@Tristis-Oris could you not temporarly change the CR VM Mac address on the VIF ?
problem would be solved ?
P
Offline
Posts
-
RE: DUPLICATE_MAC_SEED
-
RE: 14 VMs Running: After Pool patch update - message states I need to restart to take effect?
@acebmxer the two hosts are Masters, probably each in a pool.
If I do the reboot, will XCP-ng save the State and Restore or Shutdown the VMs? I was hoping it would save the State and Restore like you can with KVM.All VMs with AUTO START enabled will start. even if you have some manually shutdown. the host do not care of previous running type, when rebooting and going online, it will start VMs qith autostart enabled (and pool enabled)
-
RE: Host crash during backup
facepalm situation ! thanks for the feedback

-
RE: Tesco and XCP-ng
@john.c yeah i'm assuming the 40K is probably VMs, so better density of physical servers
anyway, big players... -
RE: Tesco and XCP-ng
@olivierlambert just for fun of thought.
How could Vates stack handle 40K servers farm ?I suppose TESCO have multiple in house datacenters, and not 40K servers in one place but anyway...
Can this tech handle 40K servers in one XOA with attached sites by XO Proxies ?way above recommend limits isnt it ?
don't remember the max number of servers per pool -
RE: Tesco and XCP-ng
the choice appears to be incompatible with both Veeam and Zerto
thought the same XD
40K servers would be a good user story -
RE: XCP-ng 8.3 updates announcements and testing
@manilx yup, same here
we evacuate & roll patch manually because RPU is inconsistent in achieving a full pool update nowadaysmaximum hosts in pools are 3, so it is still easy to process manually
thoses with 5-6+ hosts must be more painful -
RE: XCP-ng 8.3 updates announcements and testing
@marcoi perhaps a restart toolstack would correct the phantom task ?
but at the end of patching of the master a restart toolstack should have happened already, automatically... -
RE: broken backup in XOA 6.5 ? orphan VDI Directory, not referenced by any backup
@Bastien-Nollet Sorry, I had to revert back to 6.3.3, and didnt save the logs...
but as far as I remember, it was not an UI issue, even in the logs it didnt put any transfer informations@pierrebrunet i'll report back as soon as we test 6.5.1 on this same client infrastructure
-
RE: CBR start operation is blocked
@Milenko if this is a definitive migration pathway for you, you can force start the replica VM, no problem, you can even delete the replica snapshot.
Just disable the job at source, it will create a new replica VM otherwiseif it is just a test boot of the replica, fast clone it, and start the fast clone (beware of double ip addressing while doing so... source VM should be halted, or replica clone should be started without network)
-
RE: broken backup in XOA 6.5 ? orphan VDI Directory, not referenced by any backup
@acebmxer had a combo error on some VMs "fell back to full" and "not referenced by any backup" but no tranfer size either.
can't screenshot it anymore, I did a rollback to XOA 6.3 for the time being, snapshoted just before the upgrade
-
RE: broken backup in XOA 6.5 ? orphan VDI Directory, not referenced by any backup
@acebmxer but you have SIZE and SPEED
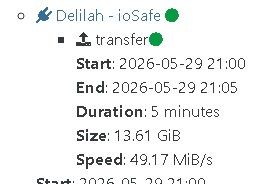
same error but I do not even have these infos.
-
RE: broken backup in XOA 6.5 ? orphan VDI Directory, not referenced by any backup
did a full VM restoration on an "N/D" backup point, was successful
so it seems backup is backuping buuuuut not reporting correct transfer size
halp
")
-
RE: broken backup in XOA 6.5 ? orphan VDI Directory, not referenced by any backup
some VMs do take more than 30 seconds, and do not have the error
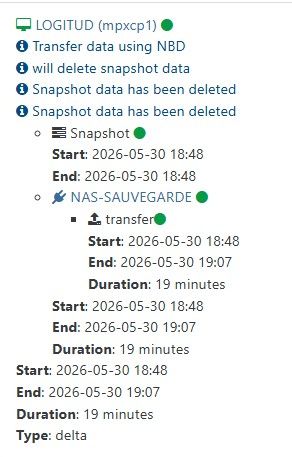
still no transfer sizeand still no apparent size
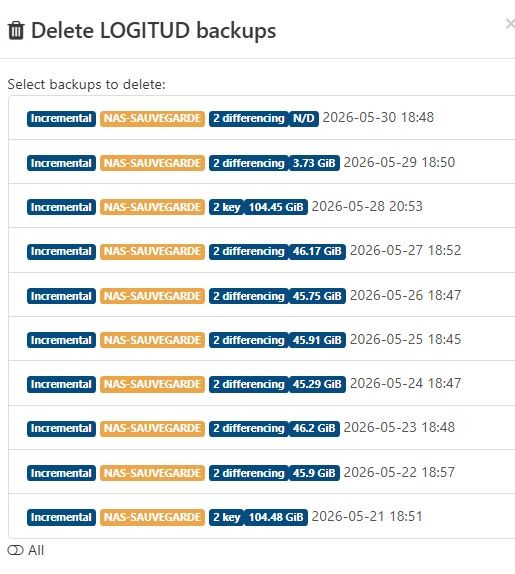
is the XO backup working ?!
-
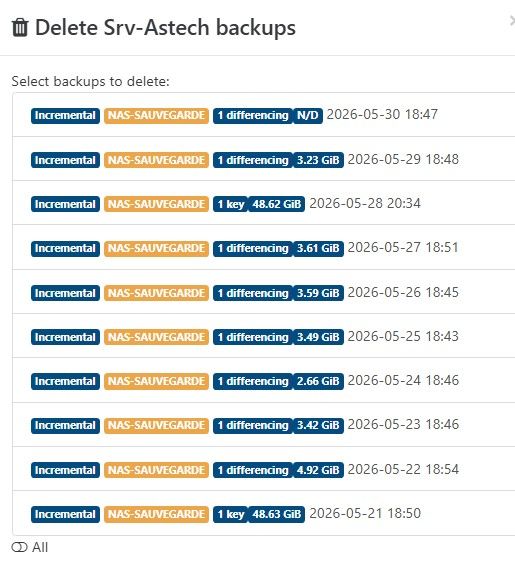
broken backup in XOA 6.5 ? orphan VDI Directory, not referenced by any backup
Hi,
Today we updated from XOA 6.3.3 to 6.5
XCP is full up to date.Since then, the backups are successful but do not seem to transfer any data ?
Comparison between yesterday and today :
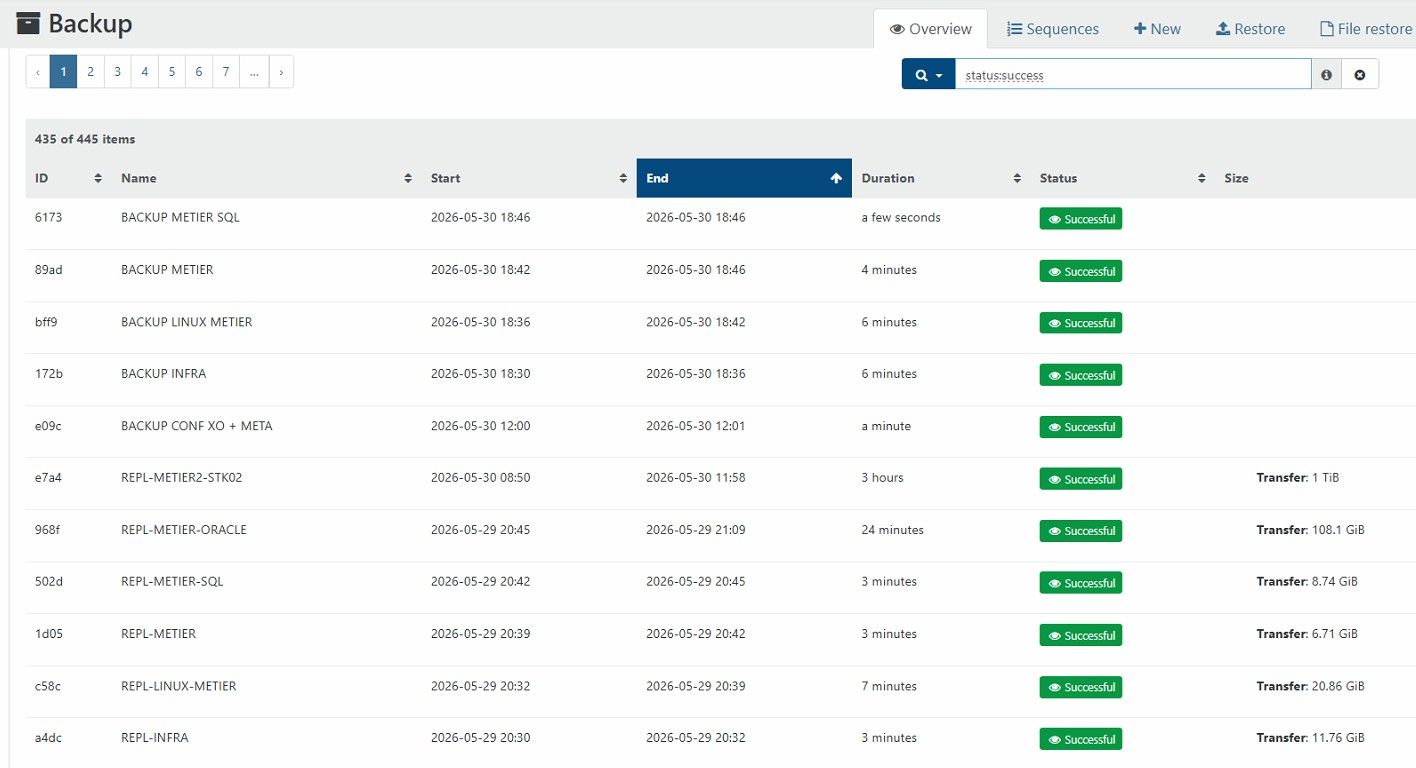
Each job goes like that :
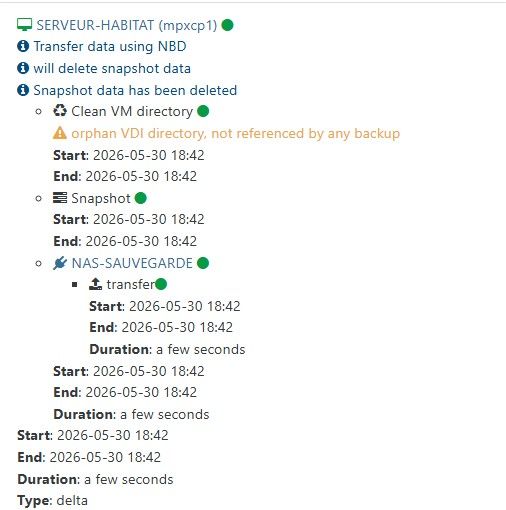

restore point size is N/D !
XOA seems to be working
any idea @florent @bastien-nollet ?
-
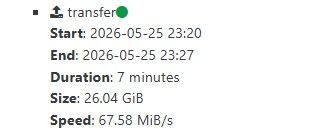
RE: Continuous Replication Speed
@tsukraw I think the bottleneck is indeed the tapdisk and smapiv1.
We have full 10Gb WDM between nominal and DR site, and get the same transfer speeds as you on CR.
-
RE: Attach a Physical HD to a VM?
@nasheayahu Hi, you could passthrough the controller hosting these disks if its independant of the disks hosting the XCP itself I guess...
but not really recommended ? perhaps someone has another solution
-
RE: Slow Backups | XOA Performance Test – Upgrading from 2 vCPU to 4 vCPU / 8GB RAM
@LoTus111 nice, but could be better
you're missing the additionnal step in the TIPS section here :
https://docs.xen-orchestra.com/xo5/troubleshooting#memoryupgrading XOA to 8Gb is not enough, you have to tell xo services to be able to use this additionnal RAM.
-
RE: Tag-Based Automation: Manage VM CPU Priority via assigned tag.
@johnnezero this could be a plugin in XOA !
