fcoe,bnx2fc libfc 147456 3 fcoe,bnx2fc,libfcoe openvswitch 147456 12 nsh 16384 1 openvswitch nf_nat_ipv6 16384 1 openvswitch nf_nat_ipv4 16384 1 openvswitch nf_conncount 16384 1 openvswitch nf_nat 36864 3 nf_nat_ipv6,nf_nat_ipv4,openvswitch 8021q 40960 0 garp 16384 1 8021q mrp 20480 1 8021q stp 16384 1 garp llc 16384 2 stp,garp ipt_REJECT 16384 3 nf_reject_ipv4 16384 1 ipt_REJECT xt_tcpudp 16384 9 xt_multiport 16384 1 xt_conntrack 16384 5 nf_conntrack 163840 6 xt_conntrack,nf_nat,nf_nat_ipv6,nf_nat_ipv4,openvswitch,nf_conncount nf_defrag_ipv6 20480 2 nf_conntrack,openvswitch nf_defrag_ipv4 16384 1 nf_conntrack libcrc32c 16384 3 nf_conntrack,nf_nat,openvswitch iptable_filter 16384 1 dm_multipath 32768 5 dm_service_time intel_powerclamp 16384 0 crct10dif_pclmul 16384 0 crc32_pclmul 16384 0 ghash_clmulni_intel 16384 0 pcbc 16384 0 aesni_intel 200704 0 aes_x86_64 20480 1 aesni_intel crypto_simd 16384 1 aesni_intel cryptd 28672 3 crypto_simd,ghash_clmulni_intel,aesni_intel glue_helper 16384 1 aesni_intel dm_mod 151552 22 dm_multipath ipmi_si 65536 0 i2c_i801 28672 0 sg 40960 0 ipmi_devintf 20480 0 i7core_edac 28672 0 lpc_ich 28672 0 ipmi_msghandler 61440 2 ipmi_devintf,ipmi_si i5500_temp 16384 0 acpi_power_meter 20480 0 sunrpc 413696 1 ip_tables 28672 2 iptable_filter x_tables 45056 6 xt_conntrack,iptable_filter,xt_multiport,xt_tcpudp,ipt_REJECT,ip_tables sr_mod 28672 0 cdrom 69632 1 sr_mod sd_mod 53248 7 ata_generic 16384 0 pata_acpi 16384 0 uhci_hcd 49152 0 lpfc 958464 4 ata_piix 36864 0 nvmet_fc 32768 1 lpfc nvmet 69632 1 nvmet_fc libata 274432 3 ata_piix,pata_acpi,ata_generic nvme_fc 45056 1 lpfc nvme_fabrics 24576 1 nvme_fc ehci_pci 16384 0 igb 233472 0 ehci_hcd 90112 1 ehci_pci nvme_core 81920 2 nvme_fc,nvme_fabrics ixgbe 380928 0 megaraid_sas 167936 2 scsi_transport_fc 69632 4 fcoe,lpfc,libfc,bnx2fc scsi_dh_rdac 16384 0 scsi_dh_hp_sw 16384 0 scsi_dh_emc 16384 0 scsi_dh_alua 20480 5 scsi_mod 253952 19 fcoe,lpfc,scsi_dh_emc,sd_mod,dm_multipath,scsi_transport_iscsi,scsi_dh_alua,scsi_transport_fc,libfc,iscsi_tcp,bnx2fc,libiscsi,megaraid_sas,libata,sg,scsi_dh_rdac,scsi_dh_hp_sw,sr_mod ipv6 548864 173 nf_nat_ipv6 crc_ccitt 16384 1 ipv6 -
We have a pro-support user who also is affected.
ixgbeis present but nomegaraid_sas.If (and only if) the leak cause is common to everyone, then
ixgbewould then be the main suspect. -
-
@olivierlambert The servers (2) I am seeing the memory leaks are used exclusively for network intensive applications. they route and tunnel many (100+) tunnels.
Other systems I have with similar host configuration are not seeing any increased domain memory usage.
-
So, I checked the other hosts in my environment that run the same types of VMs and also have the same version of xcp-ng.
Hosts that are not seeing this memory leak have BCM5720 1GbE interfaces. They are not as heavily used so I'm not sure if the leak only occurs if usage is very high or using a specific feature/ function in that driver.
-
So, @r1 has prepared a
kernelRPM for XCP-ng 8.1 that enables kmemleak. If anyone wants to give it a try (on XCP-ng 8.1 only), you can install it with:yum install http://koji.xcp-ng.org/kojifiles/work/tasks/7624/17624/kernel-4.19.19-6.0.12.1.1.kmemleak.xcpng8.1.x86_64.rpm rebootYou can revert to the main kernel with:
# yum downgrade won't work for the kernel because it's a protected package, so let's use rpm yumdownloader rpm -Uv --oldpackage name-of-file.rpm rebootThere will be some performance impact that I'm not able to quantify and I'm not yet able to tell you how to use it to debug memory leaks, but there's plenty of documentation on the internet about kmemleak.
-
Hello,
We have the same problem here on multiple servers.
We also have 10G interfaces. We use
extlocal SR.(::bbxl0271) (2 running) [08:43 bbxl0271 ~]# lsmod | sort -k 2 -n -r ipv6 548864 313 nf_nat_ipv6 sunrpc 413696 18 lockd,nfsv3,nfs_acl,nfs ixgbe 380928 0 fscache 380928 1 nfs nfs 307200 2 nfsv3 libata 274432 2 libahci,ahci xhci_hcd 258048 1 xhci_pci scsi_mod 253952 15 fcoe,scsi_dh_emc,sd_mod,dm_multipath,scsi_dh_alua,scsi_transport_fc,usb_storage,libfc,bnx2fc,uas,megaraid_sas,libata,sg,scsi_dh_rdac,scsi_dh_hp_sw aesni_intel 200704 0 megaraid_sas 167936 4 nf_conntrack 163840 6 xt_conntrack,nf_nat,nf_nat_ipv6,nf_nat_ipv4,openvswitch,nf_conncount bnx2fc 159744 0 dm_mod 151552 5 dm_multipath openvswitch 147456 12 libfc 147456 3 fcoe,bnx2fc,libfcoe hid 122880 2 usbhid,hid_generic mei 114688 1 mei_me lockd 110592 2 nfsv3,nfs cnic 81920 1 bnx2fc libfcoe 77824 2 fcoe,bnx2fc usb_storage 73728 1 uas scsi_transport_fc 69632 3 fcoe,libfc,bnx2fc ipmi_si 65536 0 ipmi_msghandler 61440 2 ipmi_devintf,ipmi_si usbhid 57344 0 sd_mod 53248 5 tun 49152 0 nfsv3 49152 1 x_tables 45056 6 xt_conntrack,iptable_filter,xt_multiport,xt_tcpudp,ipt_REJECT,ip_tables mei_me 45056 0 sg 40960 0 libahci 40960 1 ahci ahci 40960 0 8021q 40960 0 nf_nat 36864 3 nf_nat_ipv6,nf_nat_ipv4,openvswitch fcoe 32768 0 dm_multipath 32768 0 uas 28672 0 lpc_ich 28672 0 ip_tables 28672 2 iptable_filter i2c_i801 28672 0 cryptd 28672 3 crypto_simd,ghash_clmulni_intel,aesni_intel uio 20480 1 cnic scsi_dh_alua 20480 0 nf_defrag_ipv6 20480 2 nf_conntrack,openvswitch mrp 20480 1 8021q ipmi_devintf 20480 0 aes_x86_64 20480 1 aesni_intel acpi_power_meter 20480 0 xt_tcpudp 16384 9 xt_multiport 16384 1 xt_conntrack 16384 5 xhci_pci 16384 0 stp 16384 1 garp skx_edac 16384 0 scsi_dh_rdac 16384 0 scsi_dh_hp_sw 16384 0 scsi_dh_emc 16384 0 pcbc 16384 0 nsh 16384 1 openvswitch nfs_acl 16384 1 nfsv3 nf_reject_ipv4 16384 1 ipt_REJECT nf_nat_ipv6 16384 1 openvswitch nf_nat_ipv4 16384 1 openvswitch nf_defrag_ipv4 16384 1 nf_conntrack nf_conncount 16384 1 openvswitch llc 16384 2 stp,garp libcrc32c 16384 3 nf_conntrack,nf_nat,openvswitch ipt_REJECT 16384 3 iptable_filter 16384 1 intel_rapl_perf 16384 0 intel_powerclamp 16384 0 hid_generic 16384 0 grace 16384 1 lockd glue_helper 16384 1 aesni_intel ghash_clmulni_intel 16384 0 garp 16384 1 8021q crypto_simd 16384 1 aesni_intel crct10dif_pclmul 16384 0 crc_ccitt 16384 1 ipv6 crc32_pclmul 16384 0I'll install the
kmemleakkernel on one server today. -
I tried to install the kernel as described, but I got an error :
# yum install http://koji.xcp-ng.org/kojifiles/work/tasks/7620/17620/kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64.rpm Loaded plugins: fastestmirror kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64.rpm | 30 MB 00:00:03 Examining /var/tmp/yum-root-Uyd1Lb/kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64.rpm: kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64 /var/tmp/yum-root-Uyd1Lb/kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64.rpm: does not update installed package. Error: Nothing to doThe host is a 8.1 up to date (latest patchs are installed but I did not reboot yep after).
-
FYI : On one host that has the problem I only have 1 Debian VM that does only one thing : netdata. It is a netdata that get flows from other netdata and that is polled by a prometheus server (which is on another host).
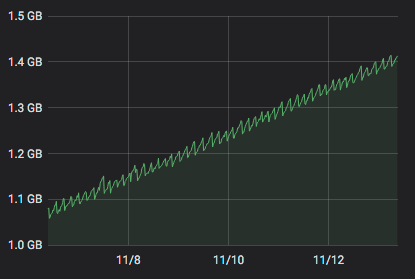
-
As soon as I stopped the last VM on the host, there is no more memleak.
-
More informations:
# rpm -ivh http://koji.xcp-ng.org/kojifiles/work/tasks/7620/17620/kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64.rpm Retrieving http://koji.xcp-ng.org/kojifiles/work/tasks/7620/17620/kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64.rpm Preparing... ################################# [100%] package kernel-4.19.19-6.0.12.1.xcpng8.1.x86_64 (which is newer than kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64) is already installed file /boot/System.map-4.19.0+1 from install of kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64 conflicts with file from package kernel-4.19.19-6.0.12.1.xcpng8.1.x86_64 file /boot/config-4.19.0+1 from install of kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64 conflicts with file from package kernel-4.19.19-6.0.12.1.xcpng8.1.x86_64 file /boot/vmlinuz-4.19.0+1 from install of kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64 conflicts with file from package kernel-4.19.19-6.0.12.1.xcpng8.1.x86_64 file /lib/modules/4.19.0+1/kernel/fs/nfs/nfs.ko from install of kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64 conflicts with file from package kernel-4.19.19-6.0.12.1.xcpng8.1.x86_64 file /lib/modules/4.19.0+1/kernel/net/netfilter/nf_conntrack.ko from install of kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64 conflicts with file from package kernel-4.19.19-6.0.12.1.xcpng8.1.x86_64 file /lib/modules/4.19.0+1/modules.order from install of kernel-4.19.19-6.0.12.1.kmemleak.1.xcpng8.1.x86_64 conflicts with file from package kernel-4.19.19-6.0.12.1.xcpng8.1.x86_64 -
I built a new kernel with memleak, which should install correctly. I've updated my post with the instructions above.
-
@stormi Ok thank you. The installation works.
I made another test: use the kernel-alt 4.19.108 on one box. It seems I did not have the issue anymore!
-
On server with kmemleak kernel, I get this error:
# echo scan > /sys/kernel/debug/kmemleak -bash: echo: write error: Device or resource busyDigging a litlle bit, and I found :
# dmesg | grep memleak [ 0.677307] kmemleak: Kernel memory leak detector disabled [ 2.701225] kmemleak: Early log buffer exceeded (5128), please increase DEBUG_KMEMLEAK_EARLY_LOG_SIZESo kmemleak is still disabled as DEBUG_KMEMLEAK_EARLY_LOG_SIZE seems to be too small

@stormi Could you rebuild a kernel with an increased DEBUG_KMEMLEAK_EARLY_LOG_SIZE?Thank you!
-
Pinging @r1 about this.
-
-
")
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login