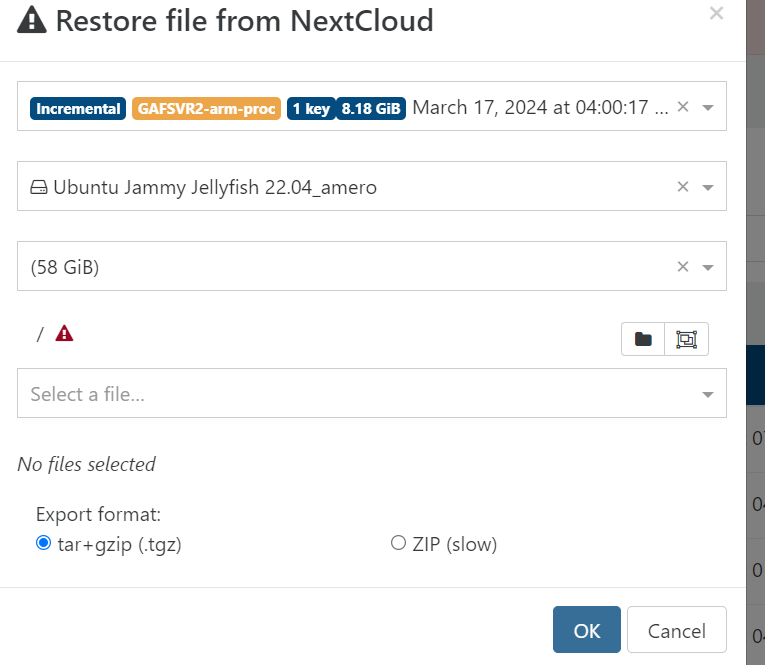
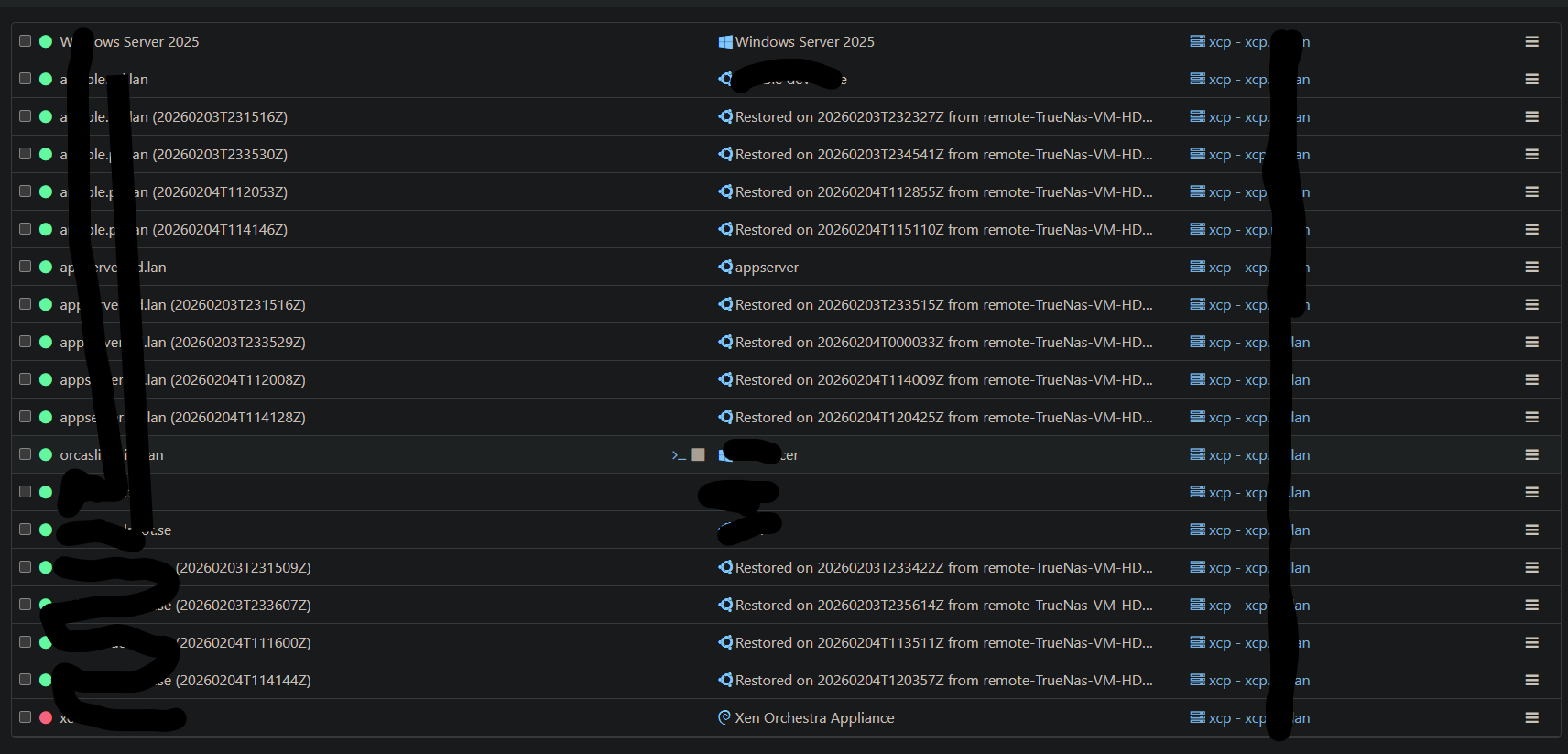
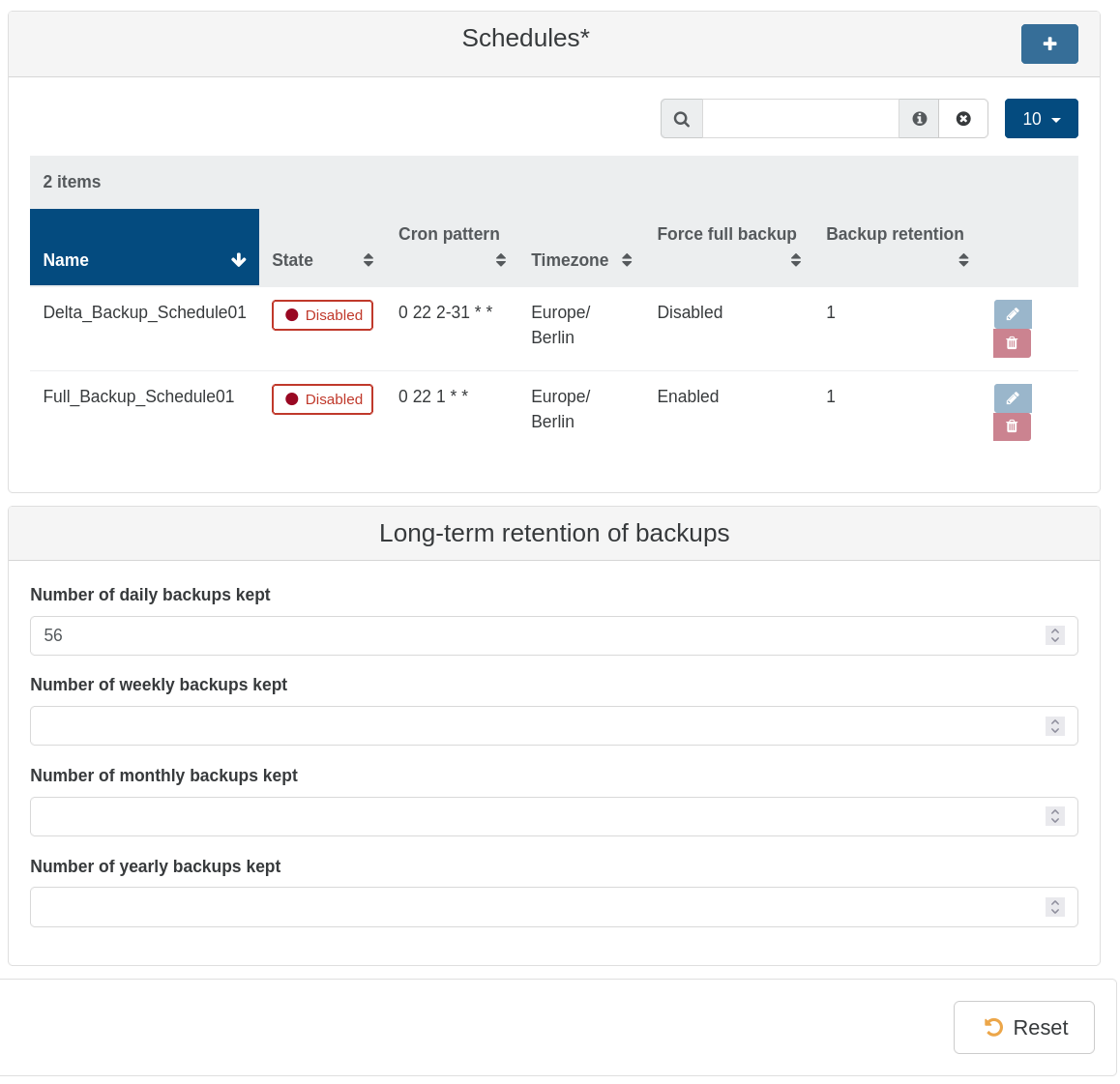
@florent
I tried to upload it with the "Upload button" and got this error" [2026-02-05T15_03_26.704Z - backup NG.json](Invalid file type. Allowed types are: .png, .jpg, .bmp, .txt, .diff, .patch, .jpeg) "
2026-02-05T15_03_26.704Z - backup NG_json.txt