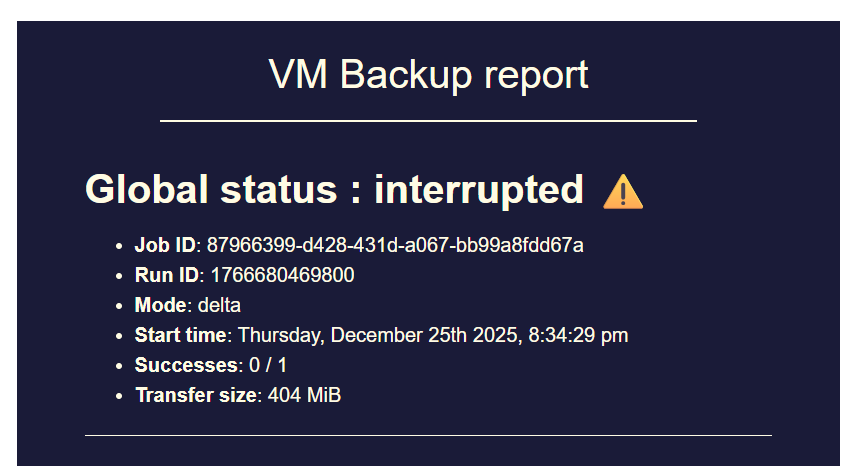
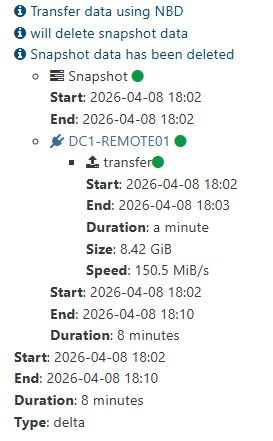
So the scheduled backup at 1pm this afternoon ran with no issue. As stated previously the Coalesces are adding now now show 2 for vm.
edit -
Apr 21 11:22:55 xo-ce xo-server[15617]: },
Apr 21 11:22:55 xo-ce xo-server[15617]: summary: { duration: '6m', cpuUsage: '4%', memoryUsage: '29.01 MiB' }
Apr 21 11:22:55 xo-ce xo-server[15617]: }
Apr 21 13:00:00 xo-ce xo-server[16924]: 2026-04-21T17:00:00.320Z xo:backups:worker INFO starting backup
Apr 21 13:00:00 xo-ce sudo[16938]: xo-service : PWD=/opt/xen-orchestra/packages/xo-server ; USER=root ; COMMAND=/usr/bin/mount -o -t nf>
Apr 21 13:00:00 xo-ce sudo[16938]: pam_unix(sudo:session): session opened for user root(uid=0) by (uid=996)
Apr 21 13:00:00 xo-ce sudo[16938]: pam_unix(sudo:session): session closed for user root
Apr 21 13:00:06 xo-ce xo-server[16924]: 2026-04-21T17:00:06.941Z xo:backups:MixinBackupWriter INFO deleting unused VHD {
Apr 21 13:00:06 xo-ce xo-server[16924]: path: '/xo-vm-backups/138538a8-ef52-4d0a-4433-5ebb31d7e152/vdis/9f7daac4-80a1-41f9-8af0-99b6fe>
Apr 21 13:00:06 xo-ce xo-server[16924]: }
Apr 21 13:00:19 xo-ce xo-server[16924]: 2026-04-21T17:00:19.536Z xo:backups:MixinBackupWriter INFO deleting unused VHD {
Apr 21 13:00:19 xo-ce xo-server[16924]: path: '/xo-vm-backups/6d733582-0728-b67c-084b-56abe6047bfc/vdis/9f7daac4-80a1-41f9-8af0-99b6fe>
Apr 21 13:00:19 xo-ce xo-server[16924]: }
Apr 21 13:01:23 xo-ce xo-server[16924]: 2026-04-21T17:01:23.971Z xo:backups:worker INFO backup has ended
Apr 21 13:01:23 xo-ce sudo[16971]: xo-service : PWD=/opt/xen-orchestra/packages/xo-server ; USER=root ; COMMAND=/usr/bin/umount /run/xo->
Apr 21 13:01:23 xo-ce sudo[16971]: pam_unix(sudo:session): session opened for user root(uid=0) by (uid=996)
Apr 21 13:01:23 xo-ce sudo[16971]: pam_unix(sudo:session): session closed for user root
Apr 21 13:01:24 xo-ce xo-server[16924]: 2026-04-21T17:01:24.029Z xo:backups:worker INFO process will exit {
Apr 21 13:01:24 xo-ce xo-server[16924]: duration: 83708608,
Apr 21 13:01:24 xo-ce xo-server[16924]: exitCode: 0,
Apr 21 13:01:24 xo-ce xo-server[16924]: resourceUsage: {
Apr 21 13:01:24 xo-ce xo-server[16924]: userCPUTime: 31147905,
Apr 21 13:01:24 xo-ce xo-server[16924]: systemCPUTime: 14319055,
Apr 21 13:01:24 xo-ce xo-server[16924]: maxRSS: 65888,
Apr 21 13:01:24 xo-ce xo-server[16924]: sharedMemorySize: 0,
Apr 21 13:01:24 xo-ce xo-server[16924]: unsharedDataSize: 0,
Apr 21 13:01:24 xo-ce xo-server[16924]: unsharedStackSize: 0,
Apr 21 13:01:24 xo-ce xo-server[16924]: minorPageFault: 367979,
Apr 21 13:01:24 xo-ce xo-server[16924]: majorPageFault: 1,
Apr 21 13:01:24 xo-ce xo-server[16924]: swappedOut: 0,
Apr 21 13:01:24 xo-ce xo-server[16924]: fsRead: 5648,
Apr 21 13:01:24 xo-ce xo-server[16924]: fsWrite: 16101272,
Apr 21 13:01:24 xo-ce xo-server[16924]: ipcSent: 0,
Apr 21 13:01:24 xo-ce xo-server[16924]: ipcReceived: 0,
Apr 21 13:01:24 xo-ce xo-server[16924]: signalsCount: 0,
Apr 21 13:01:24 xo-ce xo-server[16924]: voluntaryContextSwitches: 65983,
Apr 21 13:01:24 xo-ce xo-server[16924]: involuntaryContextSwitches: 7745
Apr 21 13:01:24 xo-ce xo-server[16924]: },
Apr 21 13:01:24 xo-ce xo-server[16924]: summary: { duration: '1m', cpuUsage: '54%', memoryUsage: '64.34 MiB' }
Apr 21 13:01:24 xo-ce xo-server[16924]: }
lines 617-656/656 (END)