host crash - guest_4.o#sh_page_fault__guest
-
How many VMs were running there?
PV VM list =>
# xe vm-list PV-bootloader=pygrub -
Found that your package is missing a critical patch https://xenbits.xen.org/gitweb/?p=xen.git;a=patch;h=ab6d56c4cac1498f20e5cde99a6e8af5f45d2bb0 or XSA-280.
There is a check in place to avoid this crash.
diff --git a/xen/arch/x86/mm/shadow/multi.c b/xen/arch/x86/mm/shadow/multi.c index cb24a0fdef..1ec3e35d20 100644 --- a/xen/arch/x86/mm/shadow/multi.c +++ b/xen/arch/x86/mm/shadow/multi.c @@ -3314,8 +3314,8 @@ static int sh_page_fault(struct vcpu *v, /* Unshadow if we are writing to a toplevel pagetable that is * flagged as a dying process, and that is not currently used. */ - if ( sh_mfn_is_a_page_table(gmfn) - && (mfn_to_page(gmfn)->shadow_flags & SHF_pagetable_dying) ) + if ( sh_mfn_is_a_page_table(gmfn) && is_hvm_domain(d) && + mfn_to_page(gmfn)->pagetable_dying ) { int used = 0; struct vcpu *tmp; @@ -4256,9 +4256,9 @@ int sh_rm_write_access_from_sl1p(struct domain *d, mfn_t gmfn, ASSERT(mfn_valid(smfn)); /* Remember if we've been told that this process is being torn down */ - if ( curr->domain == d ) + if ( curr->domain == d && is_hvm_domain(d) ) curr->arch.paging.shadow.pagetable_dying - = !!(mfn_to_page(gmfn)->shadow_flags & SHF_pagetable_dying); + = mfn_to_page(gmfn)->pagetable_dying; sp = mfn_to_page(smfn); @@ -4575,10 +4575,10 @@ static void sh_pagetable_dying(struct vcpu *v, paddr_t gpa) smfn = shadow_hash_lookup(d, mfn_x(gmfn), SH_type_l2_pae_shadow); } - if ( mfn_valid(smfn) ) + if ( mfn_valid(smfn) && is_hvm_domain(d) ) { gmfn = _mfn(mfn_to_page(smfn)->v.sh.back); - mfn_to_page(gmfn)->shadow_flags |= SHF_pagetable_dying; + mfn_to_page(gmfn)->pagetable_dying = 1; shadow_unhook_mappings(d, smfn, 1/* user pages only */); flush = 1; } @@ -4615,9 +4615,9 @@ static void sh_pagetable_dying(struct vcpu *v, paddr_t gpa) smfn = shadow_hash_lookup(d, mfn_x(gmfn), SH_type_l4_64_shadow); #endif - if ( mfn_valid(smfn) ) + if ( mfn_valid(smfn) && is_hvm_domain(d) ) { - mfn_to_page(gmfn)->shadow_flags |= SHF_pagetable_dying; + mfn_to_page(gmfn)->pagetable_dying = 1; shadow_unhook_mappings(d, smfn, 1/* user pages only */); /* Now flush the TLB: we removed toplevel mappings. */ flush_tlb_mask(d->domain_dirty_cpumask);Check your yum logs for last updates on hypervisor
# cat /var/log/yum.log* | grep xen-hypervisor -
It's a fresh installed XCP-ng 7.6 (last week), did a yum update after install. Weird .... I look and come back in a minute.
yum list installed | grep xen-hyper xen-hypervisor.x86_64 4.7.6-6.3.1.xcp @xcp-ng-updateshmm......

-
Ok, it's clear now!
I installed all updates, but did not reboot this host
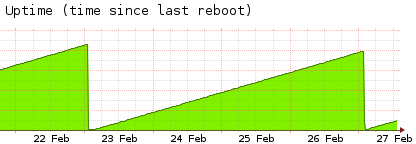
 I can see this on my uptime graph and the install time:
I can see this on my uptime graph and the install time:cat /var/log/yum.log* | grep xen-hypervisor Feb 18 14:35:33 Installed: xen-hypervisor-4.7.6-6.2.1.xcp.x86_64 Feb 24 02:34:04 Updated: xen-hypervisor-4.7.6-6.3.1.xcp.x86_64Host did not reboot after installation of the updates on Feb 24, Crash was in the night from Feb 26 to Feb 27:
@ri many thanks to you!
-
Crash happened again, this time with
Xen version: 4.7.6-6.3.1.xcpLet me wake up fully
 ... Details will follow....
... Details will follow.... -
Woah! Something serious.. Eager.
-
@r1 hhm.....
-
Exact same situation here.
2 different host both crashed, I suspect is one of the vm because I've moved them from the first one that crashed to second one.
Let me know if you found something to address this issue.
Many thanks. -
@Steve_Sibilia @borzel I think you need to update hosts. https://xcp-ng.org/forum/post/9343
-
I already updated it.
[root@vivhv11 20190301-211627-CET]# rpm -q openvswitch
openvswitch-2.5.3-2.2.3.3.xcpng.x86_64
and it crashed afterward. -
Ok.. so its not related then.
Do you have other leads - such as crash logs or kern.log to guess?
-
Yes,
here: https://cloud.sinapto.net/index.php/s/13nUsnunRKmdUBC
you can find crash log. For what I can understand it is related to an host which was pv with an older version of the tools (7.2). After last crash I've update tools to the latest version hoping that this will fix the issue.
All the crashes (4 so far, on 2 different xcp hosts) happened outside peak hours for our infrastructure (friday evening after business hours and saturday during lunch) so I don't think is load average related but I'm not certain about it.
Let me know if you need further informations.
Thanks
Steve -
Guest tools should not be able to crash host - it will be treated as critical bug. Your stack is similar to that of reported earlier. And even though you have updated Xen version, the trigger could be something else...
-
FWIW, it appears that my fully patched 7.6 xcp host also rebooted the morning of 2/27
System Booted: 2019-02-27 04:46
I haven't dug into the logs yet.
-
@Steve_Sibilia @Danp @borzel can you share
# xenpm get-cpuidle-statesand BIOS power saving settings? -
Here the cpuidlestates.txt. Unsure how to get the BIOS settings without rebooting.
-
@r1 yes for sure.
Here: https://cloud.sinapto.net/index.php/s/0X8GdLxnTrw6bmd the output pf get-cpu-idle-states.
Power management is set up for maximun performance, power cap is disabled.
The system is a Dell poweredge r640.
Let me know if you need more details.
Steve -
While digging on multiple things I'm curious on one patch
https://xenbits.xen.org/gitweb/?p=xen.git;a=commit;h=9dc1e0cd81ee469d638d1962a92d9b4bd2972bfa
It seems to have been applied on
But its not there on
and
And I think this could have relation of the host crash mentioned above. The function
guest_walk_to_gfnis used instable-4.7but not at places mentioned by this specific patch.Will try to find more on this, my tomorrow.
-
A quick update.
This morning we had another crash. Same host, same guest involved. -
You can try this workaround: boot your host with the "pcid=0" parameter. This will likely have an impact on performance but should avoid the crash.
Reference: https://lists.xenproject.org/archives/html/xen-devel/2019-01/msg00006.html