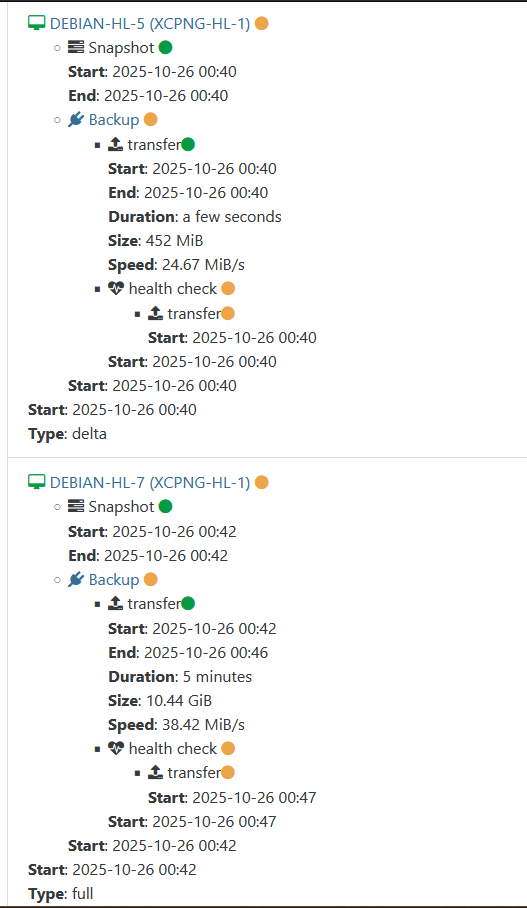
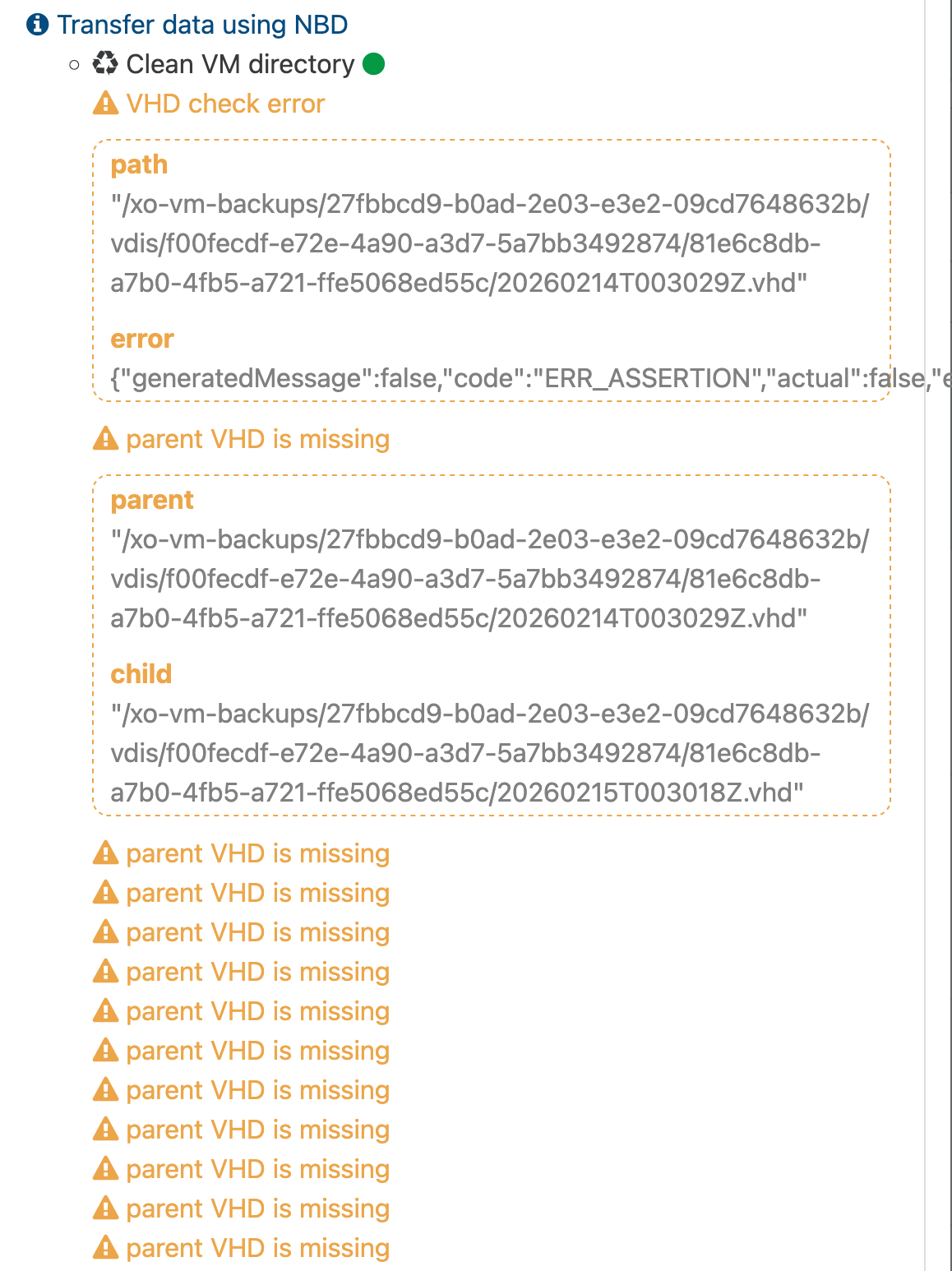
Hello @Austin.Payne,
I wanted to share my experience. I had similar issues through multiple XO versions. However, after learning that health checks rely on the management port I did some more digging. TL;DR it was a network configuration, and not an XO or XCPNG problem. If you have a multi-nic setup and you have XO as a VM on your XCPNG host, I would recommend that whatever network you use for management is on the same NIC.
Setup:
XO is a VM on XCPNG Host (only one host in pool).
Network setup:
eth0 = 1GB NIC = Management interface for XCPNG host (192.168.0.0/24 network)
eth1 = 10GB DAC = NIC for 192.168.0.0/24 network to pass through VMs (XO uses this NIC)
eth1.200 = 10GB DAC = VLAN 200 on eth1 NIC for storage network (10.10.200.0/28). Both the XCPNG host and VMs (including XO VM) use this.
IP setup:
XCPNG host = 192.168.0.201 on eth0; 10.10.200.1 on eth1.200
XO VM = 192.168.0.202 on eth1; 10.10.200.2 on eth1.200
Remote NAS for backups = Different computer on 10.10.200.0/28 network
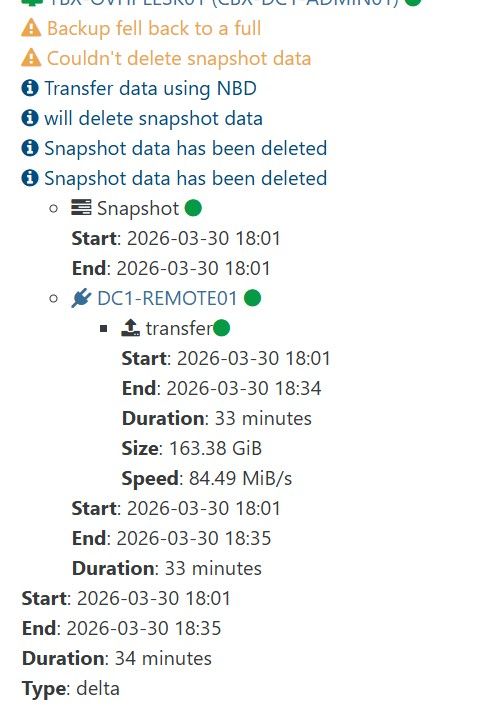
In this setup, backups would always finish, but health checks would hang indefinitely. However, after changing the XCPNG host to use eth1 for the management interface instead of eth0, health checks starting passing flawlessly.
I am not sure if the problem was having the XCPNG host connecting to the same network with two different NICs or if eth1 was the better NIC thus was more reliable during the health check (could also explain why backups would always succeed). It's also possible it was switch related. In this setup, eth0 was connected to a Cisco switch and eth1/eth1.200 was connected to a MIkroTIk switch. Again, not sure what actually solved it, but consolidating everything to a single NIC solved the issue for me (and physically unplugging eth0 after the eth1 consolidation).
Hopefully sharing my experience helps solve this issue for you.