@henri9813 said:
Hello,
I see also this behavior which is "new" since few weeks.
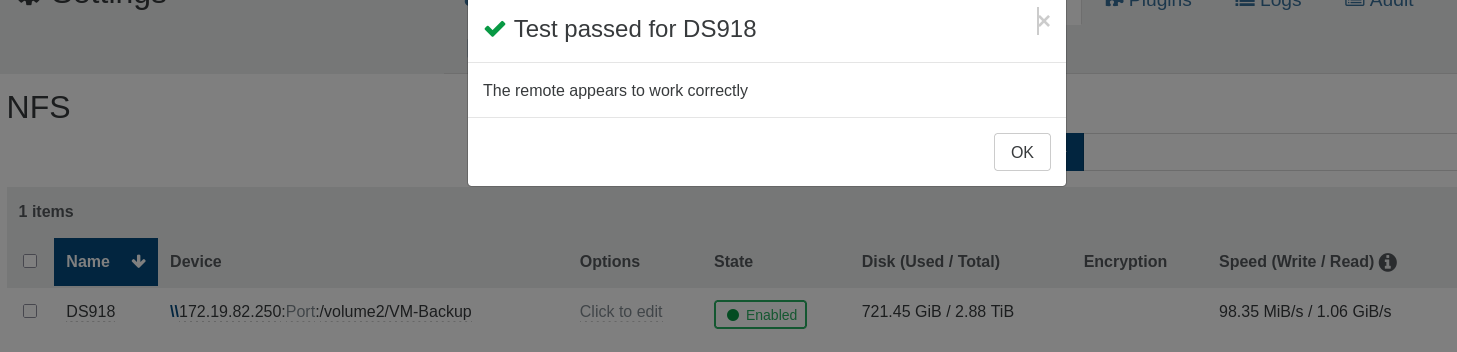
Previously, when a backup start:
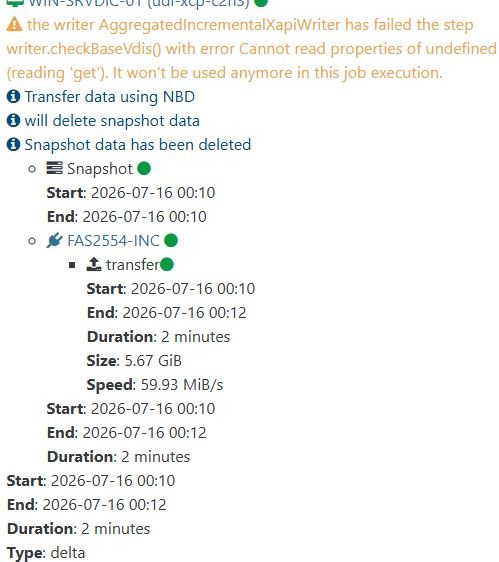
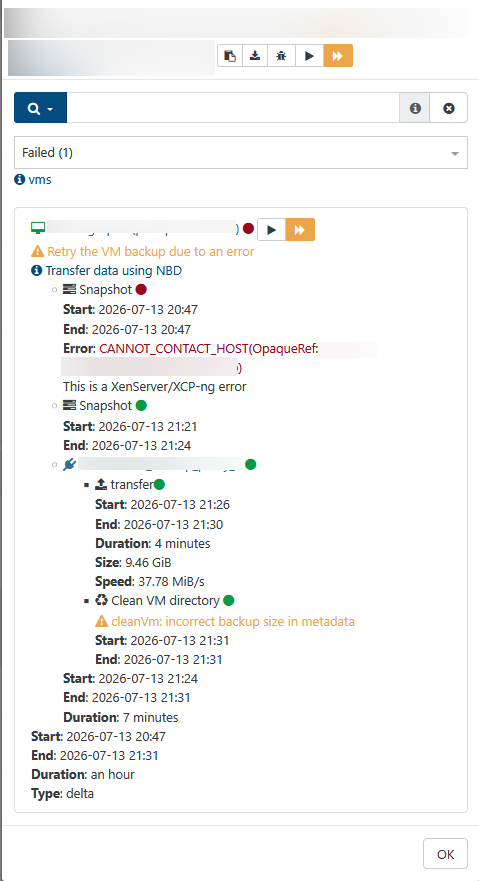
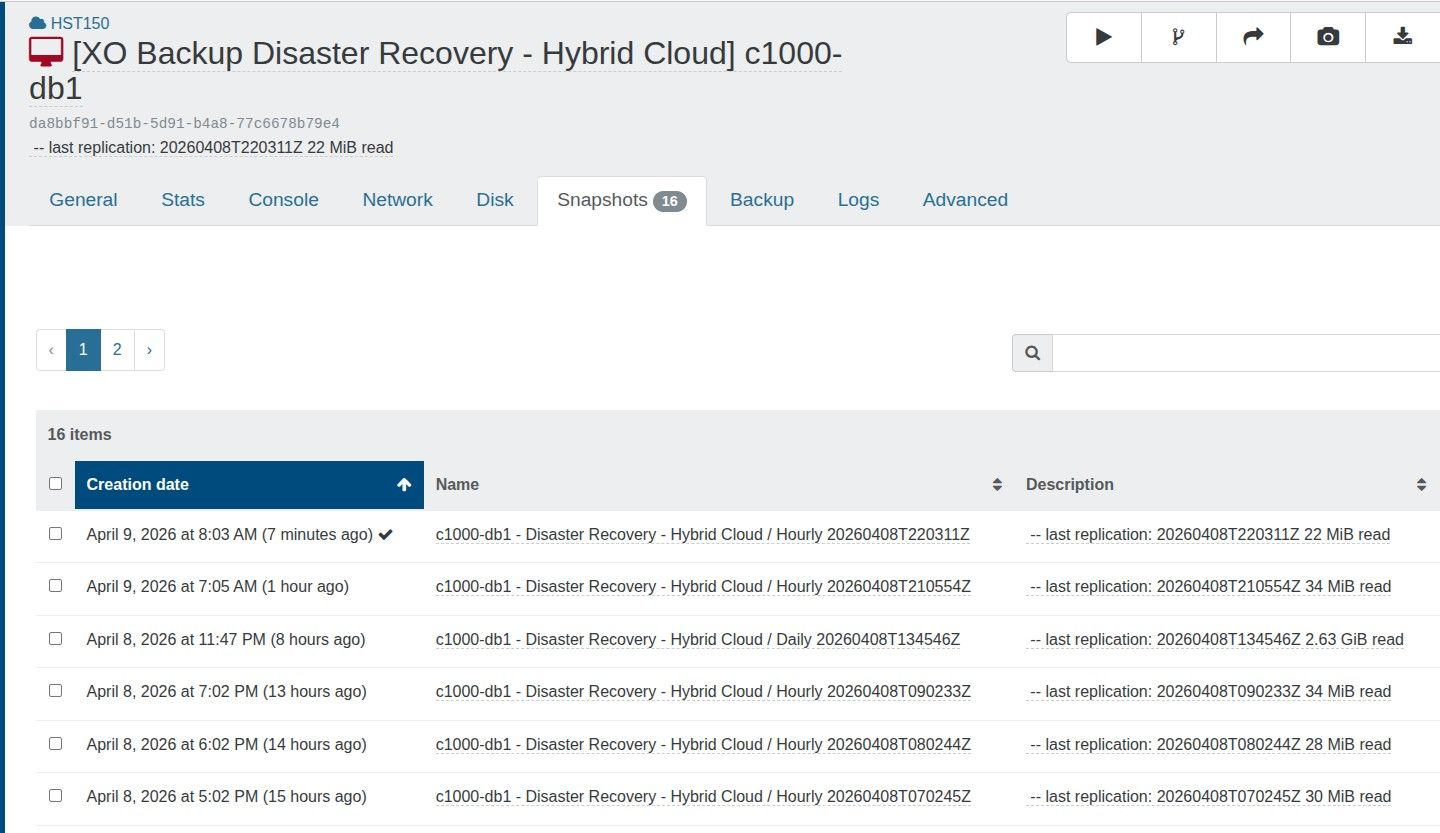
it stake a snapshot ( if there another one before, it delete it ).
it upload the snapshot as a backup
it coalesce the backup on the remote.
end of the game.
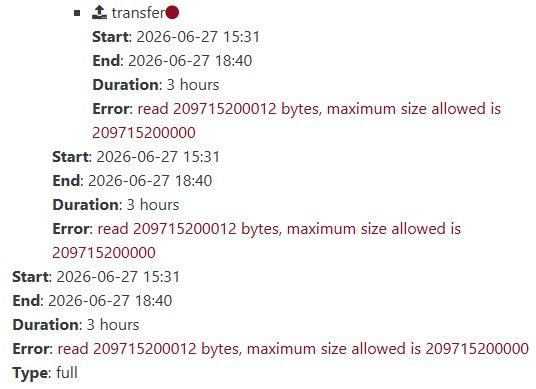
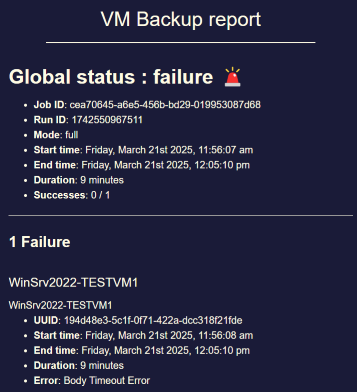
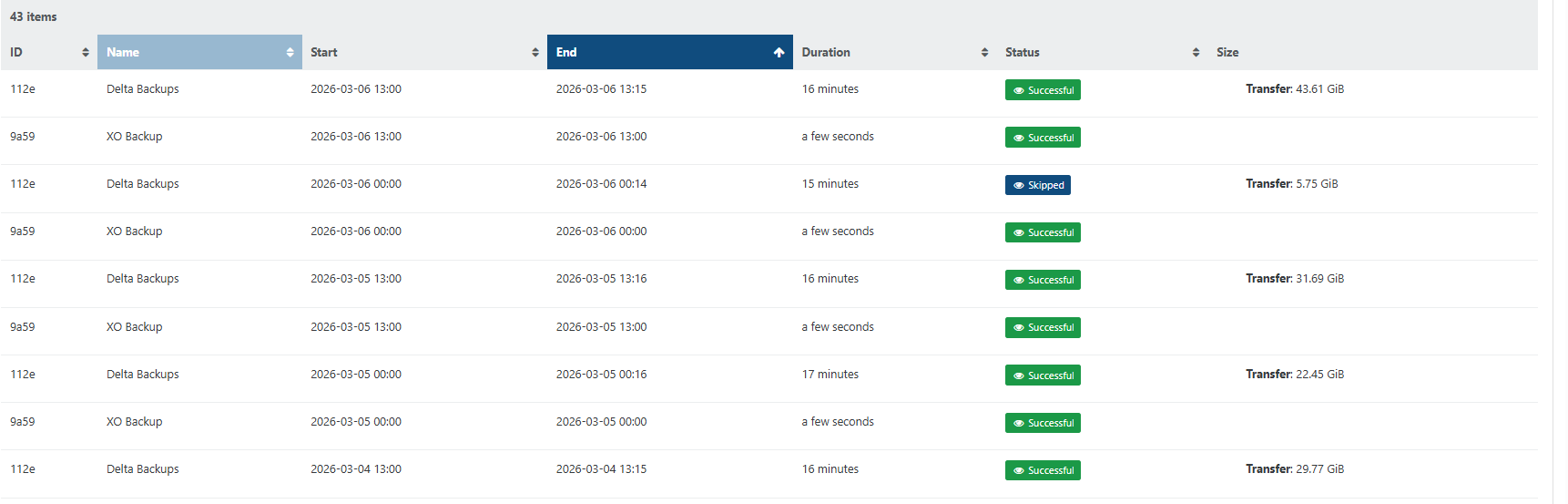
Now, the old snapshots are not deleted anymore which can lead easily to some disk full.
Even with a retention of 1, the problem is present.
I observe this only in Backup job, not DR/CR job.
I just updated my XO to latest version, i will see if the issue is fixed.
Hi @henri9813 ,
Issue should be resolved in 6.5.x, can you confirm on your side ?
Thanks!