Backup failed with "Body Timeout Error"
-
Most of the backup occur with any error but I have a backup that keeps failing with "Body Timeout Error" it says it is dying at the four hour mark.
It is backingup up to two NFS boxes. Liek I said above, it works fine for most of the other VMs however one other one does this every once in a while.
Backup running on Xen Orchestra, commit f18b0
Any ideas?
Thanks!The log file is as follows:
{
"data": {
"mode": "full",
"reportWhen": "failure"
},
"id": "1740449460003",
"jobId": "2cc39019-5201-43f8-ad8a-d13870e948be",
"jobName": "Exchange-2025",
"message": "backup",
"scheduleId": "1f01cbda-bae3-4a60-a29c-4d88b79a38d2",
"start": 1740449460003,
"status": "failure",
"infos": [
{
"data": {
"vms": [
"558c3009-1e8d-b1e4-3252-9cf3915d1fe4"
]
},
"message": "vms"
}
],
"tasks": [
{
"data": {
"type": "VM",
"id": "558c3009-1e8d-b1e4-3252-9cf3915d1fe4",
"name_label": "VM1"
},
"id": "1740449463052",
"message": "backup VM",
"start": 1740449463052,
"status": "failure",
"tasks": [
{
"id": "1740449472998",
"message": "snapshot",
"start": 1740449472998,
"status": "success",
"end": 1740449481725,
"result": "d73124a9-d08c-4623-f28c-7503fcef9260"
},
{
"data": {
"id": "0d6da7ba-fde1-4b37-927b-b56c61ce8e59",
"type": "remote",
"isFull": true
},
"id": "1740449483456",
"message": "export",
"start": 1740449483456,
"status": "failure",
"tasks": [
{
"id": "1740449483464",
"message": "transfer",
"start": 1740449483464,
"status": "failure",
"end": 1740462845094,
"result": {
"name": "BodyTimeoutError",
"code": "UND_ERR_BODY_TIMEOUT",
"message": "Body Timeout Error",
"stack": "BodyTimeoutError: Body Timeout Error\n at FastTimer.onParserTimeout [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/dispatcher/client-h1.js:646:28)\n at Timeout.onTick [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/util/timers.js:162:13)\n at listOnTimeout (node:internal/timers:581:17)\n at process.processTimers (node:internal/timers:519:7)"
}
}
],
"end": 1740462845094,
"result": {
"name": "BodyTimeoutError",
"code": "UND_ERR_BODY_TIMEOUT",
"message": "Body Timeout Error",
"stack": "BodyTimeoutError: Body Timeout Error\n at FastTimer.onParserTimeout [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/dispatcher/client-h1.js:646:28)\n at Timeout.onTick [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/util/timers.js:162:13)\n at listOnTimeout (node:internal/timers:581:17)\n at process.processTimers (node:internal/timers:519:7)"
}
},
{
"data": {
"id": "656f82d9-5d68-4e26-a75d-b57b4cb17d5e",
"type": "remote",
"isFull": true
},
"id": "1740449483457",
"message": "export",
"start": 1740449483457,
"status": "failure",
"tasks": [
{
"id": "1740449483469",
"message": "transfer",
"start": 1740449483469,
"status": "failure",
"end": 1740462860953,
"result": {
"name": "BodyTimeoutError",
"code": "UND_ERR_BODY_TIMEOUT",
"message": "Body Timeout Error",
"stack": "BodyTimeoutError: Body Timeout Error\n at FastTimer.onParserTimeout [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/dispatcher/client-h1.js:646:28)\n at Timeout.onTick [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/util/timers.js:162:13)\n at listOnTimeout (node:internal/timers:581:17)\n at process.processTimers (node:internal/timers:519:7)"
}
}
],
"end": 1740462860953,
"result": {
"name": "BodyTimeoutError",
"code": "UND_ERR_BODY_TIMEOUT",
"message": "Body Timeout Error",
"stack": "BodyTimeoutError: Body Timeout Error\n at FastTimer.onParserTimeout [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/dispatcher/client-h1.js:646:28)\n at Timeout.onTick [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/util/timers.js:162:13)\n at listOnTimeout (node:internal/timers:581:17)\n at process.processTimers (node:internal/timers:519:7)"
}
},
{
"id": "1740463648921",
"message": "clean-vm",
"start": 1740463648921,
"status": "success",
"warnings": [
{
"data": {
"path": "/backup-storage/558c3009-1e8d-b1e4-3252-9cf3915d1fe4/.20250224T232125Z.xva"
},
"message": "unused XVA"
}
],
"end": 1740463649103,
"result": {
"merge": false
}
},
{
"id": "1740463649144",
"message": "clean-vm",
"start": 1740463649144,
"status": "success",
"warnings": [
{
"data": {
"path": "/backup-storage/558c3009-1e8d-b1e4-3252-9cf3915d1fe4/.20250224T232125Z.xva"
},
"message": "unused XVA"
}
],
"end": 1740463651524,
"result": {
"merge": false
}
}
],
"end": 1740463651532,
"result": {
"errors": [
{
"name": "BodyTimeoutError",
"code": "UND_ERR_BODY_TIMEOUT",
"message": "Body Timeout Error",
"stack": "BodyTimeoutError: Body Timeout Error\n at FastTimer.onParserTimeout [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/dispatcher/client-h1.js:646:28)\n at Timeout.onTick [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/util/timers.js:162:13)\n at listOnTimeout (node:internal/timers:581:17)\n at process.processTimers (node:internal/timers:519:7)"
},
{
"name": "BodyTimeoutError",
"code": "UND_ERR_BODY_TIMEOUT",
"message": "Body Timeout Error",
"stack": "BodyTimeoutError: Body Timeout Error\n at FastTimer.onParserTimeout [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/dispatcher/client-h1.js:646:28)\n at Timeout.onTick [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502241838/node_modules/undici/lib/util/timers.js:162:13)\n at listOnTimeout (node:internal/timers:581:17)\n at process.processTimers (node:internal/timers:519:7)"
}
],
"message": "all targets have failed, step: writer.run()",
"name": "Error",
"stack": "Error: all targets have failed, step: writer.run()\n at FullXapiVmBackupRunner._callWriters (file:///opt/xo/xo-builds/xen-orchestra-202502241838/@xen-orchestra/backups/_runners/_vmRunners/_Abstract.mjs:64:13)\n at async FullXapiVmBackupRunner._copy (file:///opt/xo/xo-builds/xen-orchestra-202502241838/@xen-orchestra/backups/_runners/_vmRunners/FullXapi.mjs:55:5)\n at async FullXapiVmBackupRunner.run (file:///opt/xo/xo-builds/xen-orchestra-202502241838/@xen-orchestra/backups/_runners/_vmRunners/_AbstractXapi.mjs:396:9)\n at async file:///opt/xo/xo-builds/xen-orchestra-202502241838/@xen-orchestra/backups/_runners/VmsXapi.mjs:166:38"
}
}
],
"end": 1740463651533
} -
@archw can you share how large this VM's virtual disks are? It could be that the backup is timing out because of how long that specific VM/disk is taking to complete.
You mentioned NFS targets for the backup remote: what network throughput and NFS storage throughput do you have?
As a very rough indicator, I backup around 50GB of VMs, stored on host NVMe storage repository, over 2.5GbE to a TrueNAS NFS target and that takes around 10-12minutes.
Do you have a timeout set in the XO backup job's config? There is a field for that. If that's empty, then perhaps Vates can confirm if there's a default 4-hour timeout built into XO's code (sorry I can't check myself, I'm not code- or API-savvy).
-
It also backs up two very similar VM's so I went to the status of their last backup and they show this:
VM1
Duration: 8 hours
Size: 1.1 TiB
Speed: 42.2 MiB/sVM2
Duration: 5 hours
Size: 676.8 GiB
Speed: 41.29 MiB/sIts a 10GB connection but the storage media is an NFS share made from 7200 RPM SATA drives (I'm jealous of your nvme!).
I dont have a time out set but for the heck of it I just set one at 8 hours. Also, I have the backup set to go to two NFS shares. I also just changed it to only go to one and just started it. If that fails, I'll change to the other and see what happens.
-
@archw One suggestion would be to break your backup jobs down into smaller units.
For example, set your existing backup jobs to write to only one of the two NFS remotes. This could reduce runtime and hopefully avoid any timeouts.
Then setup 'mirror' jobs to copy the backups from the first remote to the second remote. This way, your backup job can hopefully complete sooner, and you can optimise the traffic flow between hosts & remotes.
Example of the Mirror backup job below (please note that if you use incremental backups, you'll likely need a job to mirror Full backups, and another job to mirror Incremental backups). I don't use this feature myself, as my homelab isn't critical.
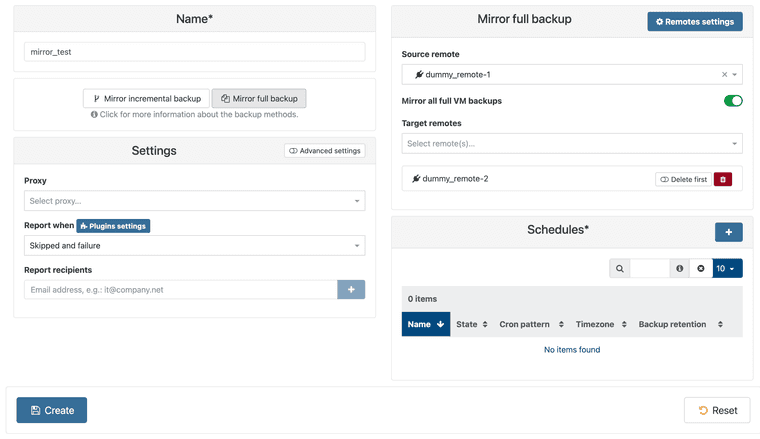
-
@archw
I didn't even know that was a thing....thanks!
Question:Lets say dummy_remote-1 was where I write data and the mirror job copies the data from dummy_remote-1 to dummy_remote-2.
-
What happens if the backup to dummy_remote-1 fails part of the way through the backup? I don't know what gets left behind in a partial backup but I assume its a bunch of nothingness/worthless data?? Would the mirror copy the failed data over the good data on dummy_remote-2
-
What happens if the backup to dummy_remote-1 got wiped out by a bad actor (erased)? Would the mirror copy the zerored out data over the good data on dummy_remote-2
-
-
@archw That’s a good question - unfortunately I don’t know the answers as I’ve not used this mirror job before, and the XO documentation doesn’t explain it in a lot of technical detail. But definitely have a read at mirror backup doc
I’ll try setup a mirror job on the weekend to test how data flows, and how failed jobs would impact. I assume all data will flow via XO appliance and NFS remotes. Which is good, as it removes load from XCP hosts and their NICs (assuming XO appliance is installed outside that pool)
The positive aspect is that, even if the mirror fails AND somehow corrupts the remote-2 copy, you’ve still got the remote-1 healthy copy, and the actual source VM (so 2 healthy copies of your data).
Retrying a mirror job is much easier and lower impact than rerunning the actual VM backup

-
@archw Actually I think XO will clean up a failed backup - I’ve had a few failures but haven’t noticed any ‘junk’ backup clutter on my remote.
-
Update:
It’s weird:
• There are three VM’s on this host. The backup works with two but not with the third. It does with the “Body Timeout Error” error.
• Two of the VM’s are almost identical (same drive sizes). The only difference is that one was set up as “Other install media” (came over from esxi) and the one that fails was set up using the “Windows Server 2022” template.
• I normally backup to multiple NFS servers so I changed to try one at a time; both failed.
• After watching it do the backup too many times to thing, I found that, at about the 95% stage, the snapshot stops writing to the NFS share.
• About that time, the file /var/log/xensource.log records this information:
o Feb 26 09:43:33 HOST1 xapi: [error||19977 HTTPS 192.168.1.5->:::80|[XO] VM export R:c14f4c4c1c4c|xapi_compression] nice failed to compress: exit code 70
o Feb 26 09:43:33 HOST1 xapi: [ warn||19977 HTTPS 192.168.1.5->:::80|[XO] VM export R:c14f4c4c1c4c|pervasiveext] finally: Error while running cleanup after failure of main function: Failure("nice failed to compress: exit code 70")
o Feb 26 09:43:33 HOST1 xapi: [debug||922 |xapi events D:d21ea5c4dd9a|xenops] Event on VM fbcbd709-a9d9-4cc7-80de-90185a74eba4; resident_here = true
o Feb 26 09:43:33 HOST1 xapi: [debug||922 |xapi events D:d21ea5c4dd9a|dummytaskhelper] task timeboxed_rpc D:a08ebc674b6d created by task D:d21ea5c4dd9a
o Feb 26 09:43:33 HOST1 xapi: [debug||922 |timeboxed_rpc D:a08ebc674b6d|xmlrpc_client] stunnel pid: 339060 (cached) connected to 192.168.1.6:443
o Feb 26 09:43:33 HOST1 xapi: [debug||19977 HTTPS 192.168.1.5->:::80|[XO] VM export R:c14f4c4c1c4c|xmlrpc_client] stunnel pid: 296483 (cached) connected to 192.168.1.6:443
o Feb 26 09:43:33 HOST1 xapi: [error||19977 :::80|VM.export D:c62fe7a2b4f2|backtrace] [XO] VM export R:c14f4c4c1c4c failed with exception Server_error(CLIENT_ERROR, [ INTERNAL_ERROR: [ Unix.Unix_error(Unix.EPIPE, "write", "") ] ])
o Feb 26 09:43:33 HOST1 xapi: [error||19977 :::80|VM.export D:c62fe7a2b4f2|backtrace] Raised Server_error(CLIENT_ERROR, [ INTERNAL_ERROR: [ Unix.Unix_error(Unix.EPIPE, "write", "") ] ])
• I have no idea if it means anything but the “failed to compress” made me try something. I change “compression” from “Zstd” to “disabled” and that time it worked.Here are my results:
- Regular backup to TrueNas, “compression” set to “Zstd”: backup fails.
- Regular backup to TrueNas, “compression” set to “disabled”: backup is successful.
- Regular backup to vanilla Ubuntu test VM, “compression” set to “Zstd”: backup is successful.
- Delta backup to TrueNas: backup is successful.
Sooooo…the $64,000 question is why doesn’t it work on that one VM when compression is on and it a TrueNas box?
-
A archw referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login