XCP-NG 8.3 freezes and / or reboot on HGR-SAP3 by Ovh / Using ZFS on Raid 50 / With deduplication
-
Hi all
First time with a competition's setup...
And a big step forward for meHGR-SAP-3 :
2x480 SSD Sata Soft RAID1
12x3.84To SSD SAS Hard RAID50
96 CPU : 2 x Intel Xeon Gold 6248R - 24c/48t - 3 GHz/4 GHz
768Go RAMPCI devices :
4x MT27800 Family [ConnectX-5] (Mellanox Technologies ConnectX-5 EN network interface card for OCP2.0, Type 1, with host management, 25GbE dual-port SFP28, PCIe3.0 x8, no bracket Halogen free ; MCX542B-ACAN)
RAID bus controller MegaRAID SAS-3 3324 [Intruder]VM in production :
14 VM
56 CPU
339 Gib
6.8 TiB (because of ZFS)
100% Windows environementAll VM are on my RAID50 ZFS disk
(zpool create -o ashift=12 -m // zfs set dedup=on //zfs set atime=off /zfs set sync=disabled (I remove the name ))xcp-ng 8.3 all patch on and 16 GiB (beacause using nfs SR)
Fist time for me with xcp-ng 8.3 and zfs I made a pool and one host in this pool bond network card
I dont't have a good practice for saving my VM, I made replication
If I don't do any save, xcp-ng is ok
I have a 400 Gb Orphan VDIs
When I made a replication of the VM this weekend the system freeze
I'm connect whith the IPMI and have this message (translation of my screenshot) :[ 0.099269] **CPU0: Unexpected LVT thermal interrupt!** [ 0.099271] do_IRQ: 0.162 No irq handler for vector [ 0.598711] efi: EFI_MEMMAP is not enabled. [ 2.561621] Out of memory: Kill process 117 (systemd-journal) score 18 or sacrifice child [ 2.561759] Killed process 117 (systemd-journal) total-um:34984kB, anon-rss: 276kB, file-rss:2572kB, shmem-rss:1208kB [ 2.562721] Out of memory: Kill process 281 (dracut-initqueu) score 13 or sacrifice child [ 2.562781] Killed process 291 (udevadm) total-um:32860kB, anon-rss: 280kB, file-rss:2404kB, shmem-rss: 0kB [ 2.565352] Out of memory: Kill process 281 (dracut-initqueu) score 13 or sacrifice child [ 2.565410] Killed process 281 (dracut-initqueu) total-um: 12124kB, anon-rss:596kB, file-rss:2452kB, shmem-rss:0kB [ 2.567166] Out of memory: Kill process 355 (systemd-journal) score 13 or sacrifice child [ 2.567224] Killed process 355 (systemd-journal) total-um: 30888kB, anon-rss: 252kB, file-rss:2596kB, shmem-rss:0kB [FAILED] Failed to start Journal Service. [ 2.568151] Out of memory: Kill process 277 (systemd-udevd) score 12 or sacrifice child [ 2.568209] Killed process 277 (systemd-udevd) total-um: 38980kB, anon-rss: 420kB, file-rss:2224kB, shmem-rss:0kB See 'systemctl status systemd-journald.service' for details. [ OK ] Stopped Journal Service. Starting Journal Service... [ 2.570273] Out of memory: Kill process 357 (systemd) score 3 or sacrifice child [ 2.570824] Out of memory: Kill process 359 (systemd) score 3 or sacrifice child [ 2.570322] Killed process 357 (systemd) total-um: 42884kB, anon-rss:636kB, file-rss: 0kB, shmem-rss: 0kB [ 2.570872] Killed process 359 (systemd) total-um: 42884kB, anon-rss:636kB, file-rss:0kB, shmem-rss: 0kB [ 2.571758] mlx5_core 0000:86:00.0: mlx5_function_setup: 1486: (pid 277): failed to allocate init pages [ OK ] Started dracut pre-mount hook. [FAILED] Failed to start Journal Service. See 'systemctl status systemd-journald.service' for details. [ OK ] Stopped Journal Service. Starting Journal Service... [ OK ] Started Journal Service. [ 2.596733] mlx5_core 0000:86:00.0: probe_one: 2136: (pid 277): mlx5_init_one failed with error code -12 [ 2.600905] mlx5_core 0000:1a:00.0: mlx5e_create_netdeu:7195: (pid 277): mlx5e_priv_init failed, err=-12 [ 2.601049] mlx5_core 0000:1a:00.0: mlx5e_probe: 7482: (pid 277): mlx5e_create_netdev failed [ 2.601205] mlx5_core 0000:1a:00.1: mlx5e_create_netdeu:7195: (pid 277): mlx5e_priv_init failed, err=-12 [ 2.601348] mlx5_core 0000:1a:00.1: mlx5e_probe: 7482: (pid 277): mlx5e_create_netdev failed [ 2.838490] megaraid_sas 0000:3b:00.0: Could not allocate memory for map info megasas_allocate_raid_maps:1620 [ 2.838786] megaraid_sas 0000:3b:00.0: Failed from megasas_init_fw 6392 [***] A start job is running for dev-disk-by\x2dlabel-root\x2dxrdbfu.device (1d 15h 49min 32s no limit)I don't see the CPU0: Unexpected LVT thermal interrupt! in all the xcp-ng log
I have all the log whith me
I power Off / On for reboot xcp-ng (8am)But whith all VM autostart "On" and an automatic task of "Garbage Collector for SR"
I have a lot off trouble
VM very slow and garbage task on a same time
xcp-ng freeze and crash with or not reboot 4 time between 12 and 13h
after second or third reboot I have time to disable the autostart of all VM and reboot VM one by one
I disable the backup task and xcp-ng don't reboot since monday afternoonIt's my second server by ovh the first one have other bug so I can change it but in fact I have the same problem of freeze and reboot
I'm just sure of the result (freeze and or crash) but not why it the beginning
The ultimate consequence was an out of memory of xcp-ngI have hundred Mo of log if you want something more
Perhaps I'm wrong and it's a hardare incompatibility ? (network card, hard raid...)
I have zabbix snmp probeThank's
-
Sorry title :
XCP-NG 8.3 freezes and / or reboot on HGR-SAP3 by Ovh
-
Hi,
You need to add more memory in your Dom0
-
Thank's.
Is it just a lack of memory for my Dom0 ?
What memory size do you recommend ?This is my production environment, so I'll have to wait before I can do that.
-
Because ZFS eats a lot of RAM, go with 32GiB in the Dom0.
-
@olivierlambert "
Tank's a lotI'll test it as soon as I can restart my host,
I've read a lot of messages saying that putting too much memory in Dom0 is counterproductive.
I'll keep you posted. -
It is, if you don't use ZFS. ZFS is a memory hog.
-
Last night, I put 32GiB on the Dom0.
For information, since I restarted, it's consuming approximately 17 GiB.
I'll see if the increased load expected this weekend and the next won't cause it to crash.
-
Great, keep us posted
")
-
Unfortunately, I'm really pessimistic about my technological choice.
Maybe I should never have installed ZFS on it, or perhaps I should have never enabled deduplication ?
I didn't have time to post this before, but Wednesday morning, after some major backups, I lost all my VMs for 3-5 minutes (lost, but no crash) due to overactivity on tapdisk.
Luckily I found them again after.
So I haven't lost anything except my sleep.
Here's an example of one of my 14 logs (14 VMs) (I've anonymized the UUIDs).
Sep 24 04:02:03: [04:02:03.958] tapdisk[728741]: log start, level 0 Sep 24 05:27:00: [05:27:00.943] tapdisk_vbd_check_progress: vhd:/var/run/sr-mount/myZFSraid50/diskVM1.vhd: watchdog timeout: pending requests idle for 624 seconds Sep 24 05:27:00: [05:27:00.943] tapdisk_vbd_debug: vhd:/var/run/sr-mount/myZFSraid50/diskVM1.vhd: state: 0x00000000, new: 0x00, pending: 0x06, failed: 0x00, completed: 0x00, last activity: 1758683796.081829, errors: 0x0000, retries: 0x00c2, received: 0x000f9b42, returned: 0x000f9b3c, kicked: 0x0439e111 Sep 24 05:27:00: [05:27:00.943] vhd_debug: /var/run/sr-mount/myZFSraid50/diskVM1.vhd: QUEUED: 0x000871bb, COMPLETED: 0x000871b5, RETURNED: 0x000871b4 Sep 24 05:27:00: [05:27:00.943] vhd_debug: WRITES: 0x000437db, AVG_WRITE_SIZE: 28.221727 Sep 24 05:27:00: [05:27:00.943] vhd_debug: READS: 0x000439e0, AVG_READ_SIZE: 23.678925 Sep 24 05:27:00: [05:27:00.943] vhd_debug: ALLOCATED REQUESTS: (352 total) Sep 24 05:27:00: [05:27:00.943] vhd_debug: 92: vreq: xenvbd-14-768.67.0, err: 0, op: 2, lsec: 0x02d74e6f, flags: 0, this: 0x1b02ed0, next: (nil), tx: (nil) Sep 24 05:27:00: [05:27:00.943] vhd_debug: 150: vreq: xenvbd-14-768.67.0, err: 0, op: 2, lsec: 0x01b7f720, flags: 0, this: 0x1b07580, next: (nil), tx: (nil) Sep 24 05:27:00: [05:27:00.943] vhd_debug: 190: vreq: xenvbd-14-768.67.0, err: 0, op: 2, lsec: 0x01879d78, flags: 0, this: 0x1b0a640, next: (nil), tx: (nil) Sep 24 05:27:00: [05:27:00.943] vhd_debug: 220: vreq: xenvbd-14-768.67.0, err: 0, op: 2, lsec: 0x02d74ec7, flags: 0, this: 0x1b0cad0, next: (nil), tx: (nil) Sep 24 05:27:00: [05:27:00.943] vhd_debug: 235: vreq: xenvbd-14-768.67.0, err: 0, op: 2, lsec: 0x02d74ee7, flags: 0, this: 0x1b0dd18, next: (nil), tx: (nil) Sep 24 05:27:00: [05:27:00.943] vhd_debug: 259: vreq: xenvbd-14-768.67.0, err: 0, op: 2, lsec: 0x18f628e2, flags: 10, this: 0x1b0fa58, next: (nil), tx: 0x1af8a68 Sep 24 05:27:00: [05:27:00.943] vhd_debug: BITMAP CACHE: Sep 24 05:27:00: [05:27:00.943] vhd_debug: 0: blk: 0x2d74, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afb228, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 1: blk: 0x34f2b, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afb080, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 2: blk: 0x1bdb, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afaed8, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 3: blk: 0xd237, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afad30, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 4: blk: 0x072f, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afab88, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 5: blk: 0x0740, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afa9e0, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 6: blk: 0x8a08, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afa838, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 7: blk: 0x0773, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afa690, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 8: blk: 0x3ee8, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afa4e8, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 9: blk: 0x1b7f, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afa340, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 10: blk: 0x070e, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1afa198, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 11: blk: 0x11512, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af9ff0, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 12: blk: 0x26ca, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af9e48, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 13: blk: 0xe6f3, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af9ca0, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 14: blk: 0x0fc2, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af9af8, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 15: blk: 0x1c900, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af9950, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 16: blk: 0x96ac, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af97a8, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 17: blk: 0x0790, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af9600, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 18: blk: 0x0734, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af9458, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 19: blk: 0x0752, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af92b0, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 20: blk: 0x0732, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af9108, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 21: blk: 0x1c1bd, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af8f60, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 22: blk: 0xfc4c, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af8db8, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 23: blk: 0x1d0d, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af8c10, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 24: blk: 0x18f62, status: 0x0000000a, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 8, in use: 1, tx: 0x1af8a68, tx_error: 0, started: 1, finished: 1, status: 1, reqs: 0x1b0fa58, nreqs: 1 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 25: blk: 0x1960b, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af88c0, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 26: blk: 0x134b, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af8718, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 27: blk: 0x1bbb, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af8570, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 28: blk: 0x1879, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af83c8, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 29: blk: 0x076a, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af8220, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 30: blk: 0xb73b, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af8078, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: 31: blk: 0x0731, status: 0x00000000, q: (nil), qnum: 0, w: (nil), wnum: 0, locked: 0, in use: 0, tx: 0x1af7ed0, tx_error: 0, started: 0, finished: 0, status: 0, reqs: (nil), nreqs: 0 Sep 24 05:27:00: [05:27:00.943] vhd_debug: BAT: status: 0x00000000, pbw_blk: 0x0000, pbw_off: 0x00000000, tx: (nil) Sep 24 05:27:00: [05:27:00.943] vhd_debug: /run/sr-mount/myZFSraid50/disk_an_other_VM.vhd: QUEUED: 0x00099bd9, COMPLETED: 0x00099bd9, RETURNED: 0x00099bd9 Sep 24 05:27:00: [05:27:00.943] vhd_debug: WRITES: 0x00000000, AVG_WRITE_SIZE: 0.000000 Sep 24 05:27:00: [05:27:00.943] vhd_debug: READS: 0x00099bd9, AVG_READ_SIZE: 23.188253 Sep 24 05:27:00: [05:27:00.943] vhd_debug: ALLOCATED REQUESTS: (352 total) Sep 24 05:27:00: [05:27:00.943] vhd_debug: BITMAP CACHE: Sep 24 05:27:00: [05:27:00.943] vhd_debug: BAT: status: 0x00000000, pbw_blk: 0x0000, pbw_off: 0x00000000, tx: (nil) Sep 24 05:27:01: [05:27:01.910] watchdog_cleared: vhd:/var/run/sr-mount/myZFSraid50/diskVM1.vhd: watchdog timeout: requests were blocked Sep 24 06:03:03: [06:03:03.461] tapdisk_vbd_check_progress: vhd:/var/run/sr-mount/myZFSraid50/diskVM1.vhd: watchdog timeout: pending requests idle for 11 seconds Sep 24 06:03:04: [06:03:04.400] watchdog_cleared: vhd:/var/run/sr-mount/myZFSraid50/diskVM1.vhd: watchdog timeout: requests were blocked Sep 24 06:10:47: [06:10:47.027] tapdisk_vbd_check_progress: vhd:/var/run/sr-mount/myZFSraid50/diskVM1.vhd: watchdog timeout: pending requests idle for 11 seconds Sep 24 06:10:48: [06:10:48.416] watchdog_cleared: vhd:/var/run/sr-mount/myZFSraid50/diskVM1.vhd: watchdog timeout: requests were blocked Sep 24 06:27:16: [06:27:16.740] tapdisk_vbd_check_progress: vhd:/var/run/sr-mount/myZFSraid50/diskVM1.vhd: watchdog timeout: pending requests idle for 100 seconds Sep 24 06:27:18: [06:27:18.465] watchdog_cleared: vhd:/var/run/sr-mount/myZFSraid50/diskVM1.vhd: watchdog timeout: requests were blocked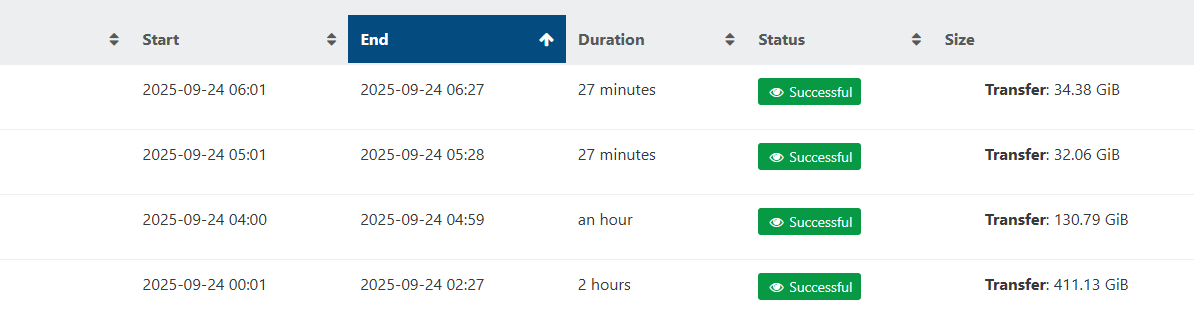
Finally, when I say massive backups, my hypervisor is at 50% of its occupancy rate.
And this weekend, I'm thinking of skipping all the scheduled backup tasks to be on the safe side.
I don't know what to think anymore
-
Probably worth trying regular local ext SRs (in mdadm if needed) and see how it behave. KISS principle is very strong in general.
-
Unfortunatly this is also my conclusion.
This is what I used to do with smaller servers.
This is the first time with such a "huge server" + hardware RAID + ZFS with dedup.Thanks
Have a nice day -
It will be a lot better with future SMAPIv3 drivers (it might include ZFS if we want to officially support it)
-
Do you think the problem could be due to ZFS deduplication ?
I just saw that it's possible to disable deduplication "without restarting" .
I think my problem is due to excessive disk writes (adding then deleting a snapshot, then coalescing?)
Without deduplication, less disk usage ?Or am I wrong ?
-
In general, at least the consensus, is to NOT use deduplication with ZFS. It's probably one cause of the issue, yes. It's not worth the RAM needed.
-
Yes, I should probably create a new post ?
To discuss and "to survive" : how to make my current server usable again- starting by testing with deduplication turned off.
-
Let's continue there, you can always rename your thread
-
Okay, but I can't edit the subject.
-
You can edit your first post, which contains the title
-
@olivierlambert said in HCP-NG 8.3 freezes and / or reboot on HGR-SAP3 by Ovh:
You can edit your first post, which contains the title
thanks a lot
I'll wait until next week to disable deduplication (never on Friday
") )
)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login