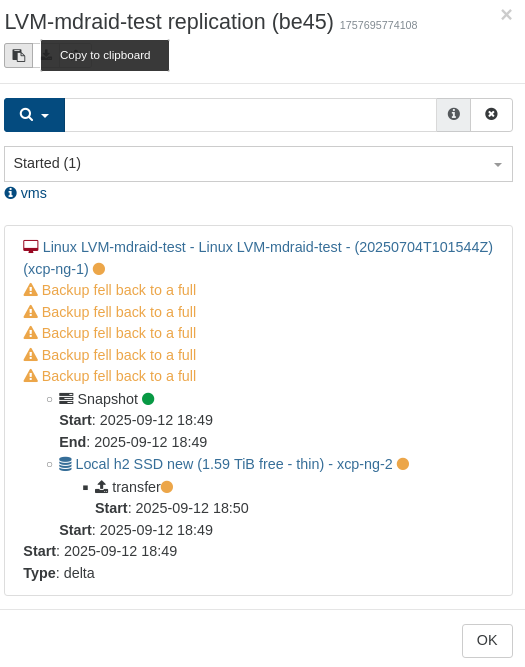
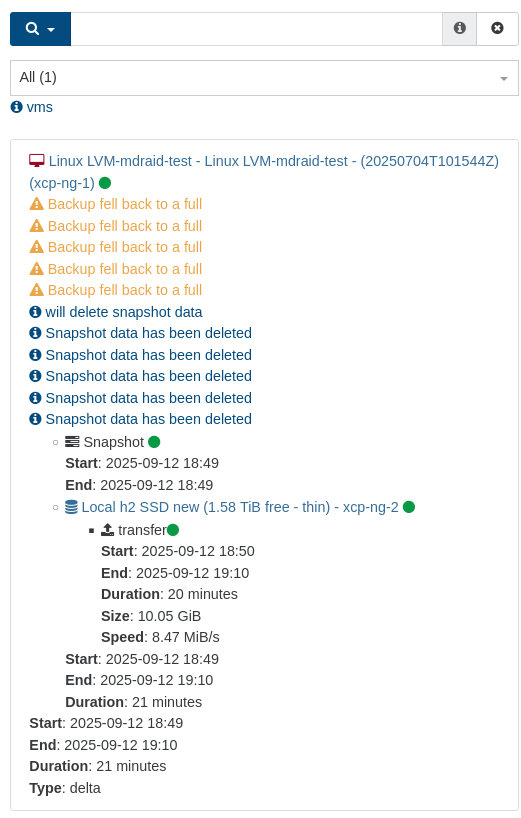
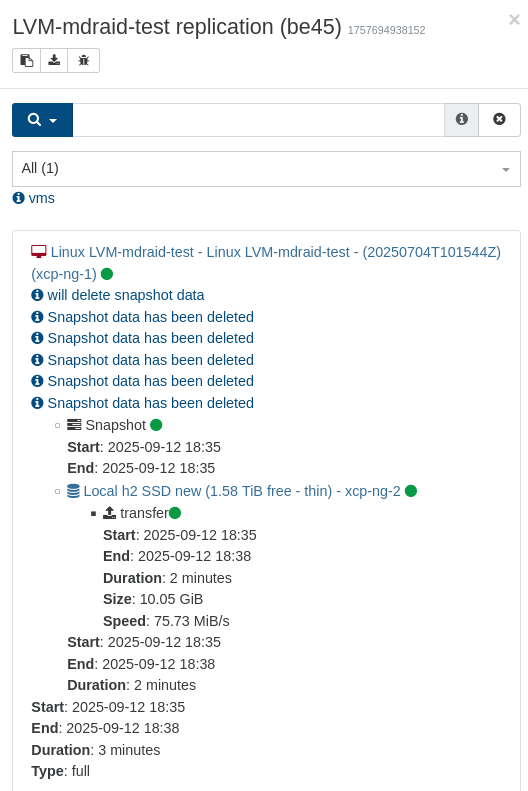
As it's a recently introduced bug, it will probably be fixed very soon. Got 'failure' on my weekly batch of backups during the night (4 machines using 'sequence'). This is real backups (but deltas) going to external storage.
"Global status: failure", but still transfers to storage seems to go through:
{
"data": {
"mode": "delta",
"reportWhen": "failure"
},
"id": "1773627675367",
"jobId": "b0f7dd0c-07c9-4cd8-938b-f519b0961b8d",
"jobName": "ubu-01",
"message": "backup",
"scheduleId": "2e16be52-fc45-45d3-b73b-965d83235fa7",
"start": 1773627675367,
"status": "failure",
"infos": [
{
"data": {
"vms": [
"31788a46-9fb1-3532-36b4-d9ad90c7d310"
]
},
"message": "vms"
}
],
"tasks": [
{
"data": {
"type": "VM",
"id": "31788a46-9fb1-3532-36b4-d9ad90c7d310",
"name_label": "ubu-01"
},
"id": "1773627954874",
"message": "backup VM",
"start": 1773627954874,
"status": "failure",
"tasks": [
{
"id": "1773627954887",
"message": "clean-vm",
"start": 1773627954887,
"status": "failure",
"warnings": [
{
"data": {
"path": "/xo-vm-backups/31788a46-9fb1-3532-36b4-d9ad90c7d310/vdis/b0f7dd0c-07c9-4cd8-938b-f519b0961b8d/35e6144b-5e78-4ae7-816f-abf21e73aeda/data/6d9d6dca-0803-4cc9-8e79-e049203d702e.vhd"
},
"message": "no alias references VHD"
}
],
"end": 1773627980060,
"result": {
"$fault": "server",
"$metadata": {
"httpStatusCode": 500,
"requestId": "12284EA595C10B99",
"extendedRequestId": "MTIyODRFQTU5NUMxMEI5OTEyMjg0RUE1OTVDMTBCOTkxMjI4NEVBNTk1QzEwQjk5MTIyODRFQTU5NUMxMEI5OQ==",
"attempts": 3,
"totalRetryDelay": 200
},
"name": "InternalError",
"Code": "InternalError",
"message": "Internal Error",
"stack": "InternalError: Internal Error\n at ProtocolLib.getErrorSchemaOrThrowBaseException (/opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/core/dist-cjs/submodules/protocols/index.js:69:67)\n at AwsRestXmlProtocol.handleError (/opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/core/dist-cjs/submodules/protocols/index.js:1801:65)\n at AwsRestXmlProtocol.deserializeResponse (/opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@smithy/core/dist-cjs/submodules/protocols/index.js:309:24)\n at process.processTicksAndRejections (node:internal/process/task_queues:103:5)\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@smithy/core/dist-cjs/submodules/schema/index.js:26:24\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/middleware-sdk-s3/dist-cjs/index.js:386:20\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@smithy/middleware-retry/dist-cjs/index.js:254:46\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/middleware-sdk-s3/dist-cjs/index.js:63:28\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/middleware-sdk-s3/dist-cjs/index.js:90:20\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/middleware-logger/dist-cjs/index.js:5:26"
}
},
{
"id": "1773627983950",
"message": "snapshot",
"start": 1773627983950,
"status": "success",
"end": 1773627992689,
"result": "08492698-4a00-4412-4a22-ad1da6114206"
},
{
"data": {
"id": "c4e665e9-68c0-4824-b616-8e397350d44d",
"isFull": false,
"type": "remote"
},
"id": "1773627992689:0",
"message": "export",
"start": 1773627992689,
"status": "failure",
"tasks": [
{
"id": "1773627998066",
"message": "transfer",
"start": 1773627998066,
"status": "success",
"end": 1773629436434,
"result": {
"size": 31975276544
}
},
{
"id": "1773629446409",
"message": "clean-vm",
"start": 1773629446409,
"status": "failure",
"warnings": [
{
"data": {
"path": "/xo-vm-backups/31788a46-9fb1-3532-36b4-d9ad90c7d310/vdis/b0f7dd0c-07c9-4cd8-938b-f519b0961b8d/35e6144b-5e78-4ae7-816f-abf21e73aeda/data/6d9d6dca-0803-4cc9-8e79-e049203d702e.vhd"
},
"message": "no alias references VHD"
}
],
"end": 1773629506113,
"result": {
"$fault": "server",
"$metadata": {
"httpStatusCode": 500,
"requestId": "12284EA595C154A2",
"extendedRequestId": "MTIyODRFQTU5NUMxNTRBMjEyMjg0RUE1OTVDMTU0QTIxMjI4NEVBNTk1QzE1NEEyMTIyODRFQTU5NUMxNTRBMg==",
"attempts": 3,
"totalRetryDelay": 144
},
"name": "InternalError",
"Code": "InternalError",
"message": "Internal Error",
"stack": "InternalError: Internal Error\n at ProtocolLib.getErrorSchemaOrThrowBaseException (/opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/core/dist-cjs/submodules/protocols/index.js:69:67)\n at AwsRestXmlProtocol.handleError (/opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/core/dist-cjs/submodules/protocols/index.js:1801:65)\n at AwsRestXmlProtocol.deserializeResponse (/opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@smithy/core/dist-cjs/submodules/protocols/index.js:309:24)\n at process.processTicksAndRejections (node:internal/process/task_queues:103:5)\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@smithy/core/dist-cjs/submodules/schema/index.js:26:24\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/middleware-sdk-s3/dist-cjs/index.js:386:20\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@smithy/middleware-retry/dist-cjs/index.js:254:46\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/middleware-sdk-s3/dist-cjs/index.js:63:28\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/middleware-sdk-s3/dist-cjs/index.js:90:20\n at async /opt/xo/xo-builds/xen-orchestra-202603131938/node_modules/@aws-sdk/middleware-logger/dist-cjs/index.js:5:26"
}
}
],
"end": 1773629506114
}
],
"end": 1773629506114
}
],
"end": 1773629506114
}
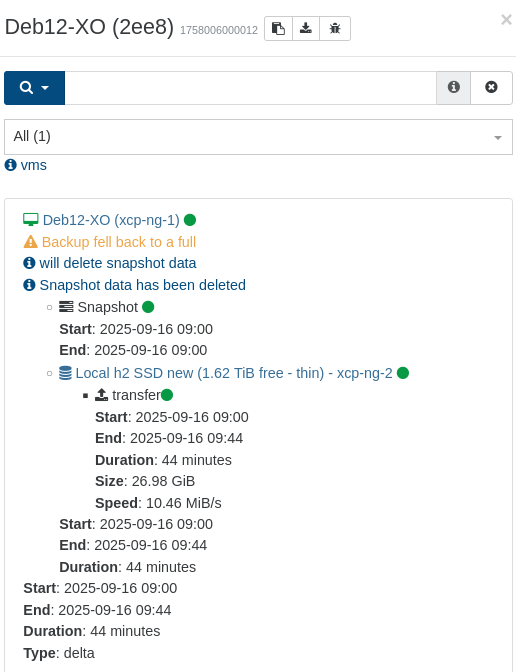
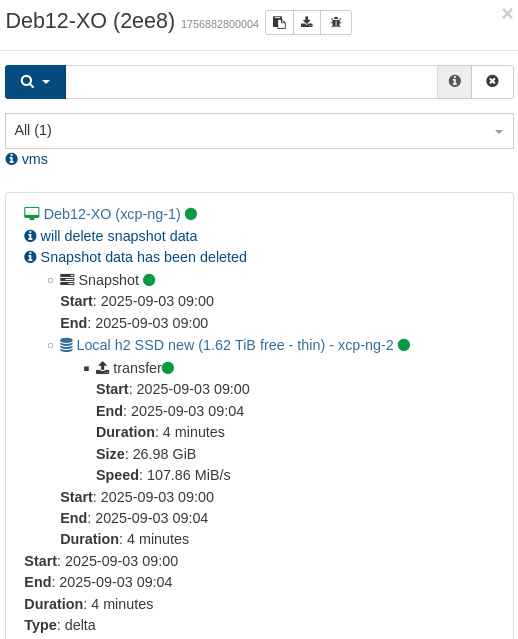
This did not happen with the previous version (but that is more than a month old, so I'm not going back yet)


")