Invalid Health Check SR causes Bakup to fail with no error
-
TL-DR - does your Health Check SR still exist? It turns out mine didn't!
This a story about finding an unhandled edge case in the Xen Orchestra Backup [NG...? it's just the backup tool now and we don't call it "NG" anymore, right?] utility: When you delete the SR to which your backup job restores vms for Health Checks, it fails without much helpful information.
On the latest commit to master:
So I recently moved my vm disks to a new SR, made the new SR the pool default, and removed the previous SR. Then I noticed that my backups were failing and I was getting no error message. It was quite strange. I decided to update my Xen Orchestra "community edition" (installed using the ronivay XenOrchestraInstallerUpdater tool) to the latest master commit, but the issue was still happening.
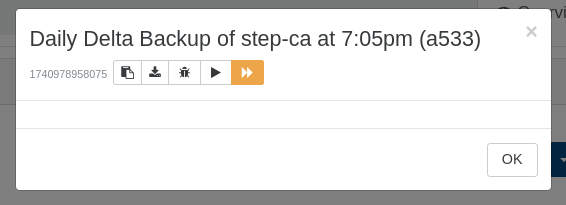
An example log from this evening before I solved the mystery:
{ "data": { "mode": "delta", "reportWhen": "failure" }, "id": "1740978958075", "jobId": "9017a533-4a2a-42ad-9319-cba19247e062", "jobName": "Daily Delta Backup of step-ca at 7:05pm", "message": "backup", "scheduleId": "a2229c74-dc47-42f6-90fd-a86ef7e6529d", "start": 1740978958075, "status": "failure", "end": 1740978959190, "result": {} }And when I went to the log entry under the Settings menu in Xen Orchestra, I saw an empty error message and this text when I clicked the eyeball icon to display details:
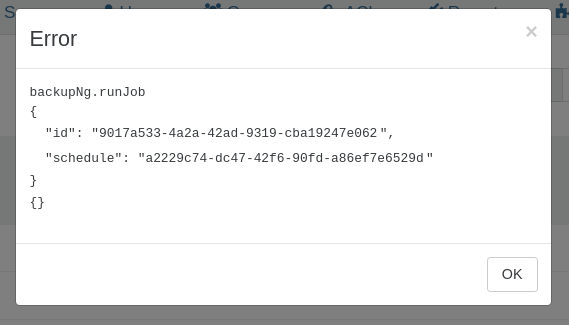
And it wasn't just one backup job either, over the course of the next day 3/4 backup jobs that all point to different shares on the same backup host were all failing -- but I hadn't made any changes to the shares or the underlying storage on that host so I really wasn't sure what could have caused it. Anyway it was the end of the weekend and time to go to bed.
This is all in my homelab so it's not a big deal if i miss backups for a few days, I was doing this on the weekend near the end of February and I knew I was a few days before an update which is probably when a number of last-minute approved commits get merged, so i figured I would wait a few days for the dust to settle and it would sort itself out after I update again once the next official release at the end of the month.
Just tonight I decided to update to the latest Xen Orchestra again, and my jobs still failed, like immediately with no error message. I did a bit of googling and found One of the backups fail with no error.
After skimming through I noticed their reported results were really similar to mine, but I hadn't restored from a backup and I didn't know what was wrong. I figured it would be just as easy for me to follow the same advice given, however: to recreate the job.
As I was referencing the schedule of the original job I noticed that the Health Check SR was in red text and just showed an unknown uuid which is when I realized that my backup jobs were still configured to restore Health Check VMs to the SR that I had destroyed and I had forgotten to update my jobs to restore to the new SR.
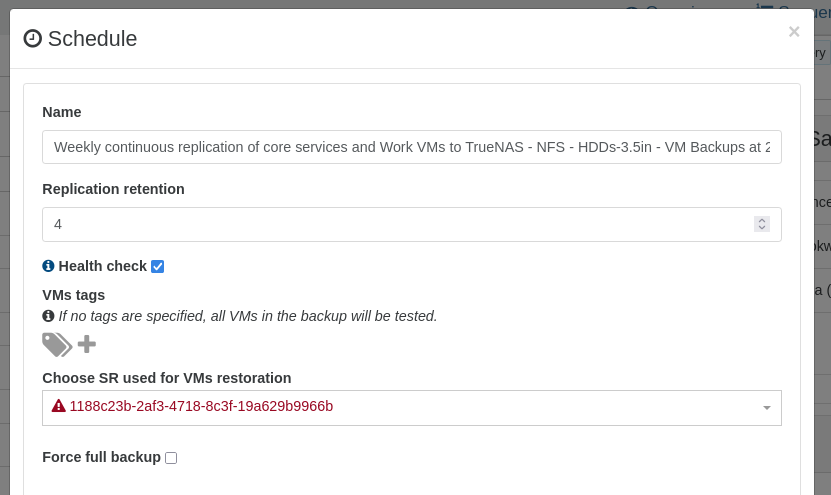
So, I am partially sharing a learning experience, and also report that the error handling for this situation ought to be improved.
I have replicated this many times in my instance and I would be happy to provide any logs that might be useful beyond what I've already included.
Anyway, thanks for making this awesome project open-source so people like me can tinker at home.
-
@techjeff said in Invalid Health Check SR causes Bakup to fail with no error:
but I hadn't made any changes to the shares or the underlying storage on that host so I really wasn't sure what could have caused it.
But you did make a change to the pool, you
@techjeff said in Invalid Health Check SR causes Bakup to fail with no error:
So I recently moved my vm disks to a new SR, made the new SR the pool default, and removed the previous SR.
So the issue is that a change was made and that there wasn't some sort of safety net on the home page to warn you to this blunder.
If you're modifying your SRs in any way shape or form, check that your backups are still "healthy" before you move on.
Could there be some sort of main-page or cookie-trail alert that something is off, certainly, maybe just a Yellow Triangle alert on the backup context menu..
-
@DustinB Yup, that's correct. I did it to myself!
 I overlooked that the SR I had removed was being utilized for restoring Health Check vms in that Backup job...and a few others too--yay homelab fun! lol
I overlooked that the SR I had removed was being utilized for restoring Health Check vms in that Backup job...and a few others too--yay homelab fun! lolNaturally, when I attempted to run the backup job it failed, presumably because it detected that the UUID of the Health Check SR was invalid / not in the database; however, the error I got was essentially a default or fallback without any context-specific details. This feels like XO attempted to run the job, detected that the UUID wasn't valid, but didn't have an specific error message to describe the exception or erroneous situation that was caught/encountered.
I agree that it would be extra nice if the cautionary yellow triangle used to denote warnings elsewhere in the application could be used to denote a backup job with one or more "invalid" configuration entries.
Also, my guess is that XAPI is unaware of the Health Checks beyond Xen Orchestra using discrete calls to facilitate the health check process, and if that's the case, the error is suspected by me to have be generated by Xen Orchestra. If that's the case, then I have hope that XO Devs could simply add an additional call to
xe sr-list uuid={health-check-sr-uuuid}for example to validate that the SR does in fact exist.I do quality assurance testing and report bugs for a living, but I'm not familiar with this exact codebase, so my message is intended for illustrative, inspirational purposes.
-
@DustinB said in Invalid Health Check SR causes Bakup to fail with no error:
but I hadn't made any changes to the shares or the underlying storage on that host so I really wasn't sure what could have caused it.But you did make a change to the pool, you
Correct... And, I spoke somewhat ambiguously. I was using the term "host" in the generic sense to describe the TrueNAS Scale that was hosting my backup SRs not in the sense of a proper xcp-ng host. In retrospect, NAS would have been more appropriate.
I have 2 TrueNASs, tns-01 and tns-02. tns-01 is the "primary" with solid state drives which hosts both the Old SR I had deleted and the new SR with which I replaced it. tns-02 is the "backup" with spinning drives and it hosts the SR where my backups are stored.
My backup Jobs backup to the Remotes on tns-02, but I use the primary SR backed with solid state drives for restoring health checks because I don't want to wait all night.
So I was confused because I hadn't modified any of the Remotes or shares or anything on tns-02, but because my backup jobs use the old SR that I had removed from tns-01, it failed and didn't give me much information to figure out why.
If I wanted to externalize the responsibility, I would probably attribute it to the Health Check configuration being inside the schedule configuration which has always seemed not intuitive to me, though that might just be my brain

-
@olivierlambert - I'm not sure who would be the best person at Vates to ping or whether there is another channel I should be using to request enhancements. I'm happy to be directed to the correct place if that's not here.
Despite the fact that I brought this upon myself...
 I do think that it would be nice if Xen Orchestra could improve the error handling/messaging for situations where a task fails due to an invalid object UUID. It seems like the UI is already making a simple XAPI call to lookup the name-label of the SR, which, upon failure results in the schedule where an invalid/unknown UUID is configured displaying the invalid/unknown UUID in Red text with a red triangle.
I do think that it would be nice if Xen Orchestra could improve the error handling/messaging for situations where a task fails due to an invalid object UUID. It seems like the UI is already making a simple XAPI call to lookup the name-label of the SR, which, upon failure results in the schedule where an invalid/unknown UUID is configured displaying the invalid/unknown UUID in Red text with a red triangle.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login