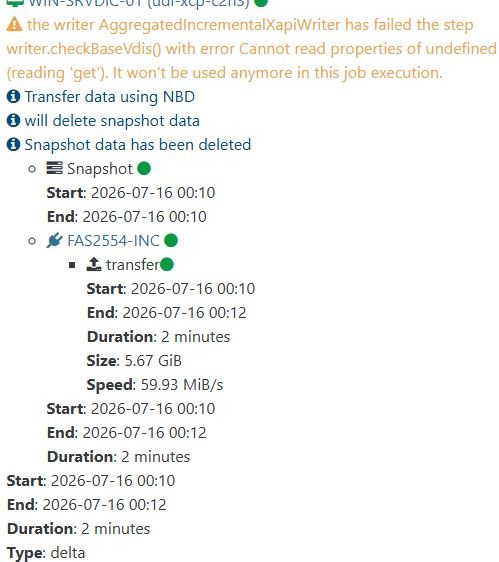
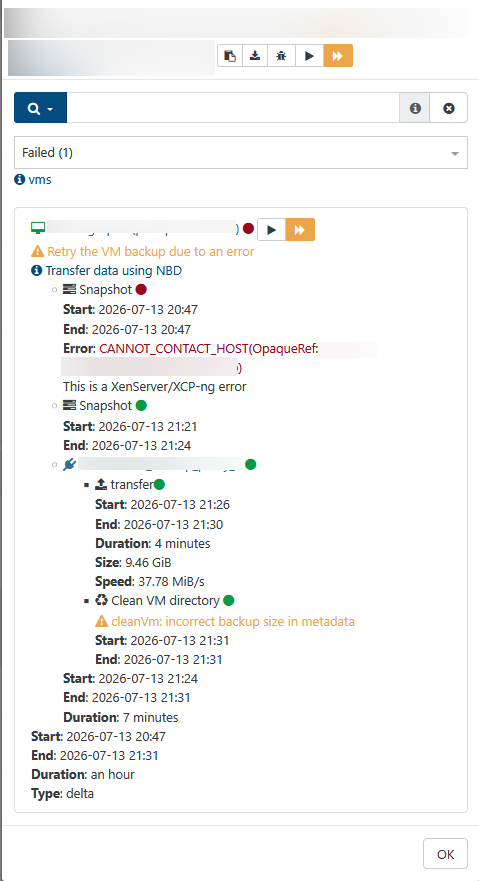
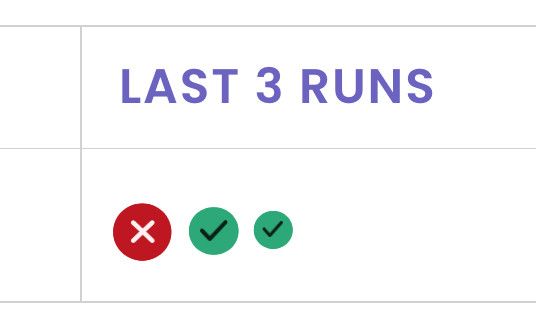
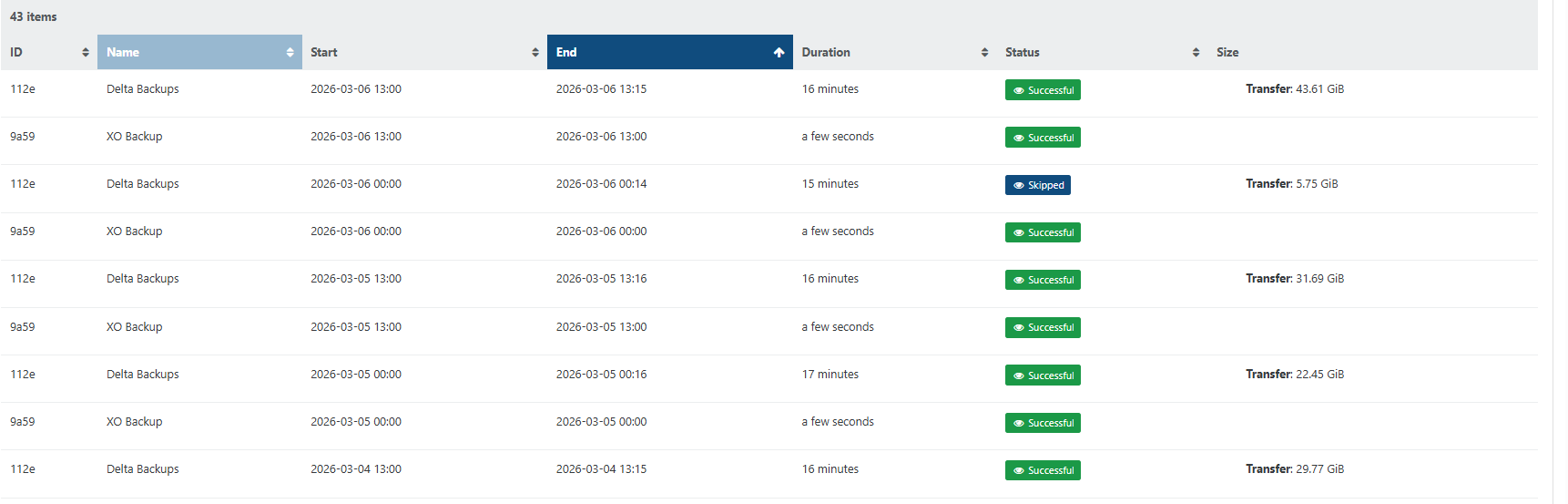
Good news that it sorted itself out. Both changes went in at once and the next run came back clean on the ADDS VMs too, so I don't think there's anything left to pin down here, and I'd rather say that than invent an explanation after the fact.
Your question about the snapshot modes was the useful thing to come out of this thread.
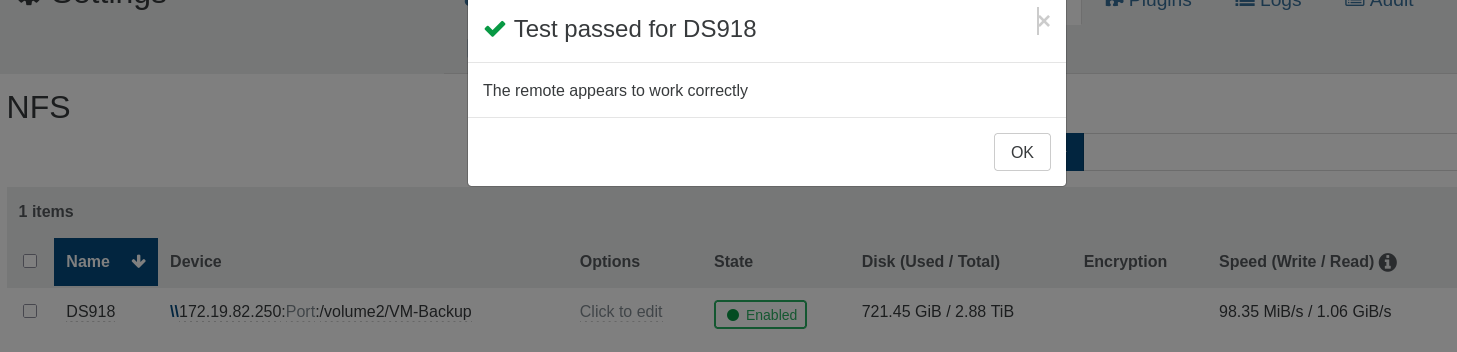
I went looking, they genuinely aren't documented anywhere, and that's written up on our side now
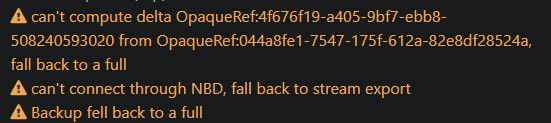
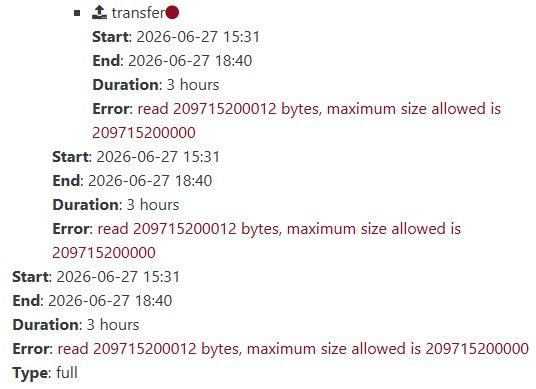
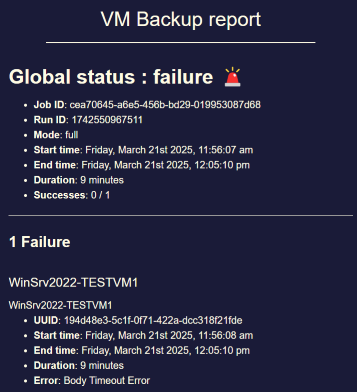
If the fall back to a full ever comes back on the ADDS VMs specifically, that would deserve its own thread with the SMlog output @tjkreidl asked for, since nobody got to look at that part.