I believe this issue was resolved when the health check system was changed to detect network connectivity at startup so it did not need to wait for then entire VM to boot. Needs the Xen tools to be installed. I have not had an issue since this change.
M
Offline
-
RE: Backup Issue: "timeout reached while waiting for OpaqueRef"
-
RE: Large incremental backups
The server had high memory usage so I expect lots of paging, which could explain the block writes. I've increased the mem and want to see what difference that makes.
-
RE: Job canceled to protect the VDI chain
Host started and issue resolved.
-
RE: Disaster Recovery hardware compatibility
Results are in...
Four VMs migrated. Three using warm migration and all worked. 4th used straight migration and BSOD but worked after a reboot.
-
RE: ZFS for a backup server
Thanks Oliver. We have used GFS with Veeam previously and will be a great addition.
-
RE: VM association with shared storage
Perfect thanks. The issue is we have an IP address locked to that host so the router needs to live there. The host affinity looks like the correct solution.
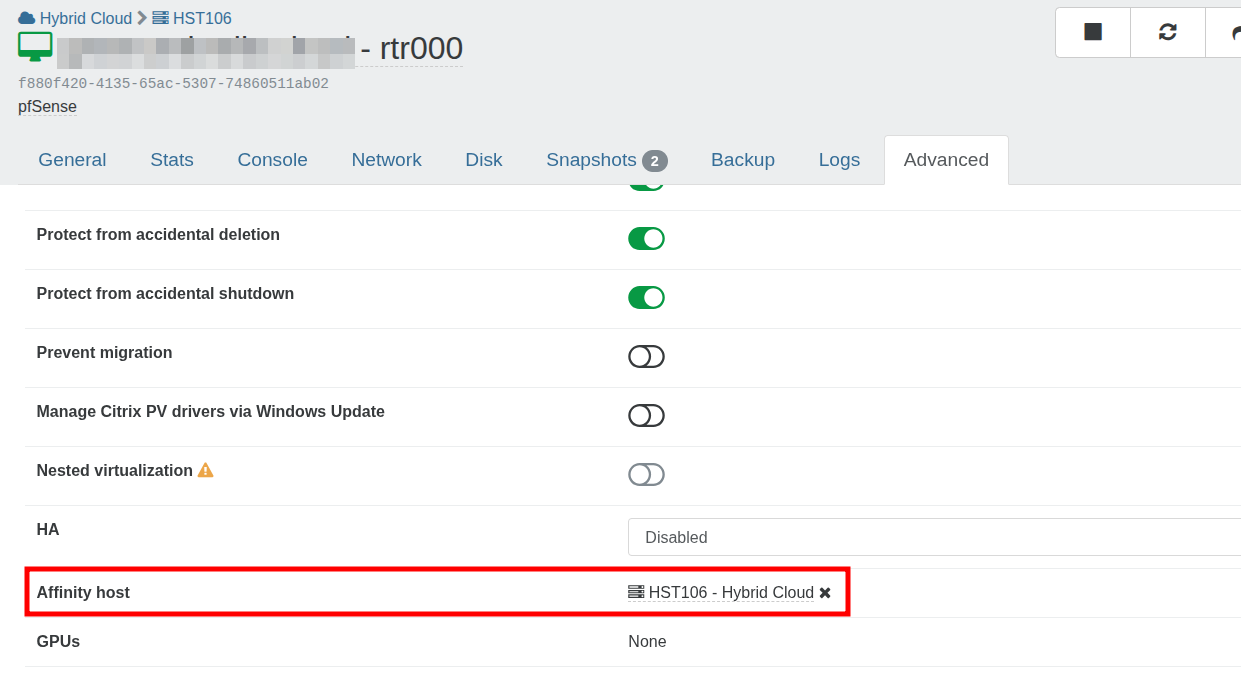
Does host affinity also prevent the VM being migrated manually?
-
RE: Alarms in XO
This host does not run any VMs, just used for CR
I've increased the dom0 ram to 4GB with no more alarms.
-
RE: Windows11 VMs failing to boot
Thank you so much. If you want me I'll be at the pub.
-
RE: Zabbix on xcp-ng
We have successfully installed using:
rpm -Uvh https://repo.zabbix.com/zabbix/7.0/rhel/7/x86_64/zabbix-release-latest.el7.noarch.rpm yum install zabbix-agent2 zabbix-agent2-plugin-* --enablerepo=base,updates -
RE: Migrating a single host to an existing pool
Worked perfectly. Thanks guys.
-
RE: CR backup with retention > 4
Thank you for the response.
To be 100% sure I am not compromising backups, can I clarify that I am able to have a CR retention value of 13, and the warning can be ignored?
When I started a replicated VM, I opt to start a copy, not the original. Would the 13 snapshots still impact performance?
-
RE: CR backup with retention > 4
So for CR backups it is safe to have a retention value of 13 and just ignore the warnings?
-
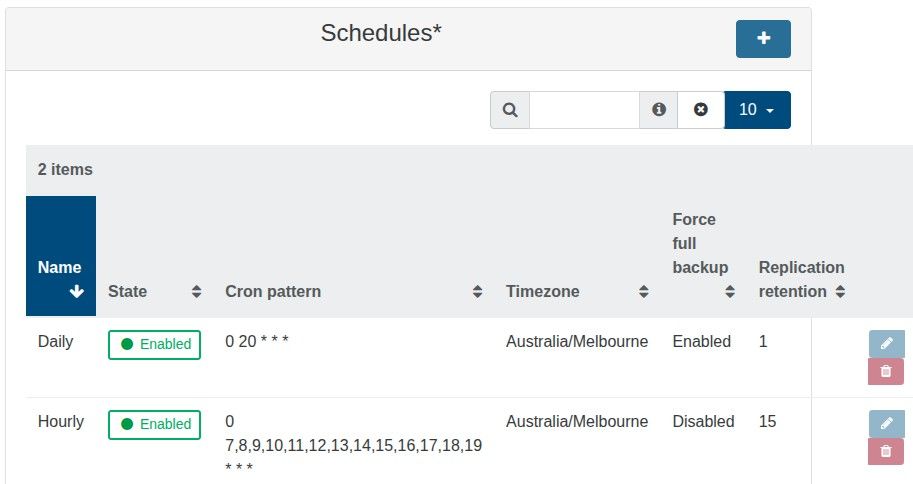
CR backup with retention > 4
Is it possible to have a CR backup with a retention value greater than 4 without generating the too many snapshots error?
We have tested and concluded that as the new CR backups generate snapshots, a retention value of anything greater than 4 will generate a too many snapshots error.
We wish to have hourly CR backups between 7am and 7pm so we need a retention value of 13; however, it does not appear that anything greater than 4 is possible without generating errors.
-
RE: Too many snapshots
I did check this and it definitely completes within the hour.
I am testing a lesser value for CR retention to see if this resolves it.
-
RE: Too many snapshots
Thanks.
The old snapshots are being removed as the total never increases beyond 16, so when a new snapshot is added, the old one is removed. -
RE: Too many snapshots
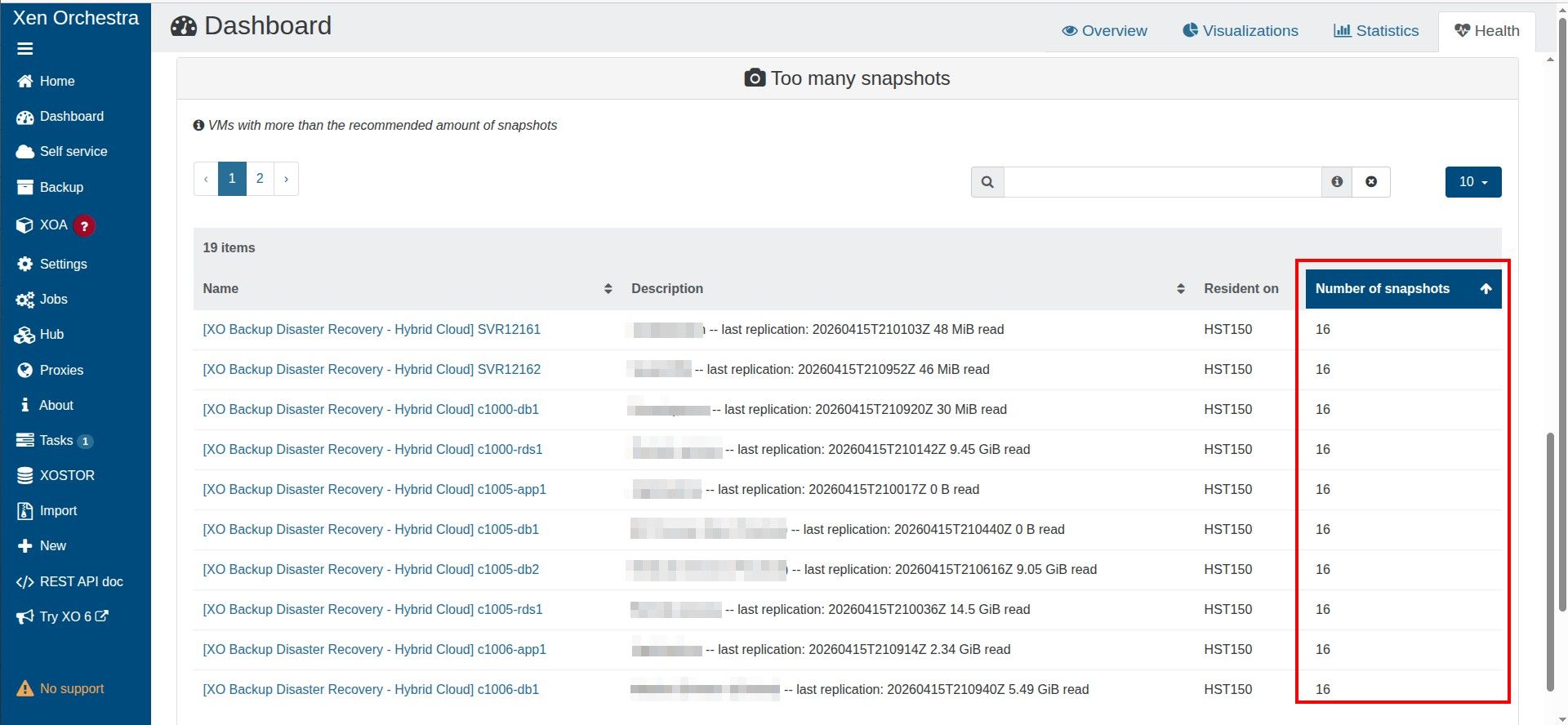
The number of snapshots shows 16, which makes sense as I have two backup schedules, one with a retention of 15 and one with a retention of 1. The daily backup with a retention of 1 resets the chain, as it is a full backup.
-
RE: Too many snapshots
CR jobs are not failing just XO reports too many snapshots under:
Dashboard >> HealthAll good if I can just ignore this warning but thought best to check in case it was an issue.
I got the value of 3 from here.
https://docs.xen-orchestra.com/manage_infrastructure#too-many-snapshots -
RE: Too many snapshots
If each CR backup is now created as a snapshot, instead of a new VM, and the alert triggers after a VM has more than three snapshots, this logically means that the alert will trigger if the CR has a retention value greater than 3.
Have I misunderstood how the CR backup process works?
-
RE: Too many snapshots
@tjkreidl
The offsite backup runs at 8 pm and takes 6/7 hours, whereas the hourly runs from 7 am to 7 pm and only take a few minutes.
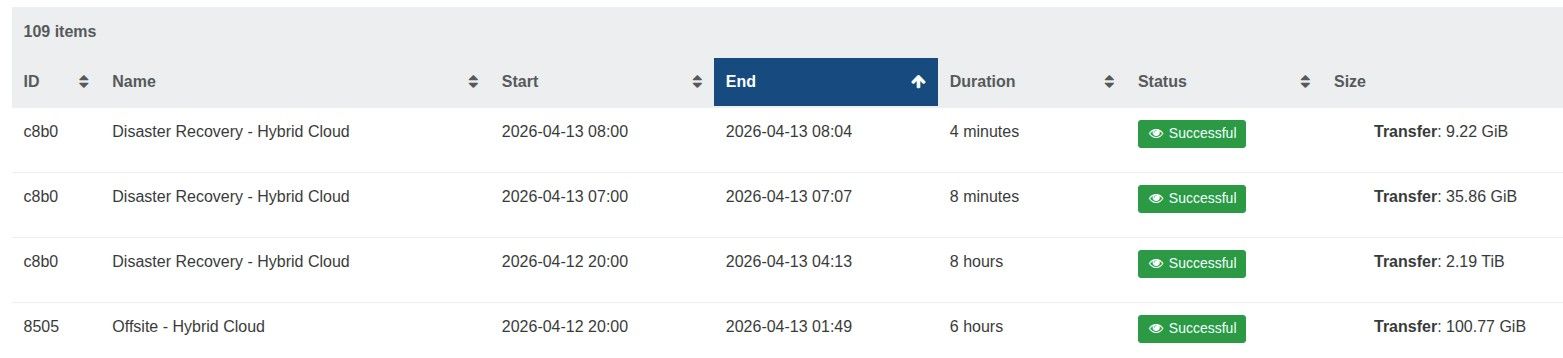
The backup job has 19 VMs, suely this is not too many.
-
RE: Too many snapshots
I wish to maintain 16 restore points using CR, being an hourly restore point over the last two days (8 per day)
I perform a full backup nightly to reset the chain.
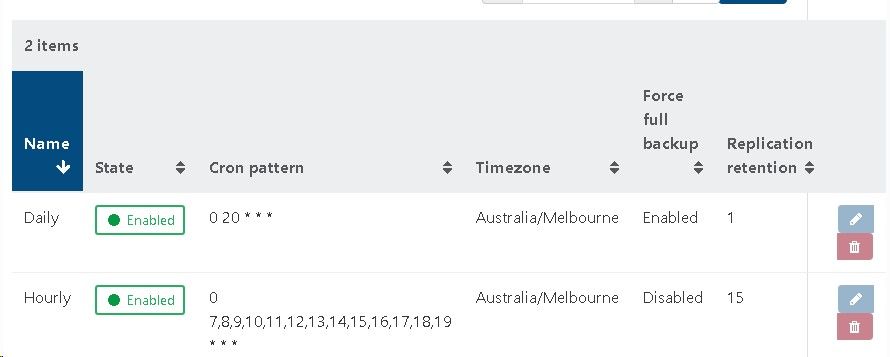
It appears that each CR creates a new snapshot and the old snapshot is removed when a new one is crated
The documentation states this error is shown then there are more than 3 snapshots on a VM
https://docs.xen-orchestra.com/manage_infrastructure#too-many-snapshotsIs this a problematic backup strategy?