Alert: Control Domain Memory Usage
-
-
@delaf said in Alert: Control Domain Memory Usage:
one server (268) with 4.19.19-6.0.10.1.xcpng8.1: no more problem!
Yeah, we need to be sure that this is a stable kernel and somewhere after this, the memory leak seems to have introduced.
-
I currently have:
top - 13:35:31 up 59 days, 17:11, 1 user, load average: 0.43, 0.36, 0.34 Tasks: 646 total, 1 running, 436 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.8 us, 1.1 sy, 0.0 ni, 97.5 id, 0.3 wa, 0.0 hi, 0.1 si, 0.2 st KiB Mem : 12205936 total, 149152 free, 10627080 used, 1429704 buff/cache KiB Swap: 1048572 total, 1048572 free, 0 used. 1153360 avail Memtop - 13:35:54 up 35 days, 17:29, 1 user, load average: 0.54, 0.73, 0.77 Tasks: 489 total, 1 running, 324 sleeping, 0 stopped, 0 zombie %Cpu(s): 3.5 us, 3.4 sy, 0.0 ni, 92.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.4 st KiB Mem : 12207996 total, 155084 free, 9388032 used, 2664880 buff/cache KiB Swap: 1048572 total, 1048572 free, 0 used. 2394220 avail Memboth with:
# uname -a Linux xs01 4.19.0+1 #1 SMP Thu Jun 11 16:18:33 CEST 2020 x86_64 x86_64 x86_64 GNU/Linux # yum list installed | grep kernel kernel.x86_64 4.19.19-6.0.11.1.xcpng8.1 @xcp-ng-updatesshall i test something?
-
I have a set of hosts on kernel-4.19.19-6.0.11.1.xcpng8.1 and I believe I'm hitting this as well. The OOM seems to kill openvswitch, which takes the host offline and in most cases, the VMs as well.
-
So, the difference between 4.19.19-6.0.10.1.xcpng8.1 and 4.19.19-6.0.11.1.xcpng8.1 is two patches meant to reduce the performance overhead of the CROSSTalk vulnerability mitigations.
So, assuming from @delaf's test results that one of those patches introduced the memory leak, I have built
Now here are the tests that you can do:
- Reproduce @delaf's findings by running
kernel-4.19.19-6.0.10.1.xcpng8.1: no more memory leaks? - Test this kernel I built with patch 53 disabled: https://nextcloud.vates.fr/index.php/s/YXWCSEwo8SWkfAZ
- Test this kernel I built with patch 62 disabled: https://nextcloud.vates.fr/index.php/s/arj5YfdrkjMKbBy
If one of the patches is the cause of the memory leak, then one of the last two should still cause a memory leak and the other one not.
- Reproduce @delaf's findings by running
-
@stormi I have installed the two kernels
272 ~]# yum list installed kernel | grep kernel kernel.x86_64 4.19.19-6.0.11.1.0.1.patch53disabled.xcpng8.1 273 ~]# yum list installed kernel | grep kernel kernel.x86_64 4.19.19-6.0.11.1.0.1.patch62disabled.xcpng8.1I have removed the modification in
/etc/modprobe.d/dist.confon server 273.We have to wait a little bit now
")
-
FYI, the kernel with kmemleak support did detect something for a user who has a support ticket related to dom0 memory usage.
-
@stormi For the
kernel-4.19.19-6.0.10.1.xcpng8.1test, i'm not sure it solve the problem because I get a small memory increase. We have to wait a bit more
-
-
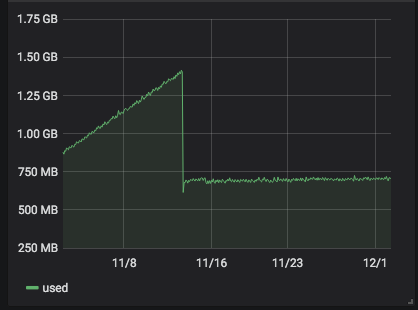
server 266 with
alt-kernel: still no problem.
-
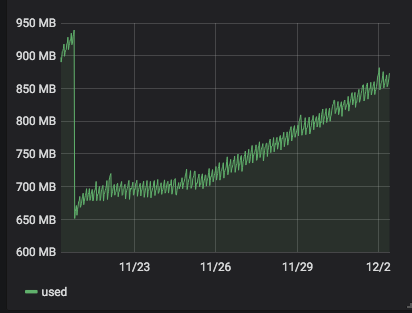
server 268 with
4.19.19-6.0.10.1.xcpng8.1: the problem has begun some days ago after some stable days.
-
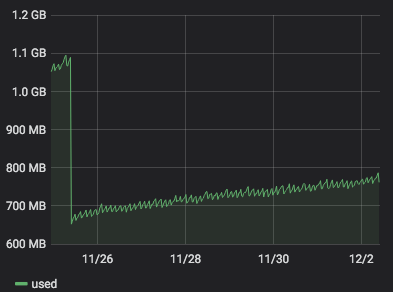
server 272 with
4.19.19-6.0.11.1.0.1.patch53disabled.xcpng8.1:
 )
) -
server 273 with
4.19.19-6.0.11.1.0.1.patch62disabled.xcpng8.1:
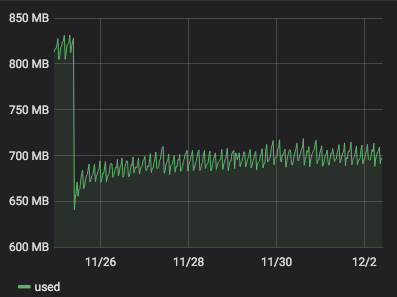
It seems that
4.19.19-6.0.11.1.0.1.patch62disabled.xcpng8.1is more stable than4.19.19-6.0.11.1.0.1.patch53disabled.xcpng8.1. But it is a but early to be sure. -
-
-
Thanks. It looks like I'm doomed to see seemingly contradictory results for every kernel-related issue (this one, and an other one regarding network performance): you don't have any leaks without patch 62, but you had leaks with kernel
4.19.19-6.0.10.1.xcpng8.1which doesn't have that patch either. So it's hard to conclude anything -
Hey Guys,
we are facing the same issue with xcp 8.1.
We can't figure out what uses all this memory (8GB) or how to reduce it. Restarting the Toolstack did nothing and we can't afford a downtime because everything runs in production. Similar systems with same configurations don't show such a behavior.I can provide you with some output from our system, maybe you can see something or help us finding a solution.
free -m
total used free shared buff/cache available Mem: 7912 7595 82 33 234 62 Swap: 1023 216 807xl top
NAME STATE CPU(sec) CPU(%) MEM(k) MEM(%) MAXMEM(k) MAXMEM(%) VCPUS NETS NETTX(k) NETRX(k) VBDS VBD_OO VBD_RD VBD_WR VBD_RSECT VBD_WSECT SSID Domain-0 -----r 7308446 52.1 8388608 3.1 8388608 3.1 16 0 0 0 0 0 0 0 0 0 0xe vm-param-list uuid | grep memory
memory-actual ( RO): 8589934592 memory-target ( RO): <unknown> memory-overhead ( RO): 84934656 memory-static-max ( RW): 8589934592 memory-dynamic-max ( RW): 8589934592 memory-dynamic-min ( RW): 8589934592 memory-static-min ( RW): 8589934592 memory (MRO): <not in database>lsmod and grub.cfg
lsmod.txt
grub-cgf.txttop output
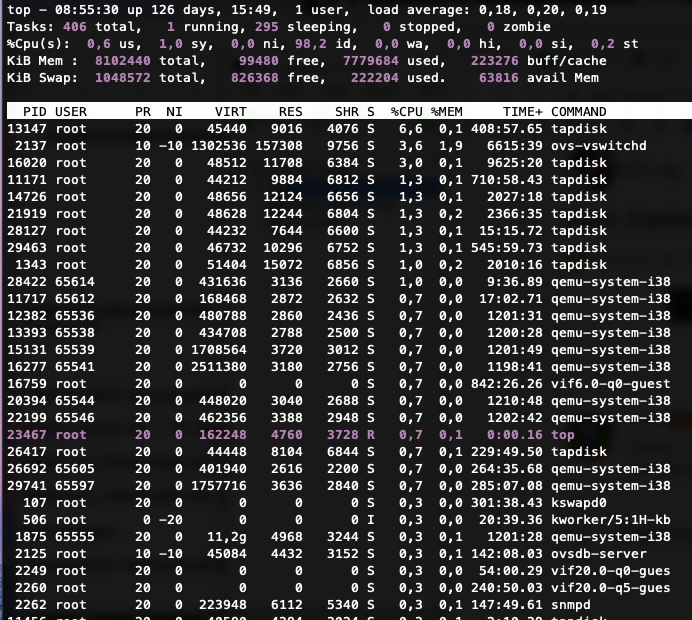
Tell me if you need more information or if you have any idea. Thanks.
-
We need more details on the host.
- Hardware detail (NICs, server model)
- If all your hardware is fully BIOS/firmware up to date
- The kind of storage used (iSCSI, FCoE, NFS?)
So far, we couldn't find a real common thing between people, and that's make hard to find the root cause.
-
It is a Dell PowerEdge R440 Version 2.6.3 with an LACP Bond and we use an NFS Storage.
-
That doesn't answer all my questions
-
NIC:
Intel(R) Ethernet 10G 2P X550-t Adapterdriver: ixgbe version: 5.5.2 firmware-version: 0x80000f32, 19.5.12RAID Controller:
Product Name : PERC H740P Adapter Serial No : 04B00V9 FW Package Build: 50.9.4-3025 Mfg. Data ================ Mfg. Date : 04/18/20 Rework Date : 04/18/20 Revision No : A03 Battery FRU : N/A Image Versions in Flash: ================ Boot Block Version : 7.02.00.00-0021 BIOS Version : 7.09.02.1_0x07090301 FW Version : 5.093.00-2856 NVDATA Version : 5.0900.06-0034I know our hardware is not fully up to date, but for an update we need a timeframe, which can not be arranged that quickly.
Maybe someone knows a temporary fix to reduce the usage of the dom0 memory until the updates can be made. -
Thanks.
If it's a kernel leak, there's nothing to do in user space.
-
Hi everyone.
So, let's not give up, and let's try to find that hidden kernel leak and fix it!
Let me summarize what we currently know. Correctly me if one of the statements is wrong for you:
- It all started with XCP-ng 8.0 and still happens in XCP-ng 8.1
- Memory is not used by user space processes. It's a kernel leak
- We have fixed a rsyslog memory leak through updates, but it was a different issue. By the way, if you have memory that is eaten by a user space process, please open a new thread so that we stay focused on the kernel leak here.
- Our alternate kernel,
kernel-alt, is apparently not affected. - Most (all?) affected hosts have 10Gb interfaces
- Many affected hosts are using iSCSI, though the last report (from @rblvlvl) is on a host with NFS storage
- Some reports suggest that the more network intensive the load is, the quicker the memory usage grows.
- Hosts with more VMs seem to see memory usage grow faster (may be related to the previous points)
- At some point we thought that reverting to a previous kernel (without some security patches) had solved the issue, but after some time memory usage started to grow again
kmemleakdid not detect obvious culprits, though @r1 has a lead regardingiscsi-related functions and we should still keep trying- Disabling the specific device drivers in favour of the built-in drivers in the kernel did not stop the leak
Things that we don't know (tests welcome):
- Is it affecting XCP-ng 8.2 too?
- Is it affecting Citrix Hypervisor? It should since we use the same kernel and drivers (mostly), but this doesn't seem to be a known issue to them.
Now, how to move on:
- Getting our hands on an affected test server and being authorized to reboot it, change the kernel, etc., would help a lot, since we can't reproduce internally (@dave maybe? At some point you said you might provide one)
- Reach out to kernel developers for advice?
- If someone manages to reproduce on Citrix Hypervisor, raise the issue on their bugtracker too.
- Check the kernel 4.19 history for memory leak fixes, especially those related to networking.
Any other idea to move on is welcome, of course.
-
Before I realized that not every affected host was using the
ixgbedriver, contrarily to what I initially thought, I built an alternate driver from the latest sources from Intel.So, even if there's little hope that it will fix anything, here's how to install it (on XCP-ng 8.1 or 8.2):
yum install intel-ixgbe-alt --enablerepo=xcp-ng-testing reboot -
Do we asked to provide also
lsmod? That might be interesting to overlap different results and see common ones.
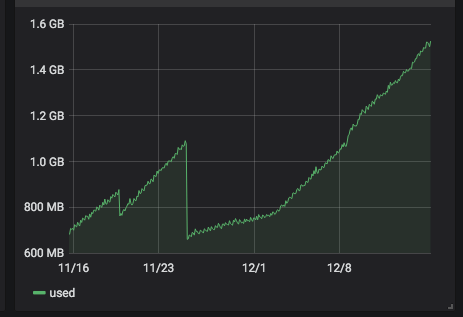
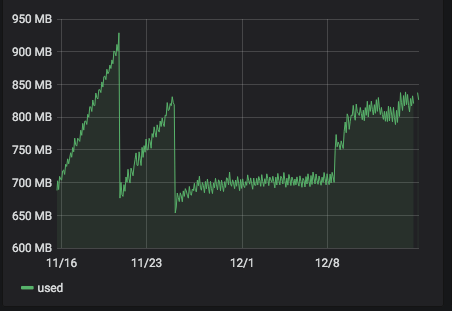
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login