I recently implemented Kopia to replace Duplicati on some systems in my network. Now that I have more than a week of backups, I have gained appreciation for the retention tags they use in the KopiaUI program.
It does a good job of indicating why this version is being retained while also showing how many copies it is maintaining at each retention level. Really handy.
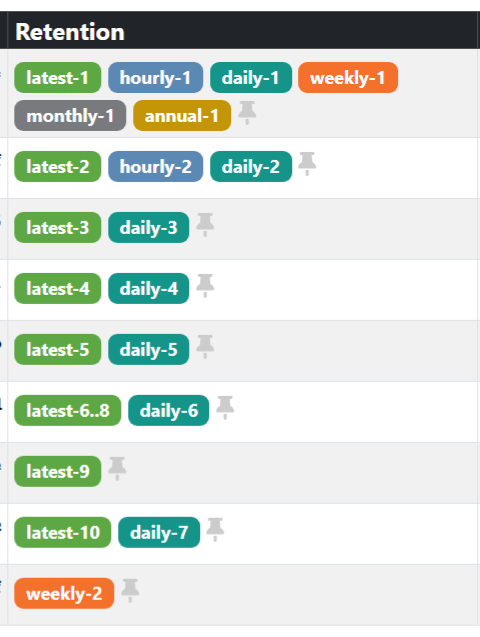
I just noticed the pin to the right. That lets you pin the snapshot so it won't be removed during cleanup. That's kinda cool to be able to single one out to hang on a bit longer, maybe while investigating something I suspect went wrong after that snapshot.
I'm not shilling for Kopia, I haven't used it enough to be sure I trust it yet. I am hoping XO could blatantly steal this kind of idea for backups, especially delta backups. I often get confused about how to get the retention I want when configuring backups and when I search for answers I see other people are also confused.
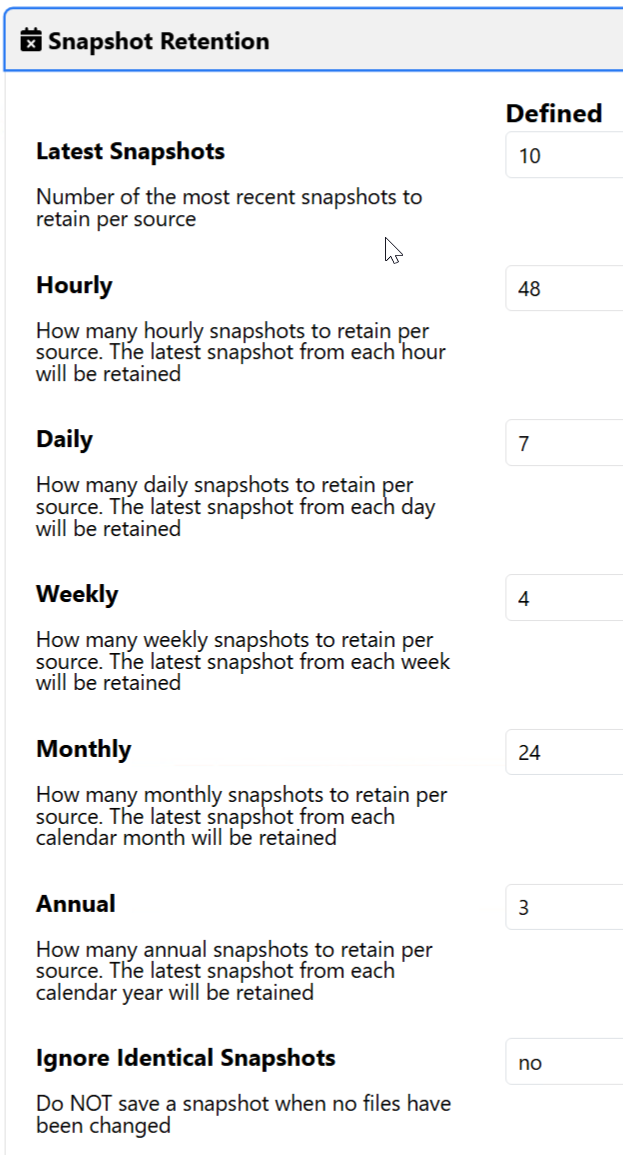
I guess for the sake of completeness, this is how KopiaUI lets me configure retention: