@olivierlambert done.
K
Offline
-
Suggestion: Check if requirements for backups are met before shutting down VMs...
Hi,
one of our VMs was in a stopped state this morning because our daily delta backup (with offline snapshot, 4 VMs in total in the backup job) had failed with error "NOT_SUPPORTED_DURING_UPGRADE()". The other 3 VMs were up and running.
I updated the pool master yesterday and rebooted, but I did not update the second server on which the stopped VM was running. The VM had this server assigned as a home server, too.
This happend:
- Snapshots failed for all 4 VMs, which is expected because of the update state.
- 3 VMs started up again on the pool master.
- 1 VM could not be started because it is not possible to start a VM when the host has not been updated. Is this correct?
Perhaps the update logic can be enhanced by checking some things before the backup job shuts down a VM. The key questions woud be:
- Is the backup target available?
- Can the VM be started again after the offline snapshot?
-
RE: delta backups with offline snapshot: VMs do not start after snapshot, they start after transfer is done.
@Pilow Yes of course. But I don't really care about keeping the backup chain. I am just getting started with my backups
")
In fact, the snapshots for deltas take too much space on my storage, so I divided the VMs into 2 groups. One with daily delta backups and one with weekly offline full backups which don't need snapshots.
I think there is a way with changed block tracking to use delta backups without snapshots, right? I'll have to look into that.
I'd also like to mirror the VMs to the local storage of a server outside of the pool. This goes to another building, for emergencies. This would also be a combination of weekly full offline backups and daily delta backups. The latter would again require snapshots and it seems it would create 2 snapshots per VM, then. One for the backup job and one for the mirror job.
-
RE: delta backups with offline snapshot: VMs do not start after snapshot, they start after transfer is done.
With new created backup jobs, everything works. Clearly there are some hickups in the GUI when switching between backup modes. Not sure if it is worth fixing with XO6 coming up, though.
-
RE: delta backups with offline snapshot: VMs do not start after snapshot, they start after transfer is done.
@Bastien-Nollet I can't change those options, both are greyed out (locked / disabled).
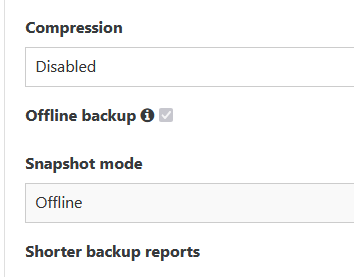
-
RE: delta backups with offline snapshot: VMs do not start after snapshot, they start after transfer is done.
@Bastien-Nollet Hi, there is another issue: When I switch back from "delta backup" to "disaster recovery" or "Backup", the checkbox for "offline backup" and the drop down menu "offline" is greyed out so that it cannot be changed.
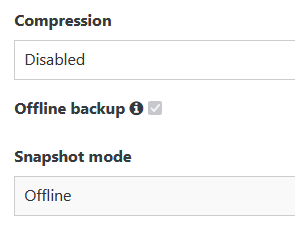
-
RE: delta backups with offline snapshot: VMs do not start after snapshot, they start after transfer is done.
Thanks. I also used "disaster recovery" with the "offline backup" option before.
I also just noticed: Every time I open the backup settings, the email address field is empty.Btw: It is really confusing that it still says "disaster recovery" while the documentation uses other names....
-
RE: delta backups with offline snapshot: VMs do not start after snapshot, they start after transfer is done.
@Bastien-Nollet
I am using delta backups, not full backups. So there is no option called "offline backup".However, I was in fact using "backup" before and had "offline backup" enabled. Maybe this option is still checked, but invisible... I did not create a new backup job, I simply de-selected "full backup" and activated "delta backup".
This is my configuration:
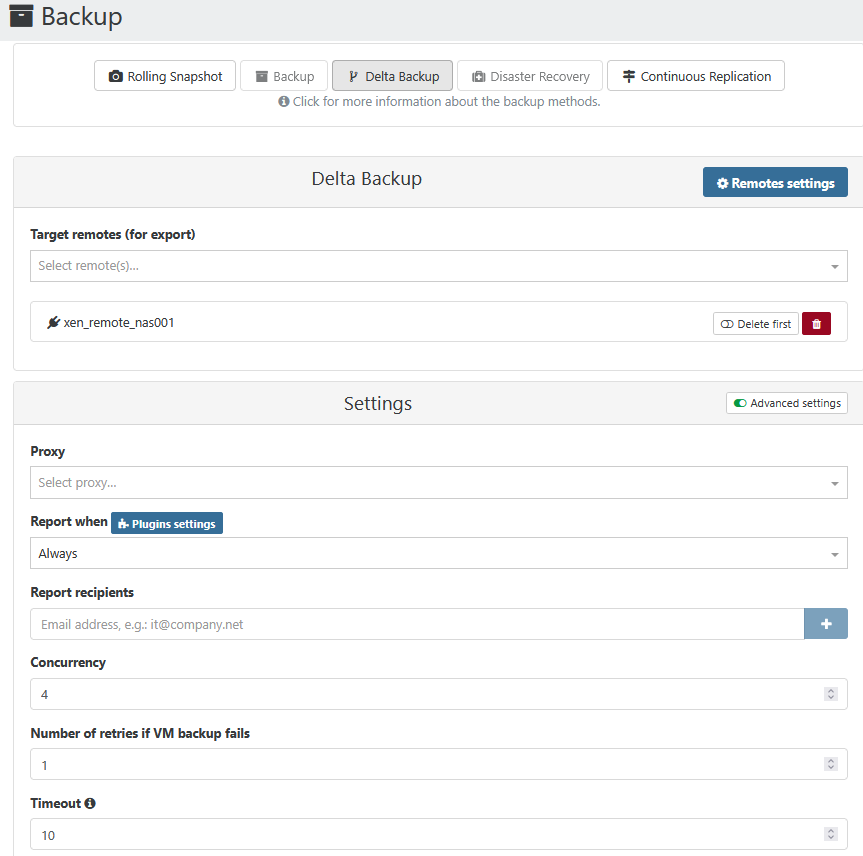
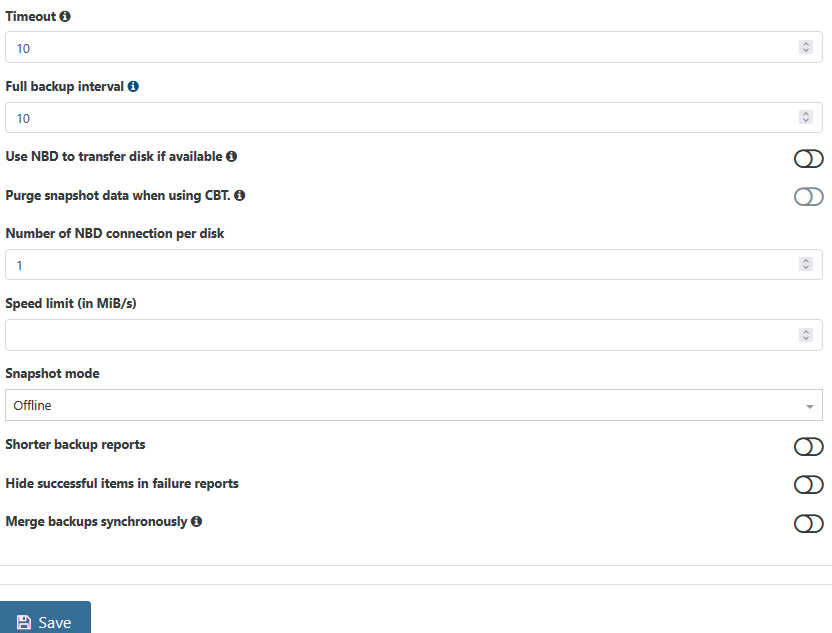
-
delta backups with offline snapshot: VMs do not start after snapshot, they start after transfer is done.
Hi,
I just did delta backups with offline snapshot. There are 6 VMs in this job (smart mode).
It shuts down the VM(s) as expected and takes the snapshot. Then it exports to the remote and then it starts up the respective VM again. Is this a bug? Why does it not start the VM immediately after taking the snapshot? Or can this be caused by a setting?Strange... I habe another job, again offline snapshot. There is only von VM in this job. Here it starts the VM immediately after taking the snapshot....