
Understanding the storage stack in XCP-ng
In a virtualized environment, the role of a storage stack is to provide an intermediate layer between your physical storage and your virtual machines. The same way you are splicing CPU and memory for your VM, this layer will split the physical storage into smaller virtual disks. Indeed, inside the virtual machine you'll see what looks like a real block device. But then, the data will likely be transformed before landing on your physical storage, for example stored in VMDK or VHD format stored in actual files.
In short, every storage operation will operate through this layer, from snapshots to live migrations, backups and so on. Meanwhile your VM will continue to operate without noticing anything. In XCP-ng, the current storage stack is called SMAPIv1. We'll take a look at it, why it works well but also the inherent limits and why we decided to invest significant efforts in the successor: SMAPIv3.
SMAPIv1
SMAPIv1 is the technical name of the "Storage Manager" (version 1), the API allowing XenServer and XCP-ng to create virtual disks on physical storage, attach them to your VM and perform all the common virtualization tasks like live migration, snapshots and so on. This intermediate layer was introduced when XenServer came to life, back in 2008!

It consists of a series of "plug-ins" to XAPI (the Xen management layer/API) which are written primarily in Python. Keep in mind that in 2008, spinning drives were still king and SSDs are a very small minority in the market.
This stack was designed with some specific goals in mind, like providing a simple abstraction layer for various kinds of storage. To do that, the idea was to create a kind of "monolithic" system that will manage both the way a disk is attached to a VM, all the way up to how the data will be stored on the physical storage, and the complete lifecycle of the data.
To simplify this, it was decided to use the VHD format everywhere: regardless if you use a local disk, an iSCSI LUN or an NFS server. This way, SMAPIv1 could deal with all the logic of creating Copy on Write (CoW) volumes, to read them in a chain, to export them and even coalesce them when a snapshot was removed. By the way, that's why this storage stack is dealing with coalesce by itself - since you have VHD on all the stages. You can start to realize how monolithic it is: SMAPIv1 is really managing everything regarding your data!
Note that some systems (like a SAN or HBA devices) can't use flat VHD files directly, since there's no filesystem but only raw blocks available to store your data. That's why Citrix decided to rely on LVM for disk creation and snapshots, while still using VHD format inside the logical volume. That's why today in Citrix Hypervisor and XCP-ng, you have two possible "modes": thick and thin provisioning, which is only a consequence of the way the VHD format is stored.
- For file based volumes (local ext filesystem or NFS), you can use the "file" implementation of the VHD format. In short, a VM disk will simply be a
<UUID>.vhdfile stored on top of a filesystem. When you create a snapshot, you'll have the original "base copy" VHD file in read only, your snapshot file and your current active disk: so 3 VHD files laying on your filesystem. Active disks will grow while you add or change data in the VM disk. This is the thin provisioned usage of the VHD format. - For block based volumes (Local LVM, HBA, iSCSI),
SMAPIv1will create a logical volume of the size of the whole disk. If you want to create a 100GiB VM disk, it will create a logical volume of this size, regardless of the fact the virtual disk is empty. This is clearly thick provisioned. Note that when you do a snapshot, you'll need to reserve the same entire space for the new active disk, doubling the space used. Luckily, the base copy will be deflated a bit later, since it's in read only now.
If you want to visualize the process, here is a picture showing the volume just after a snapshot (A is your base copy, B the active disk and C the snapshot):
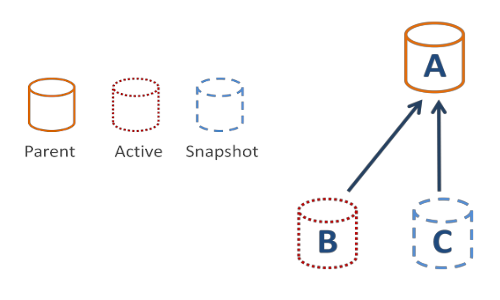
SMAPIv1 rise and fall
The best aspect of this overall design: all of your physical storage is using the same format, meaning your abstraction layer is exactly the same and you don't care about what's underneath! Enjoy live storage migration from a local RAID NVMe drive to an NFS server or an iSCSI storage appliance. With Xen Orchestra, you can also replicate the VM disk content every xx minutes/hours to another completely different storage on the other side of the planet! XO is also using the SMAPIv1 VHD differential capacity to do delta backups in a fully agentless way.
So yes, SMAPIv1 was a very capable storage stack which fit nicely into the storage context almost 15 years ago: few storage protocols (local, NFS, iSCSI), slow storage (HDD mostly) and limited capacity. But as usual, it has to be modified to keep up with new requirements: doing live migration, storage live migration, to work on shared block or file storage (SAN or NAS), while being able to do snapshots and so on. This added a lot of complexity to a simple architecture, as well as huge complexity, spaghetti code and technological debt: remember, you have to deal with everything from the volume management, snapshot and coalesce.

And the storage world is cruel: building something that works when everything is functioning as expected is easy. But when you have overloaded disks or flapping network connections for your iSCSI SAN and so on, it starts to be a nightmare to deal with. All of this is prone to race conditions, and it took more than 10 years to get a storage stack that's pretty solid. Even today, there's corner cases where we don't understand why volumes aren't correctly removed despite calling for removal (hence the health view in Xen Orchestra, able to identify such leftovers).
Another global limitation was leaving all the heavy lifting to be done by the Dom0 itself: when you export a disk, it has to be attached to Dom0 and exposed through XAPI HTTP. If you had a long chain, the read operation was pretty costly, reducing the export (backup speed). Export speed which is right now around 1Gbit/s max, okay-ish but far from modern expectations on 10Gbit/s and beyond networks!
In the end, it was already hard to deal with all the storage operations in a monolithic fashion, but storage evolution will exacerbate the existing limits even further: the need of more capacity, more IOPS, more throughput and also more flexibility with the new storage technologies replacing the legacy. A few examples: NVMe, NVMeOF, clustered filesystems like Gluster or Ceph, replicated block systems like LINSTOR, and finally even object storage!
Moving forward
So as we've seen, the "incremental" approach started to show its age in some situations. To be fair, it's still very potent is most current use cases, since it's pretty well optimized. But it's clearly not future-proof, especially if one wants to add more physical storage with Citrix Hypervisor or XCP-ng.
Citrix understood those limitations and started to work on a successor to replace SMAPIv1. The well named SMAPIv3. If you ask me why not SMAPIv2, I'll return the question about IPv5. We suppose that Citrix tried various architectures and that v3 was the most convincing one. We are not sure if it's the right internal name at Citrix, but we don't really care in the end, since it's just a technical name. The repository name is "Xapi storage interface", and the official documentation can be found here.

SMAPIv3
The broad concept of this new storage stack is to avoid creating an architectural monolith like the first version. In order to do that, it was decided to split the storage interface into 2 parts: the volume plugin and the datapath plugin. By doing so, you can have a dedicated storage team without any Xen knowledge to write their own volume plugins, and let the Xen experts improve the datapath plugin to answer some challenges related to specific storage implementation choices.
The biggest consequence of this modular architecture: the storage management layer will NOT deal with what's inside the device anymore (VHD, raw, whatever). It's entirely delegated to the physical storage itself, via your "control-plane" plugin. This is a great opportunity to get rid of all the complexity (coalesce, race conditions and so on).
Volume plugins
This can be called the "control-plane" if you prefer. In short, this is where you implement your logic to make all the basic operations like creating a virtual disk, then a snapshot, or remove the disk. This is where you interact directly with the storage. Let me show you a quick example: let's imagine you want to create an LVM volume plugin. The disk creation with VDI.create will use your plugin, which will define VDI.create as an lvcreate command behind the scenes.
This is very flexible, since you could write any kind of plugin using any kind of storage format, as you can see in here:
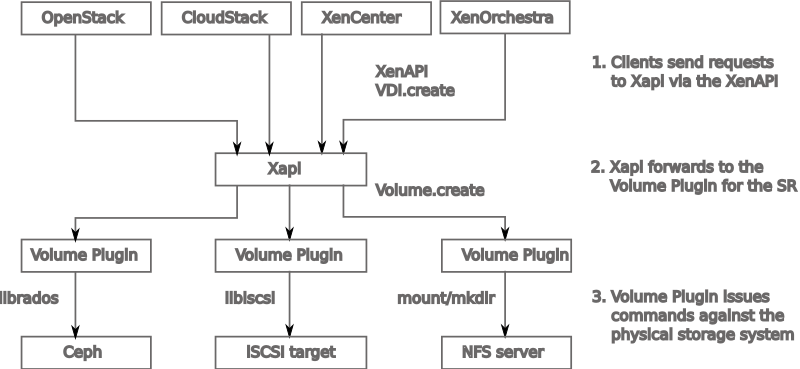
Let's check the previous graph and follow the logic. The client (Xen Orchestra or others) will ask to create a virtual disk by sending the request to XAPI. Since XAPI doesn't know how to manipulate storage directly, storage operations are delegated to the Volume Plugin. Each SR (Storage Repository) is associated with exactly one volume plugin. Each plugin should know how to:
- create volumes
- destroy volumes
- snapshot volumes
- clone volumes
- list the ways in which a volume may be accessed.
Datapath plugins
The datapath is providing the link between your VM and its disks, answering the simple question to the XAPI: "how should I connect this disk to my VM?". There's a reason about not talking about datapath earlier in SMAPIv1 section: it's not configurable. It will use tapdisk in all situations, and write the VHD format on your physical storage and volumes.
As we saw earlier, having VHD everywhere is really convenient but not flexible at all. This format isn't "compatible" with some types of storage, but also limited in various situations. That's why SMAPIv3 is giving you the choice to write you own datapath plugin, and in general finding the best one related to your targeted storage. You could use raw blocks to let the storage do the CoW/compression/dedup for you, VHD/VHDX (if you like!) but also qcow2 and whatnot.
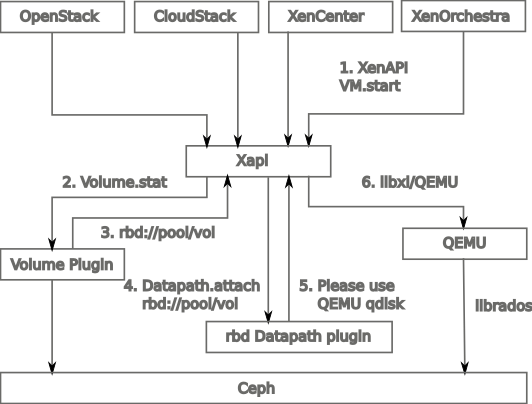
If SMAPIv1 required having VHD everywhere, in that case we just let the storage plugin decide how to plug to your physical storage system, and then the datapath plugin how to store the actual data.
Future challenges
This new architecture is clearly the future. However, it's far from being functional as we speak, with a pretty big amount of work needed to be considered "on par" with SMAPIv1 feature wise. Sadly, Citrix wasn't able to invest resources in SMAPIv3 over the last 3 years. However, it's a great opportunity for us at Vates to push things forward and make it a reality. Let's explore quickly each challenge.
A migration path
You won't be able to get people using your solution in production if you do not have any migration path from the old system to the new one. Even if the objective will be to provide an "offline" way to go to the new system, it's the bare minimum to get adoption. This might pose some challenges, since for now there's absolutely no way to "migrate" a VM disk from SMAPIv1 to SMAPIv3. Obviously, an ideal path would use live storage migration, but this is clearly not a priority as we speak.
Live storage migration
A very nice feature (albeit slow) from SMAPIv1 is the ability to move your VM disk live between various storages, local or not (NAS/SAN). This huge flexibility must be kept for this new storage stack: that's the goal of virtualization after all! But this raises a lot of questions, especially finding the smallest denominator between all your different kind of storage. Something we could use regardless what's underneath. Our first approach will likely be NBD, the Network Block Device protocol.
Unified layer for import/export/backup
In SMAPIv1, we have VHD everywhere, which is very convenient to backup/delta all your disks. Xen Orchestra is indeed storing the VM disks as VHD for delta backups, also allowing file level restore and other very cool features. But with SMAPIv3, everything will be possible in terms of datapath plugin. So there's no way Xen Orchestra will be able to support many formats created in each datapath plugin. That's why we should have a unified layer on top of each storage repository, translating the specific datapath into something common. Back to the previous issue: we need that smallest denominator, and a block based one makes sense. That's why NBD will also be a central piece of this storage stack.
Actual plugins
Obviously, in order to have a real usage of SMAPIv3, we need to develop plugins for each kind of storage. But also test and maintain them. Frankly, volume plugins aren't that hard to write. In my opinion, it will be harder to correctly provide a "support matrix" for each one, since the community will also be able to participate easily (which is great!). This is also an opportunity to think about dealing with NVMeOF and shared block devices, ideally in a thin-pro manner. While also working with storage manufacturers to directly leverage some feature in their API like snapshots and so on, like you can already do with VMware!
The other issue is the new responsibility regarding datapath plugins: since you have the choice, it might be really interesting to compare and benchmark them. Maybe tapdisk will be the best in some situations, maybe not. That's the perk of having choice and flexibility: our responsibility will be to provide you the best plugin for the storage of your choice, in a fully integrated way.

What's next
Since the virtualization market is giving us more and more opportunities (thanks Broadcom!), our new users are also more demanding. And this is great, because this is what drove us to continuously improve our stack. SMAPIv3 is a big chunk of our efforts to massively improve the storage layer: faster VM disks, more flexibility and likely faster backup/restore with more capabilities, like in-line compression & dedup. And it's up to us to write that and build all the glue in XCP-ng and Xen Orchestra so it seems almost functionally identical for you, the end-user.
That's why moving forward on SMAPIv3 is one of our big chunks of work for this year!


