I got this running and when I set up a catalog and baseline the report tells me that it has nothing in the catalog. Is that because it doesn't understand XCP-ng or because my hardware is old enough that it has dropped out of the catalog? I have two PE R630 and one PE R730. I tried both the full default Dell catalog as well as the one that limits to BIOS and firmware updates.
C
Offline
Posts
-
RE: [dedicated thread] Dell Open Manage Appliance (OME)
-
RE: Potential bug with Windows VM backup: "Body Timeout Error"
@poddingue These are VMs that have been doing full backups fine for a very long time. I have run into the too-much-free-space issue in the past with a different brand new VM but these have been around since I migrated them from VMware during the Broadcom fiasco years ago. It is also totally inconsistent which VMs fail with the body timeout. One day it'll be a single one, the next day it'll be three or four and won't include that one, then it'll be a couple other ones unrelated to any of the earlier ones, then I'll have no failures. It's all over the place. I'm just glad that over the course of several days I get good backups of everything.
Oh, a maybe useful data point is that my delta backups that all succeed are handled by a different instance of XO that runs on a different one of the hosts. I might be overly paranoid, but I run full backups and delta backups of the same VMs using different XO instances to different target remotes, at different non-overlapping times. This is part of the reason that I'm not hair-on-fire worried about the failing full backups.
A while back I stupidly let one of my Storage Repositories run out of space and it was the one hosting my main XO instance that handled all the backups. It took a while to get it back going again and I realized I wanted redundancy in what handled backups and moved the deltas over to another XO instance. Too many eggs in that one basket. I also wasn't able to restore the backup of that XO instance because that XO instance is what handled the backups. Thankfully it all worked out in the end, plus a number of extra gray hairs it gave me.
-
RE: Potential bug with Windows VM backup: "Body Timeout Error"
I checked my hosts and the clocks all seem to be very close in time, certainly within a second of each other. The one difference is that the host that is often the target for the backups is set to UTC and the other two are set to MST. Clearly an oversight on my part, unless it is purely a display issue. When I ssh into dom0 and use date, those two show MST and the other shows UTC. If that has ever changed, it would most likely have been in the upgrade from 8.2 to 8.3, which I performed on Jan 28.
All that said, this body timeout issue happens to me every day on random VMs within my backup. Occasionally a backup will complete with none of these errors on any VM but that's uncommon. All of the failed backups are from VMs or configs on the two MST hosts and are stored on the UTC host. (To be clear, they are also stored elsewhere.) I also have an XO instance on one of the MST hosts that performs delta backups and those have never failed. I don't know if that's because they are delta or if it's because they don't touch the UTC host.
The recent failed backups started on 6/26 for my VM full backups and on 6/29 for the config backups. Prior to that the config backups had never had a problem and the full backups had been fine back into February. From February 21 to March 12, I had a smattering of backup failures due to
body timeout errorfor the full backups. -
RE: Backup fails with "Body Timeout Error", "all targets have failed, step: writer.run()"
I see this Body Timeout Error frequently, almost every day, but for random VMs. It has been happening for weeks but since it's not consistently the same VM I figured overall I still have good backups. I also back up the VMs in different ways and the others aren't failing. It has more recently been happening with the config backups which should be very short. Previously I wondered if it could be increased network activity that messes with a long backup of a big VM but that would not be the case for config backups.
The failing backups are all network local, just to be clear, I am not streaming this backup to Backblaze or something where internet connectivity might be causing it.
-
RE: How to Setup IPMI in XO
I got my R730 working, thanks to @majorp93 giving the tip about
dmidecode. Thanks a bunch. It turns out that while this is a Dell R730, it was actually sold by a different vendor for use as video storage so the internal product name doesn't have Dell in it, it'sHD NVR. I used that as the vendor field and tweaked a couple other plugin settings and now it gives me data.I am still missing two of the values in the UI and I'm not sure why, but for different reasons.
On my R630 servers they show the server IP address under the IPMI badge. They also both have the default Dell
/^ip address$/ias the regex in theipsetting in the plugin. I used that same regex in the R730 and I can see in theipmitoollisting that it has the same field name for the IP address as the R630, yet it showsIPMI: Unknown.Also confusing is that the R630 servers have nothing under
fanStatusin the plugin settings but they show14x fans status: ✅in the UI. The R730 also has nothing under the plugin settingsfanStatusfield but it has no data in the UI. Looking at theipmitooloutput I am not sure what field it would use for fan status. It makes me think there must be a default field name it is trying with the R630 to get that status but that doesn't work with the R730.Any hints about how to get those last two badges to work on the R730?
I am also not sure what
bmcStatusshould be set to. I don't know what that means exactly so I don't know if any of the fields shown inipmitoolare applicable.This plugin is really cool, thank you so much for building it.
-
RE: Is v8.3 NUMA aware?
@TheNorthernLight Thanks for pointing that out, that totally makes sense, I should have realized to look it up that way. I guess I just think of XCP-ng as its own product so much that I forget it's based on Xen even though I know that.
-
RE: Is v8.3 NUMA aware?
If anyone can point me to documentation on this, I would greatly appreciate it. I have looked in the docs and searched for an answer and come up empty.
-
RE: How to Setup IPMI in XO
I have two PE R630 and one PE R730xd. The two R630s show the IPMI data in XO but the R730xd does not. If I run
ipmitool sensorfrom an ssh session, I get very similar data back on the 730 and 630.This isn't critical to me, just letting you know that there are cases that functioning
ipmitoolon a Dell does not seem to be enough to show it.There are some differences in the labels. The R730 has "Fan1 RPM", "Fan2 RPM" while the R630 has "Fan1A", "Fan2A", "Fan1B". Most of the other interesting fields seem to have the same names but the order is a bit different and I didn't do an exhaustive comparison.
It's very cool that you are surfacing this data now.
-
Is v8.3 NUMA aware?
I was rebooting my servers due to the patches released last week and I notice that the BIOS in my server was not set to interleave the memory. Since I have symmetric memory sticks, it seems like it should be set to interleave. However, the BIOS does say that for NUMA aware OSs, that interleaving should be left to the OS. I don't recall now, and my notes don't say, if I intentionally left interleaving off because v8.2 I was installing at the time was NUMA aware.
Memory interleaving on a Dell R630: on or off?
During the last patch I turned on interleaving for my R730xd (without reading the help that says not to do it with NUMA aware OSs) and it feels faster to me, but I didn't do any real testing so that could be wishful thinking bias. It certainly doesn't seem to have hurt performance.
-
RE: Potential bug with Windows VM backup: "Body Timeout Error"
@nikade I did install the 97 XCP patches and that night the VM that was failing to backup was able to successfully backup. It had a 500GB secondary drive that was formatted but totally empty.
I had not yet patched my XO from source to the latest, it was maybe 24 commits behind. On Friday I updated it so I will find out on Monday if those backups continued to work but I assume they did.
-
RE: Potential bug with Windows VM backup: "Body Timeout Error"
Amazing timing. I have been having this issue with a VM I just set up and I came here to find out if this is a known problem, only to discover that the 97 patches I have been planning to install tonight are going to fix it.
-
RE: Seeking advice on debugging unexplained change in server fan speed
@paco Oh, that's great information, thank you. I'd much rather reset that flag instead of constantly adjusting the fans.
-
Cool way to indicate retention reasons on backups
I recently implemented Kopia to replace Duplicati on some systems in my network. Now that I have more than a week of backups, I have gained appreciation for the retention tags they use in the KopiaUI program.
It does a good job of indicating why this version is being retained while also showing how many copies it is maintaining at each retention level. Really handy.
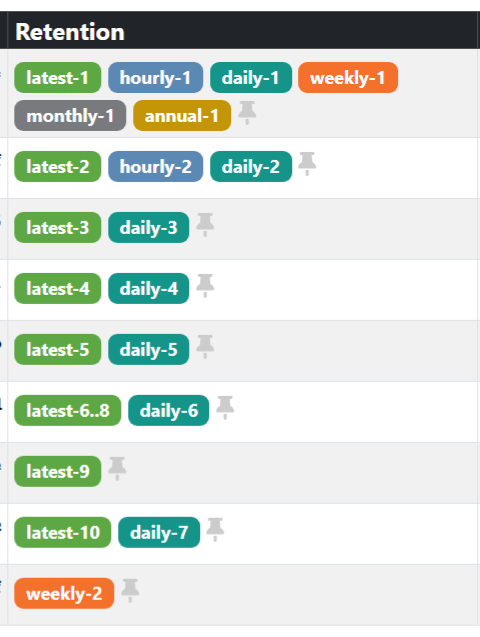
I just noticed the pin to the right. That lets you pin the snapshot so it won't be removed during cleanup. That's kinda cool to be able to single one out to hang on a bit longer, maybe while investigating something I suspect went wrong after that snapshot.
I'm not shilling for Kopia, I haven't used it enough to be sure I trust it yet. I am hoping XO could blatantly steal this kind of idea for backups, especially delta backups. I often get confused about how to get the retention I want when configuring backups and when I search for answers I see other people are also confused.
I guess for the sake of completeness, this is how KopiaUI lets me configure retention:
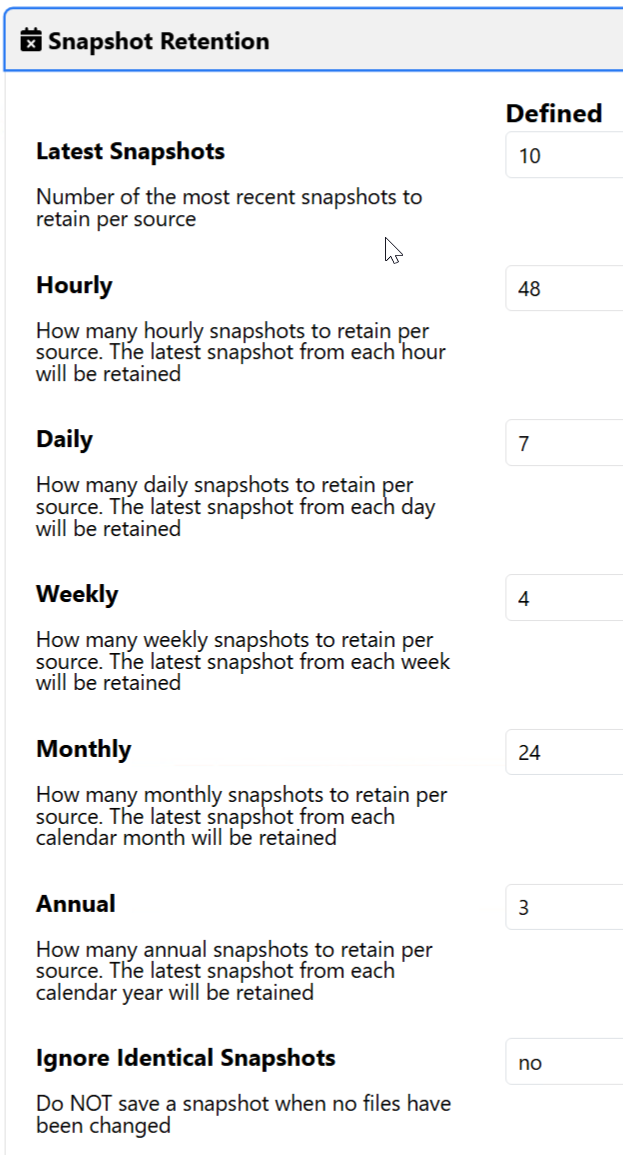
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@JamfoFL Thank you for the follow-up. Now I feel like I can install those patches. Bonus that it appears there are 23 patches now rather than the 22 I saw last week. Now I'm glad I waited, though I think the newest patch doesn't apply to my hardware anyway.
-
RE: How do I diagnose a missing VDI error with Mirror backups
Thank you @florent. I'll do that.
Update: It worked.

-
RE: How do I diagnose a missing VDI error with Mirror backups
Those 5 mirror backups continued to fail over the weekend.
The good news is that the normal delta backups succeeded over the weekend and didn't have any random failures I've been seeing.
-
How do I diagnose a missing VDI error with Mirror backups
I have a couple Delta backups that target the same remote. Yesterday I set up a Mirror backup between that remote and another remote. When I ran the Mirror backup yesterday, it was successful.
Today 7 of the VMs succeed in the backup but 5 of them fail with:
Missing vdi <guid> which is a base for a deltaCould this be caused by the fact that the target for the Mirror backup used to be a target for the Delta backup so it has files on it already. Do I need to purge the folder entirely? I thought maybe that would give it a head start and the reason I'm using the Mirror backup is because the Delta backup used to fail randomly on random VMs when backing up to both remotes.
How would I go about diagnosing this? I assume since the guid for the vdi is missing, it's going to be hard for me to find since I can't find something that's missing. Alternatively, maybe it's because it's currently a weird mix of old Delta backups and new Mirror backups and maybe over the next few days it will purge enough old stuff that it will start working cleanly.
Should I delete the entire remote target of the Mirror to get it started cleanly? Or, more likely, delete all backups on that Mirror for the 5 VMs that failed with this error.
-
RE: Xen Orchestra from Sources unreachable after applying XCPng Patch updates
@JamfoFL Any luck getting this to work? I've put off installing the patches because I don't want to lose my XO installs.
-
RE: Can I rsync backups to another server rather that using two remotes?
@olivierlambert I totally forgot about mirror backups, thanks for the reminder.
I see that a mirror will let me have different backup retention on the mirror target than I do on the mirror source. That's fantastic in my case because the mirror source has less storage space than the mirror target. Using rsync would have limited the backup retention on the Synology.
Now can you tell me how to recover the hours I spent figuring out I couldn't get it working to pull from the Synology side then the time to figure out how to schedule tasks in UNRAID and learn rsync and confirm it would do what I want it to do?

-
Can I rsync backups to another server rather that using two remotes?
I have two remotes that I use for delta backups. One is on a 10Gbe network and the other only has a single 1Gbe port. Since XO writes those backups simultaneously, the backup takes a really long time and frequently randomly fails on random VMs.
I was thinking it would be better if I have XO perform the backup to the 10Gbe remote running UNRAID then schedule an rsync job to mirror that backup to the 1Gbe remote on a Synology array. I've already NFS mounted the Synology share to UNRAID and confirmed I can rsync to it from a prompt, I just need to create a cron job to do it daily. In addition to, hopefully, preventing the random failures, it would let XO complete the backup a lot faster and my UNRAID server and Synology will take care of the rest, reducing the load on my main servers during the workday. The current backup takes long enough that it sometimes spills into the workday.
I'm wondering if that will cause any restore problems. When XO writes to two remotes, does it write exactly the same files to both remote such that it can restore from the secondary even if it never wrote the files to that remote? I would assume they are all the same but want to make sure I don't create a set of backup files that won't be usable. Granted, I can, and will, test a restore from that other location but I don't want to destroy all the existing backups on that remote if this would be a known-bad setup.
Note, I did a --dry-run with rsync and see quite a few files that it would delete and a bunch it would copy. That surprises me because that is still an active remote for the delta backups. I'm suspicious that the differences are due to previously failed backups.