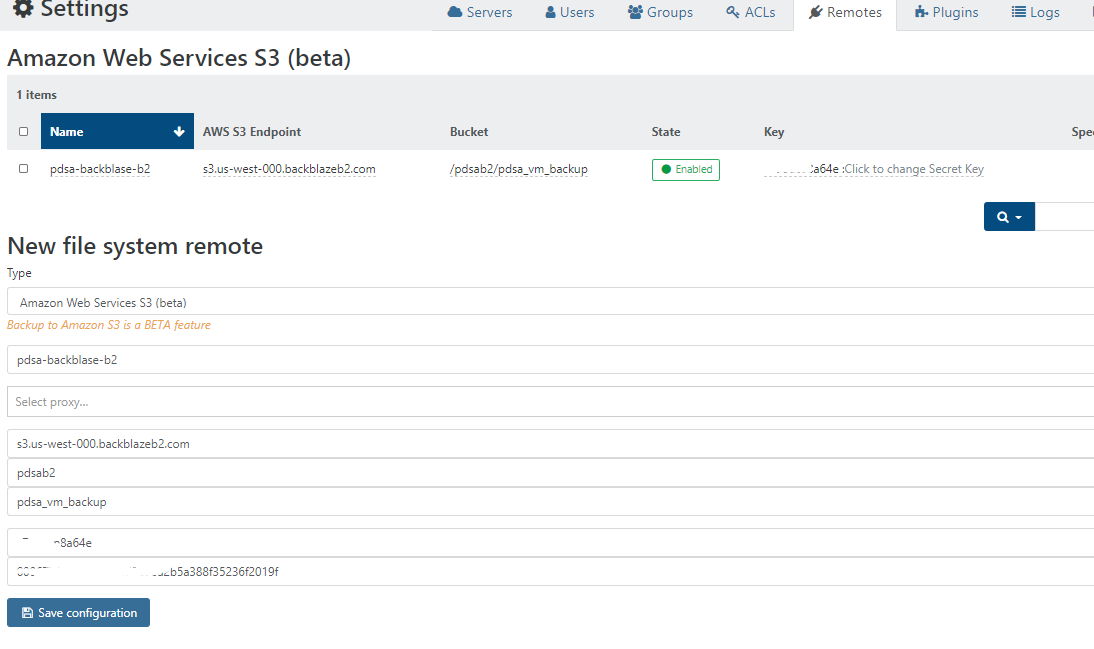
backblaze b2 / amazon s3 as remote in xoa
-
@nraynaud Identical setup, except using B2 not S3.
Initially looking at backing up 3 VMs, each with a single disk sized 100gb, 150gb and 25gb respectively, SR is thin provisioned (ext4), total backup size (compressed) is about 76gb over a 1gbps connection; takes about 90 mins for a clean backup.
Individually they back up fine, as a group they don't. (In total have about 1.2tb of VMs to back up but not trying for that one just yet).
-
Footnote to this - I have just tried to back up 20 small VMs and they all backed up fine; seems to be a function of VM size?
-
@shorian yes, VM size would make sense as a limit, I'll try to run with less memory.
-
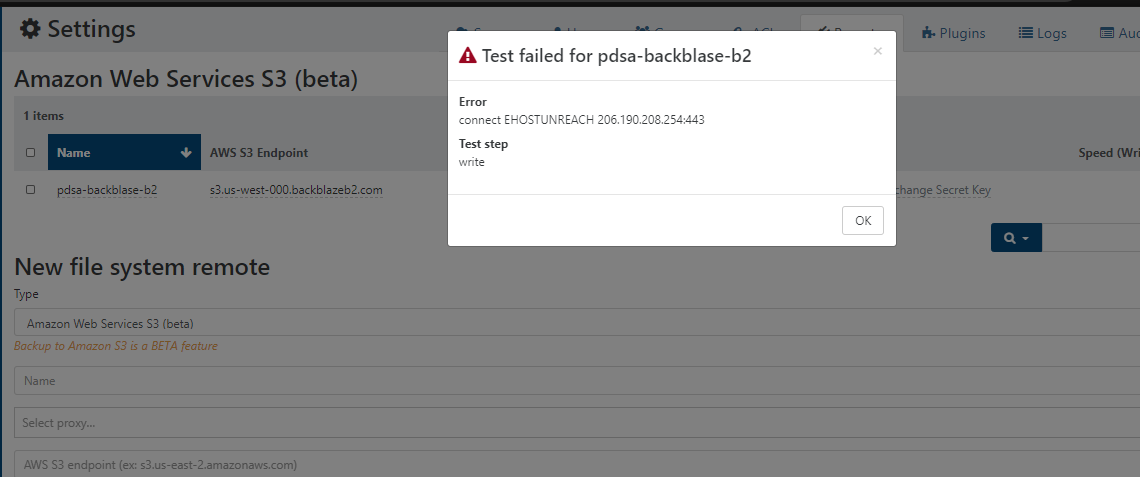
@nraynaud I've been playing about with the larger VMs. It may be coincidence, but if I clear out the target (B2), then the backup seems to work ok with the XO that has 16gb mem. However, the second time the same back up is run, the larger machines fail with errors like the following:
Error calling AWS.S3.upload: class java.net.SocketTimeoutException - Read timed out (https://pod-xxx.backblaze.com/bz_internal/upload_part) after 324446 ms.I'll run some tests over the course of the next day or so to see if the above is 100% repeatable or a coincidence...
-
@shorian thank you for your help.
-
@nraynaud Good of you to say; we have a common end goal, and I'm very grateful for your development efforts that are somewhat more useful than mine!
Ok, quick update - I left the backup process running for the larger VMs to see what happened, and somehow the issue seems to flush through? After clearing out the target (Backblaze), the 3 VMs back up fine first time around, the second backup failed with two VMs not backing up but the third went through successfully, then on the second backup only one failed, and now they're all backing up fine. I then had 3 full backups in a row go through cleanly using the XO with 16gb memory and your code from the new master.
I've then cleared down the target, repeated the above, and had the exact same outcome. First pass, all 3 back up, second pass only 1 backs up, third pass 2 back up, third, fourth and fifth all 3 back up fine. Go figure.
Clearly there's something not quite right, but it seems to flush through in time - which is unusual for a technical issue
")
-
@shorian it's been a bit of time, would you mind updating your xen-orchestra and re-trying the bug byt starting a backup with low node.js memory please ?
I have not changed anything, but I'm hopping you had a problem of cached code last time.
-
@nraynaud Afraid re-occurs - it's size of VM dependent; small VMs go through fine, larger VMs as above.
- xo-server 5.74.1
- xo-web 5.77.0
-
@shorian Thank you very much, I'll dig deeper.
-
I just had a
getaddrinfo EAI_AGAINerror after 3h when trying a big backup towards AWS S3. According to stack overflow, it's generally a timeout on a DNS query. That seems close to your timeout error on the server side. I guess the immediate hypothesis is that the network side of XOA VM is choking on things.In my last change I added support for keepalive in the AWS library, I will look in this direction.
-
@shorian I forget if you're building from sources, would you mind trying this code with a small amount of memory ? https://github.com/vatesfr/xen-orchestra/pull/5579 ?
I removed the keepalive in there.
-
@nraynaud superb! I can’t get into this until tomorrow evening but will be on it as soon as I can. Bear with....
-
@nraynaud Ok, so far so good; haven't had a timeout yet. However the backups are reported as being much much smaller ; overall cumulative size has dropped from over 20gb to under 5gb, which would avoid the problem in any case.
There are no changes to the settings (zstd, normal snapshot without memory), all I can think of is that maybe there were a lot of resends resulting in the large data size being reported within XO, but unless I've picked up a much improved algorithm by building that commit compared with the released branch, I'm a little confused.
I will take a look at the size of the actual backups as held on the remote (Backblaze B2) compared with the reported size in XO to see if I can substantiate the above paragraph.
Meanwhile, I'll keep running backups to soak test it but so far we're looking good!
-
@shorian Just a point, don't forget to test your restoration as well.
Making a backup is only half of having working backups.
-
@dustinb Concur 100%; my current focus is on confirming the error doesn't reoccur and understanding the change in what I'm seeing compared with previous backups, before this goes into production I 100% agree it should be tested for restores. I shall do so myself once I've got confidence that the symptom has been resolved.
-
@nraynaud Unfortunately after a good start I'm now seeing AWS.S3.upload socket hang up errors:
"message": "Error calling AWS.S3.upload: socket hang up", "name": "Error", "stack": "Error: Error calling AWS.S3.upload: socket hang up\n at rethrow (/opt/xo/xo-builds/xen-orchestra-202102171611/node_modules/@sullux/aws-sdk/webpack:/lib/proxy.js:114:1)\n at tryCatcher (/opt/xo/xo-builds/xen-orchestra-202102171611/node_modules/bluebird/js/release/util.js:16:23)\n at Promise._settlePromiseFromHandler (/opt/xo/xo-builds/xen-orchestra-202102171611/node_modules/bluebird/js/release/promise.js:547:31)\n at Promise._settlePromise (/opt/xo/xo-builds/xen-orchestra-202102171611/node_modules/bluebird/js/release/promise.js:604:18)\n at Promise._settlePromise0 (/opt/xo/xo-builds/xen-orchestra-202102171611/node_modules/bluebird/js/release/promise.js:649:10)\n at Promise._settlePromises (/opt/xo/xo-builds/xen-orchestra-202102171611/node_modules/bluebird/js/release/promise.js:725:18)\n at _drainQueueStep (/opt/xo/xo-builds/xen-orchestra-202102171611/node_modules/bluebird/js/release/async.js:93:12)\n at _drainQueue (/opt/xo/xo-builds/xen-orchestra-202102171611/node_modules/bluebird/js/release/async.js:86:9)\n at Async._drainQueues (/opt/xo/xo-builds/xen-orchestra-202102171611/node_modules/bluebird/js/release/async.js:102:5)\n at Immediate.Async.drainQueues [as _onImmediate] (/opt/xo/xo-builds/xen-orchestra-202102171611/node_modules/bluebird/js/release/async.js:15:14)\n at processImmediate (internal/timers.js:461:21)" }This is not occurring for all the VMs being uploaded, usually only for one out of the three. The tasks then stays open and runs until the timeout after 3 hours, despite normally taking about 30 minutes for this particular batch.
After 3 successful runs, this has now occurred each time on the following 3 runs. I am going to clear out the target completely and see if that makes any difference. (Note that I am using BackBlaze B2 not AWS.). Let me know if you want me to send you the full log or an extract of SMlog or anything else.
To @DustinB's point above, I have tried one restore and it came up fine, but please don't consider this a full and comprehensive test.
-
Thank you all. I would have never guessed that uploading a file over http would be this hard. I'll dig deeper.
-
@nraynaud Bizarre isn't it; I'm so very grateful for your efforts.
Some more news - it seems that one big challenge is around concurrency - things improve dramatically if concurrency is set to 1. As soon as something else is running in parallel, we run into the socket failures. I'm expanding things to try your change on another box to see if the outcomes are different - but in summary what I'm seeing so far:
- Concurrency = 1 - works fine first time, fails occasionally (20% of the time?) thereafter
- Concurrency > 1 - almost impossible to get it to run, but sometimes one or two VMs backup ok but not enough to be predictable and never the entire group
- Anything fails - impossible to get a clean run again until the S3 target has been cleaned entirely
So it appears that somewhere there perhaps is a lock occurring when more than one stream is running, and additionally there's some kind of conflict when things have terminated prematurely and the target is therefore not in its expected state on the next run.
-
@shorian thanks, I'm a bit lost, I will read on the node.js Agent class.
-
@nraynaud Removing any concurrency seems to be effective; certainly a substantial improvement upon the original backup prior to your amendments.
We have managed to get things to run pretty much every time now, by running with concurrency set to '1' and being careful on the timing to ensure no other backups accidentally run in parallel.
Have checked a couple of restores and they seem to be ok too.
Only thing I would highlight is that now I am not getting the failures, I cannot tell if the issue on the remote when recovering from a partial/failed backup is resolved. I guess this needs me to pull a plug on the network whilst back up is running but I would need to test this on a different machine in the lab rather than where we're running at the moment.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login