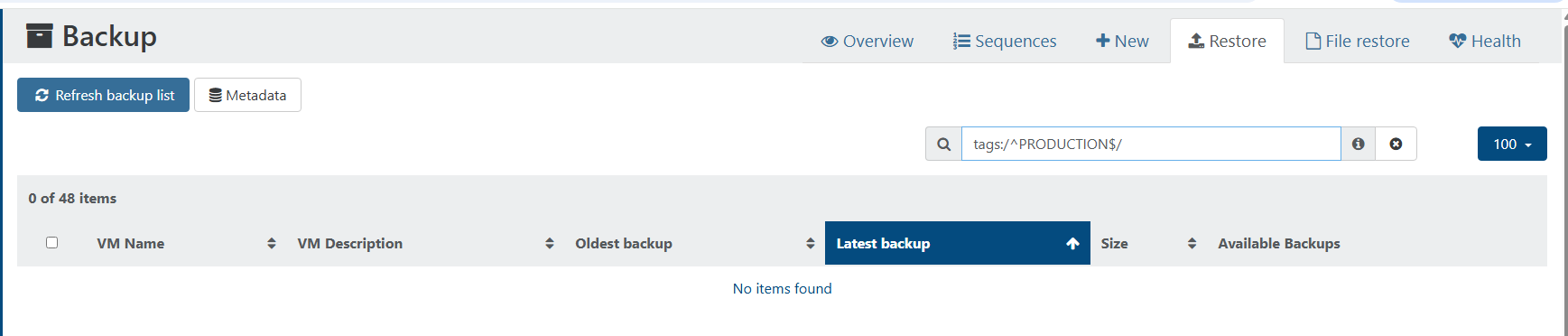
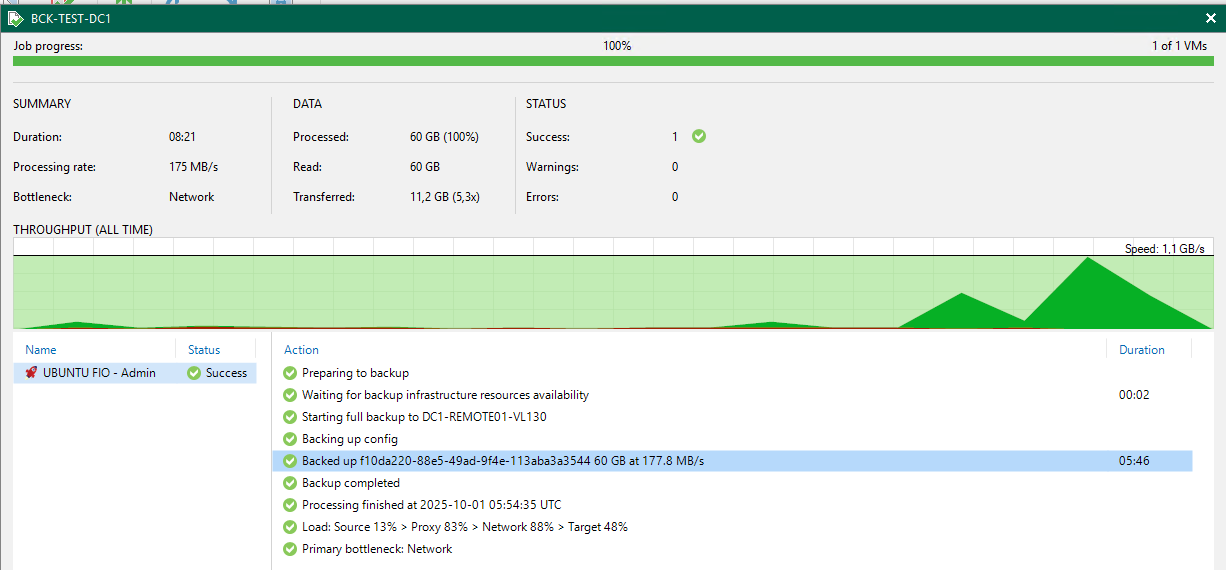
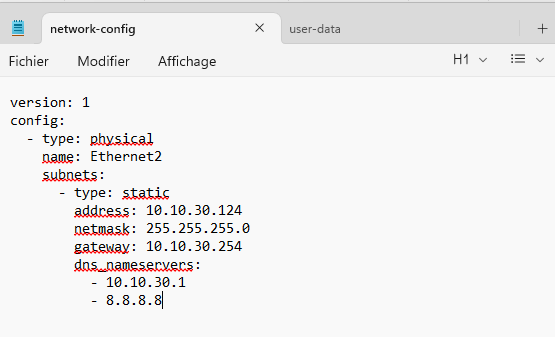
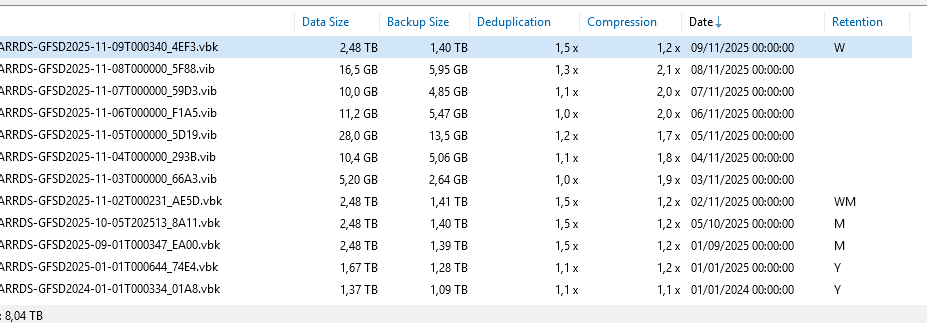
Hey all,
We are proud of our new setup, full XCPng hosting solution we racked in a datacenter today.
This is the production node, tomorrow i'll post the replica node !
XCPng 8.3, HPE hardware obviously, and we are preparing full automation of clients by API (from switch vlans to firewall public IP, and automatic VM deployment).
This needs a sticker "Vates Inside" ") #vent
#vent