Hosts fenced, new master, rebooted slaves not reconnecting to pool
-
I'm doing a bit of labbing this friday evening and I ran into a scenario I haven't encountered before and I just wanted to see if this is a bug or if im just being unlucky.
7st virtual xcp-ng 8.3 vm's running on a physical xcp-ng 8.3, all vm's have nested virtualization enabled.
I fired up some VM's in the pool to try the load balancer out, by running some "benchmark"-scripts within the vm's to create some load.
After a while 3/7 hosts failed, because of not enough ram (only 4gb per VM) which isn't really that strange, but after they failed they're not able to "connect" to the pool again: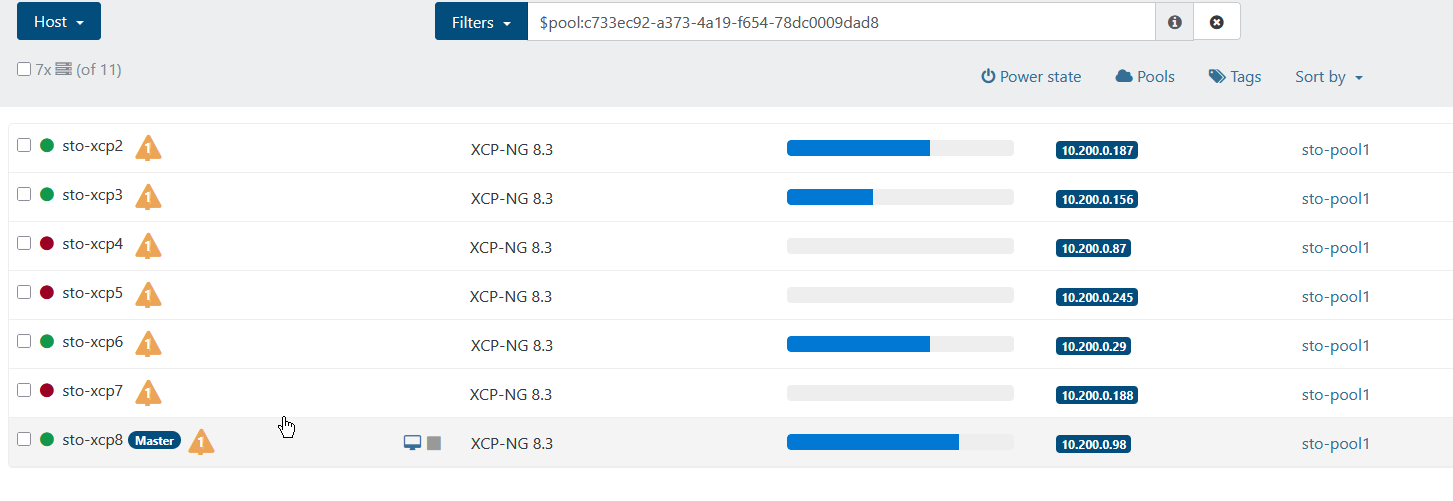
I then went to the sto-xcp7 vm and checked the pool.conf, only to see that it actually listed sto-xcp8 (which is the master after the fencing):
[17:48 sto-xcp7 ~]# cat /etc/xensource/pool.conf
slave:10.200.0.98[17:49 sto-xcp7 ~]#I can also go the host in XO and see that it's "halted" but yet, it displays the console:
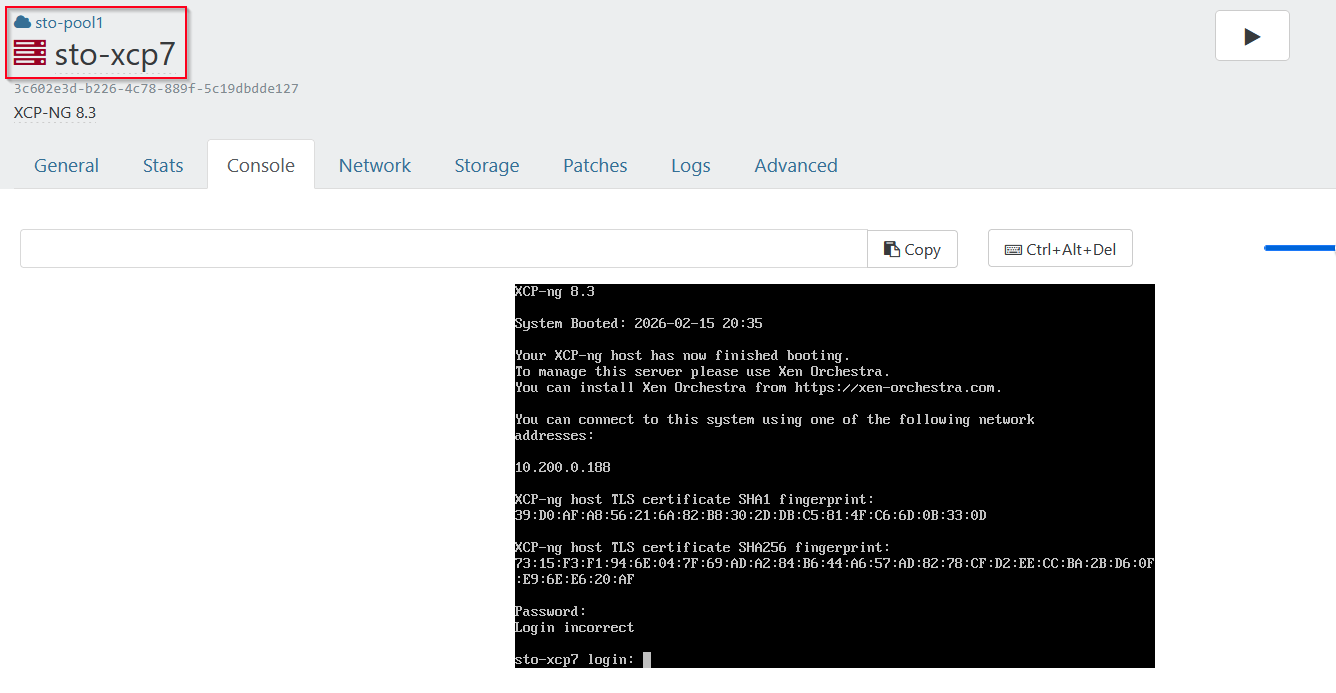
Just for a sanity check, I checked xcp-ng center as well, and it agrees with XO, that the hosts are offline:
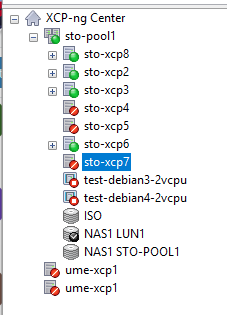
Is this a bug or what's actually going on? I tried rebooting the failed hosts, without any luck. Any pointers on where to look?
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login