Thank you for the response.
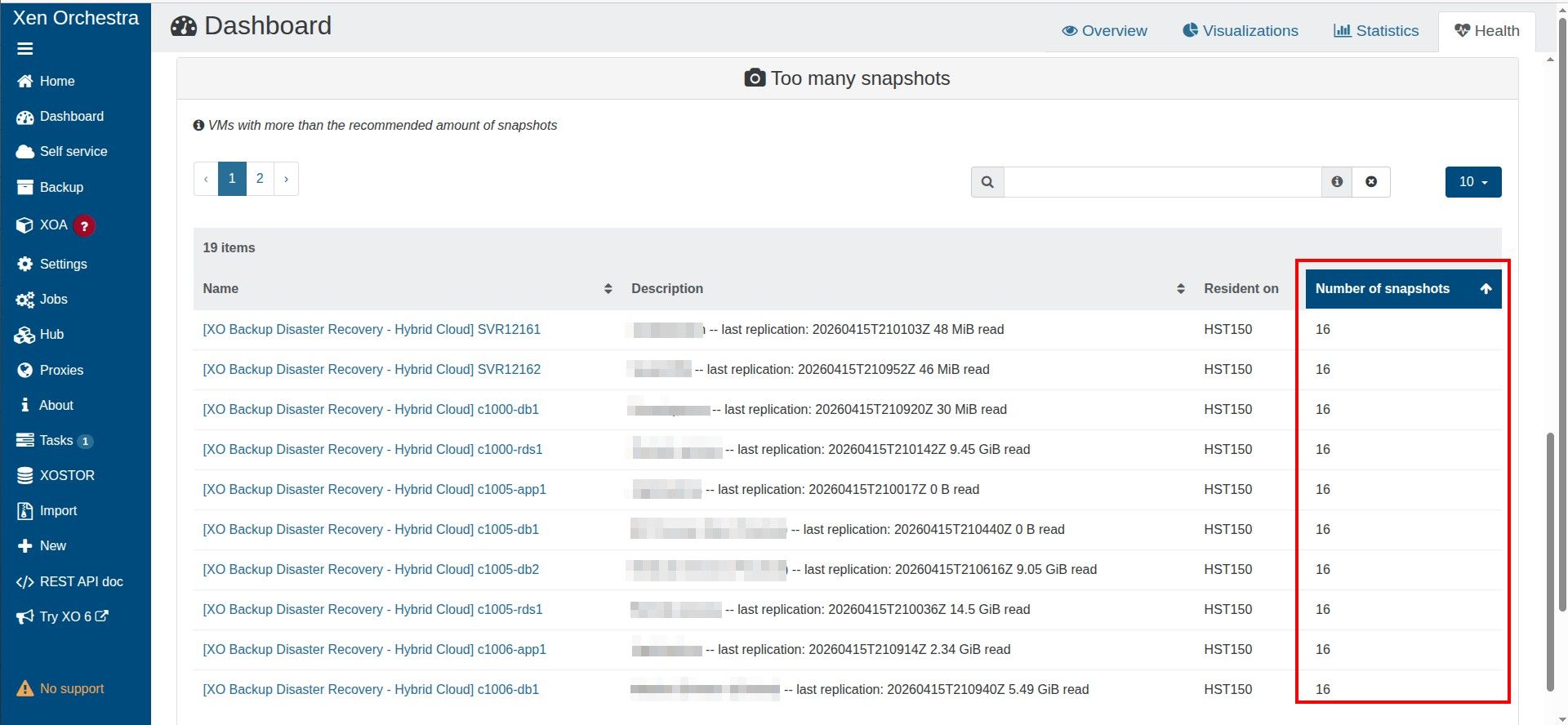
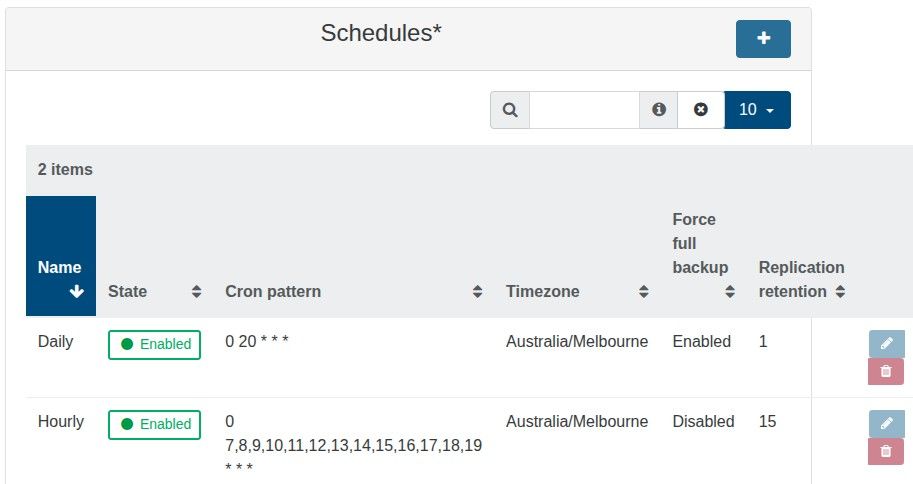
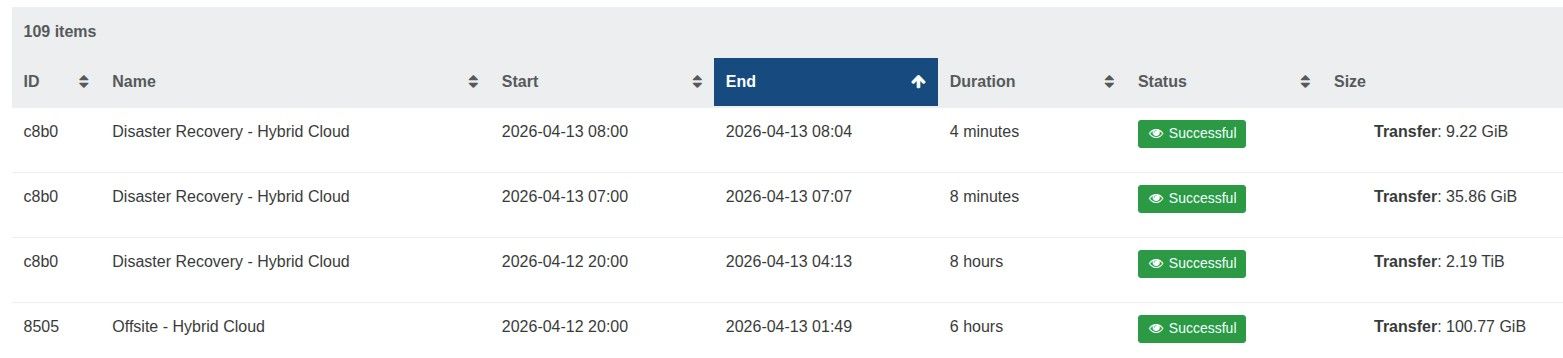
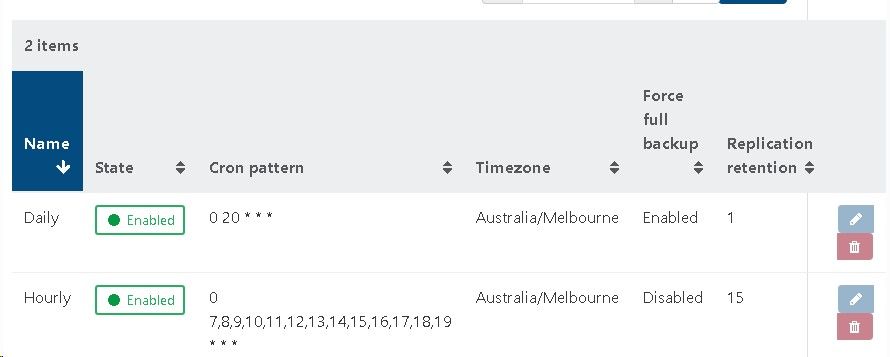
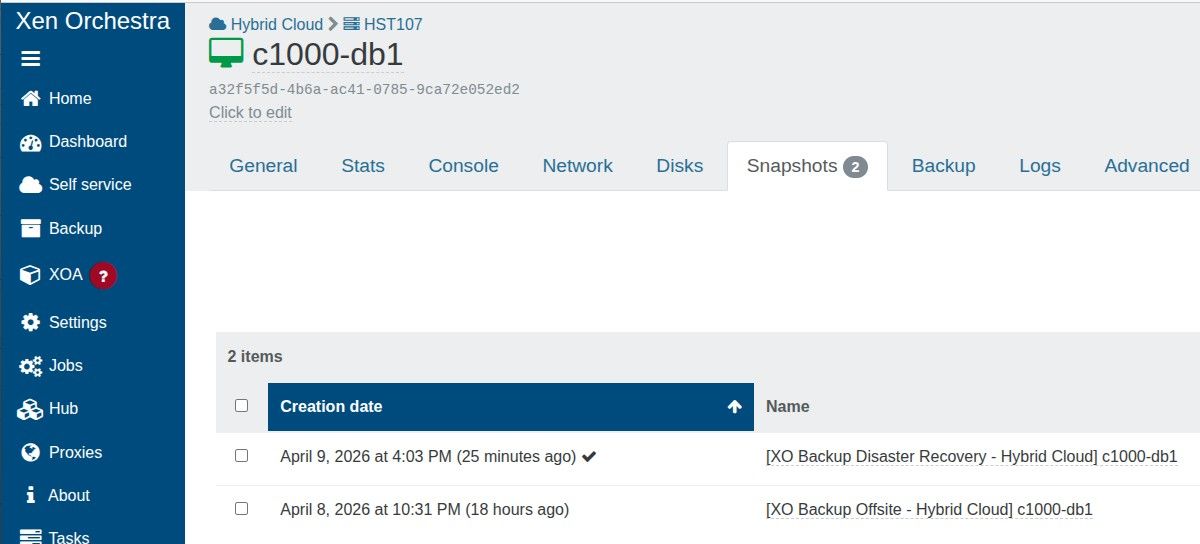
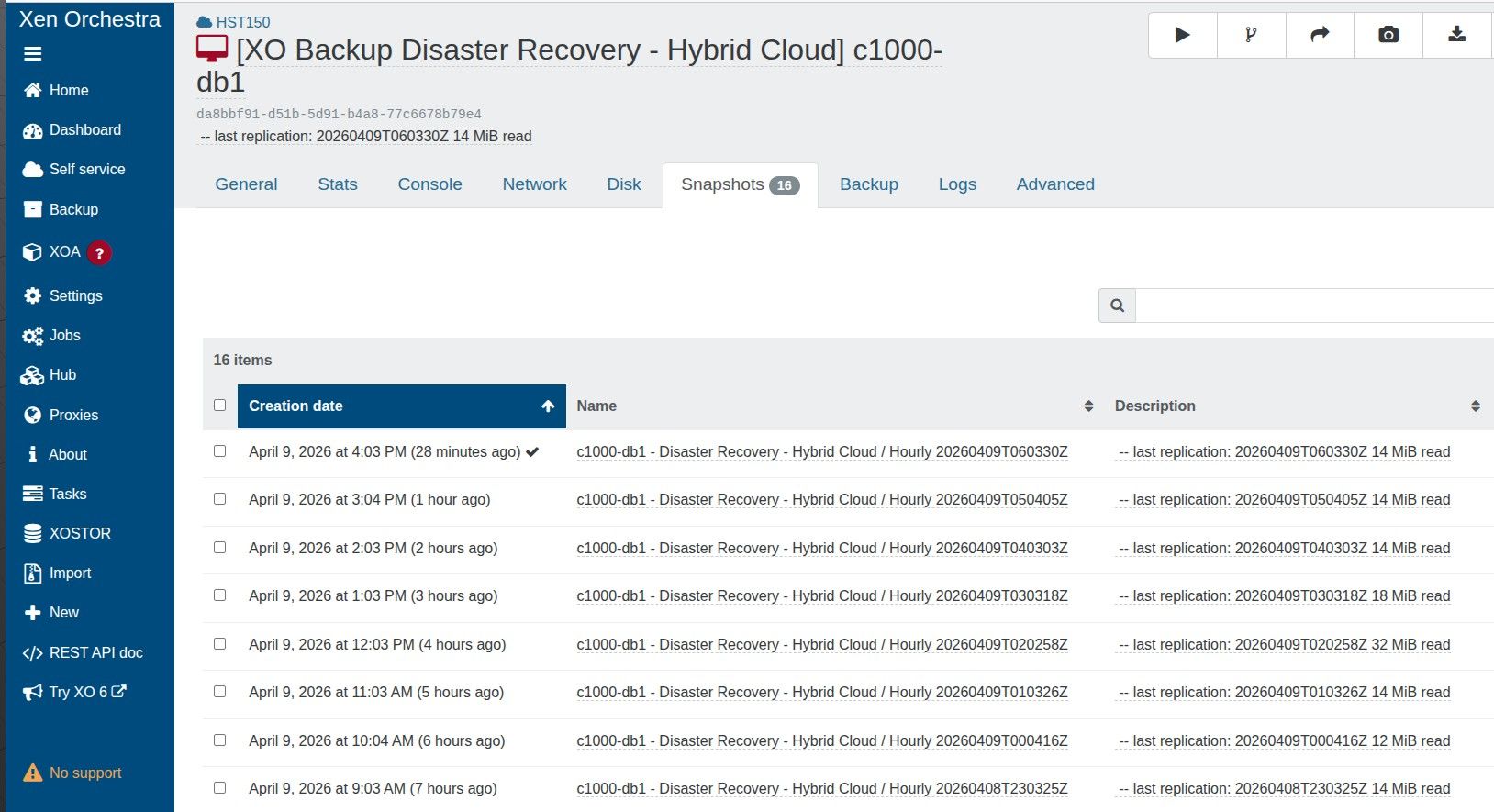
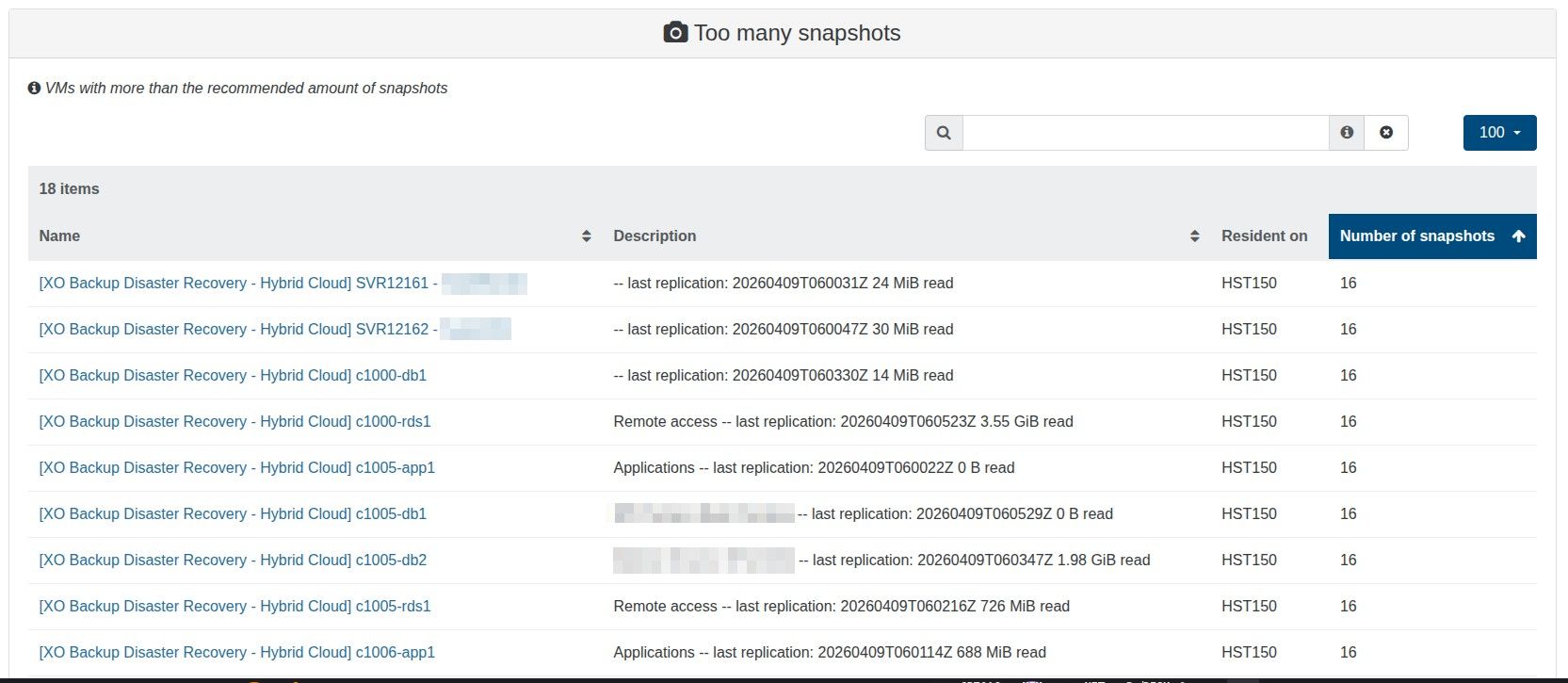
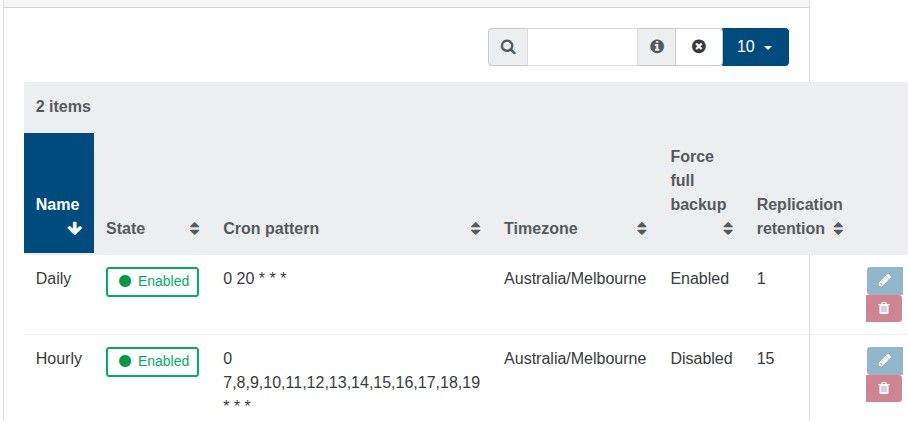
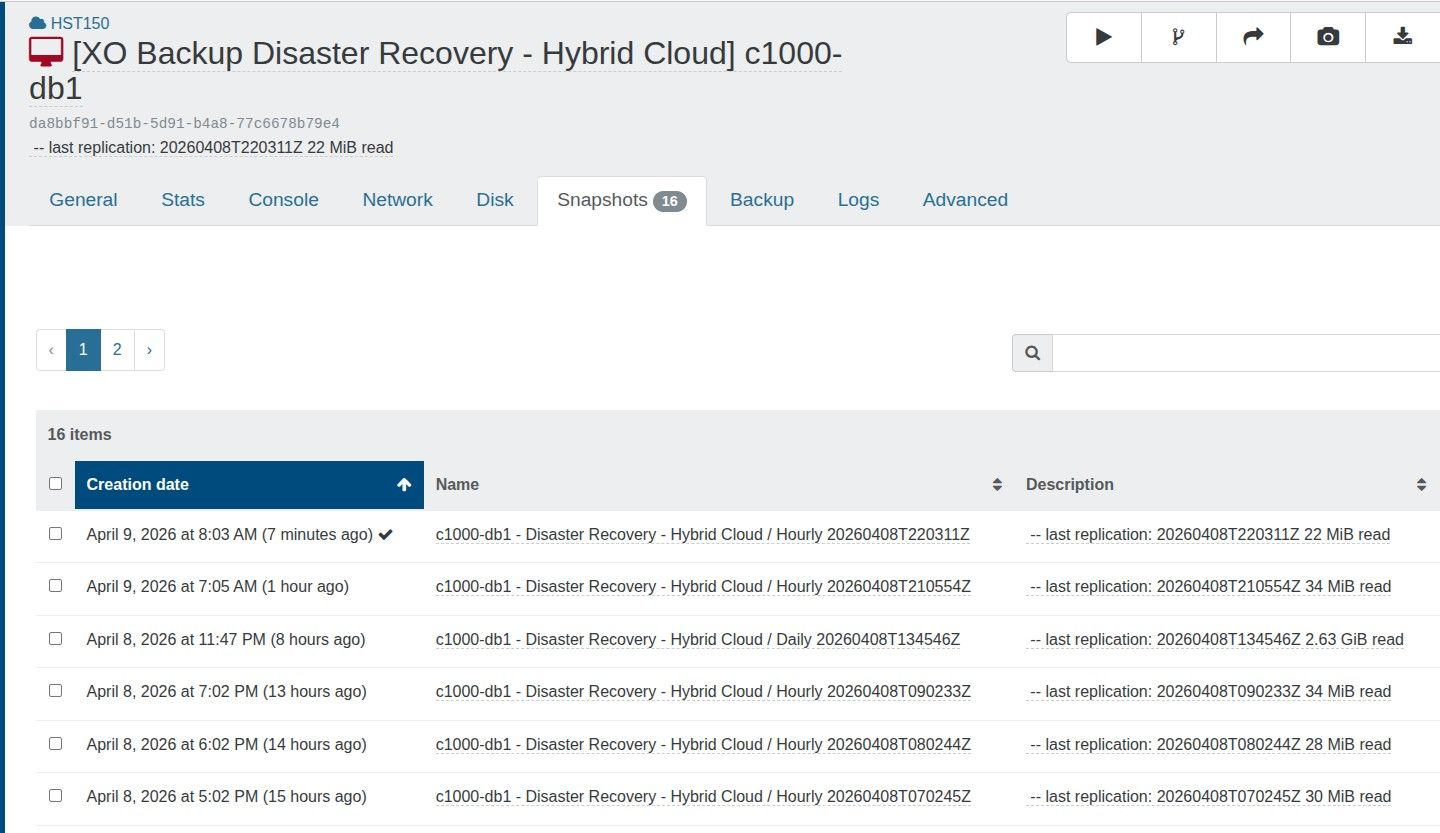
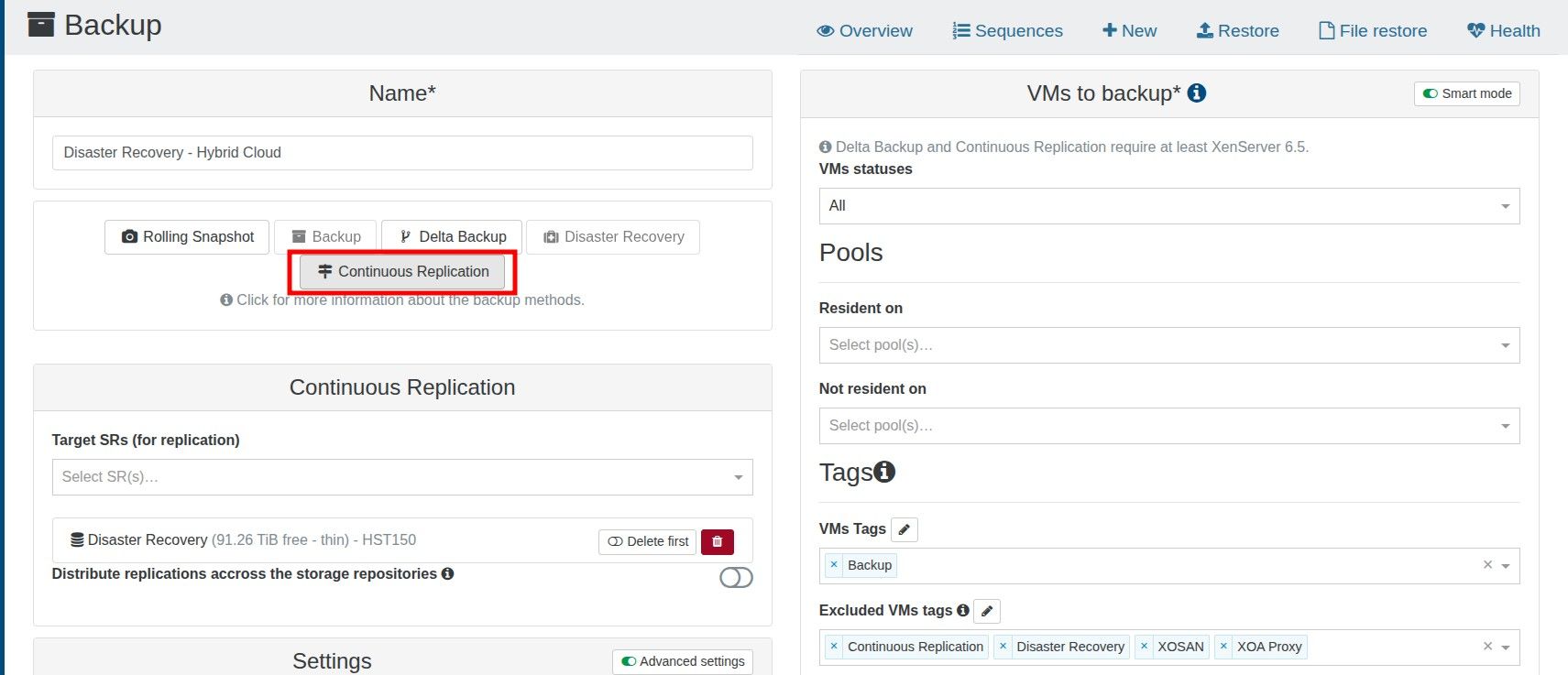
To be 100% sure I am not compromising backups, can I clarify that I am able to have a CR retention value of 13, and the warning can be ignored?
When I started a replicated VM, I opt to start a copy, not the original. Would the 13 snapshots still impact performance?