Alert: Control Domain Memory Usage
-
@stormi said in Alert: Control Domain Memory Usage:
Before I realized that not every affected host was using the
ixgbedriver, contrarily to what I initially thought, I built an alternate driver from the latest sources from Intel.So, even if there's little hope that it will fix anything, here's how to install it (on XCP-ng 8.1 or 8.2):
yum install intel-ixgbe-alt --enablerepo=xcp-ng-testing rebootHas anyone tested the updated ixgbe driver?
-
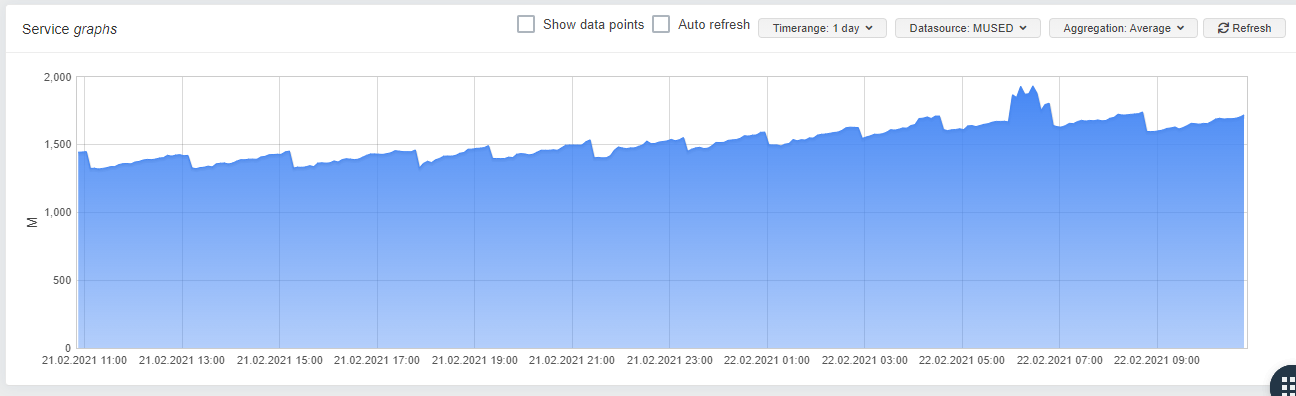
I upgraded a pool which was affected from 8.1 to 8.2 this weekend and installed the driver on one of the Hosts. Its a little early, but as you can see, there seems to be a difference in the memory usage:
Stock Driver
Stromis Driver:
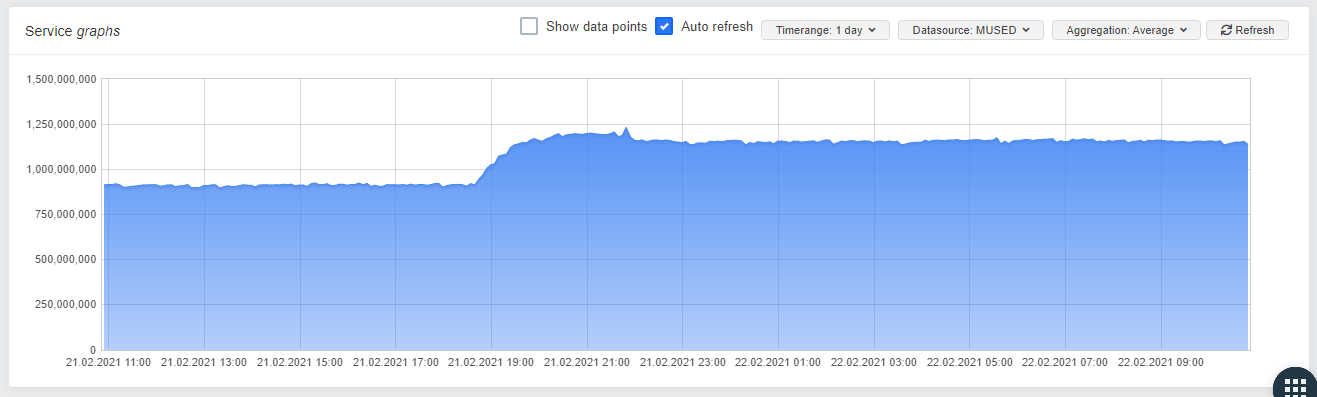
One can allready see a constanty, slowly growing mem-usage in "small steps" on the Server with the stock driver, wheras the server with stormis driver seems to be stable.
-
Indeed, sounds better in any case! Thanks a lot @dave for the feedback.
For everyone else with the issue: please try the same and report. Maybe we found the culprit!
-
That's really likely the problem all along.
See https://sourceforge.net/p/e1000/bugs/633/#af80/154d
So our alt driver is indeed fixing it
")
-
Good job guys!
-
A big thanks for the link that @andyhhp provided to confirm the problem
-
I have installed intel-ixgbe-alt-5.9.4-1.xcpng8.1.x86_64 on my server (268).
I'll check in some days if I still have the problem or not.Thank you guys!
-
@olivierlambert is there a plan to deploy the alt-driver over the xcp-ng update or should we installed by the xcp-ng-testing repo?
THX for the good job guys

-
I'm going to build a driver package that only has the patch that is thought to fix the memory issue and let everyone here test it. If the results are good, then it will become an official update.
-
@stormi
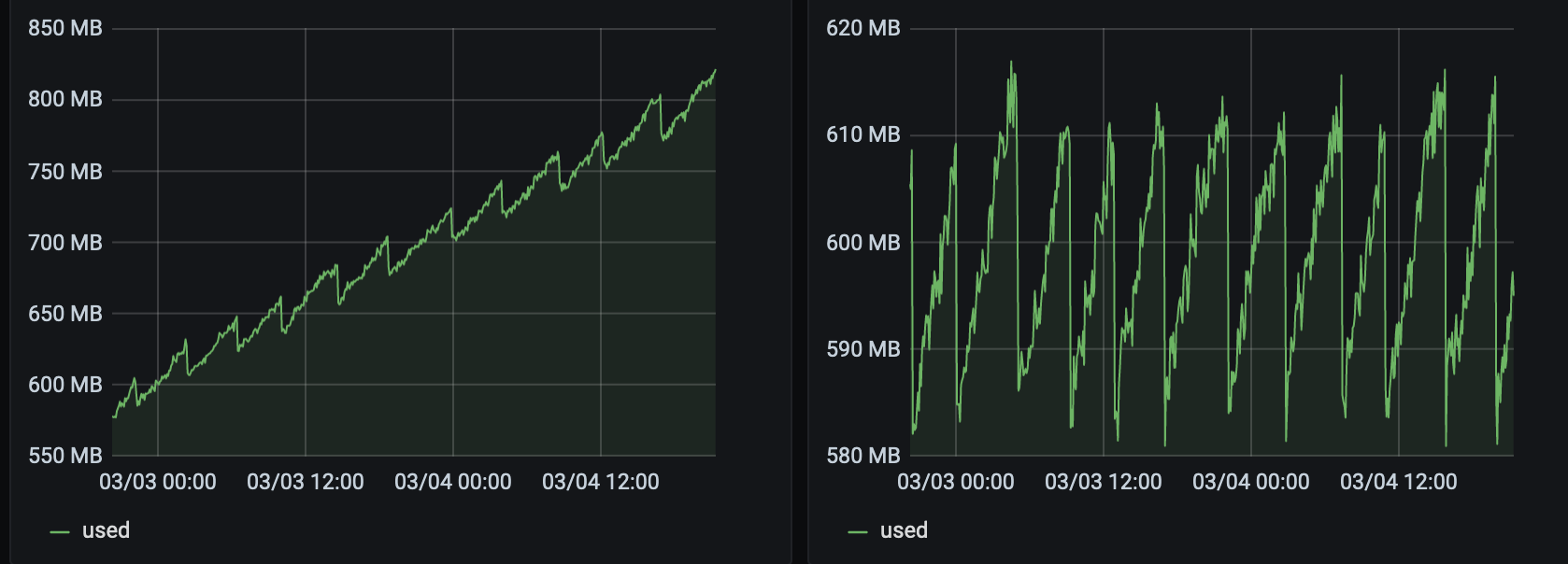
The 2 servers have been reinstalled with an up to date 8.2. They host each 2 VMs that are doing the same thing (~100Mb/s of netdata stream).The right one has the 5.9.4-1.xcpng8.2, the left one has 5.5.2-2.xcpng8.2.
The patch seem to be OK for me.
-
Announcement
Here's an updated
ixgbedriver package that is meant as an update candidate without updating to a higher version. If need all feedback we can get on this one, because this is the candidate for the official fix as would be delivered to everyone. Of course theintel-igb-altwill remain available for those who need a more recent driver, and I even moved it to theupdatesrepository so that one doesn't need to add--enablerepo=xcp-ng-testingto install it anymore.To test the official update candidate on XCP-ng 8.1 or 8.2.
- If you had previously installed
intel-ixgbe-alt:yum remove intel-ixgbe-alt -y- Check that the
/lib/modules/4.19.0+1/override/ixgbe.kofile was properly deleted. I've seen, once, a situation where a .ko file from an-altpackage wasn't deleted, so I'm being cautious here and ask you to report you see that it is still present. In theory, this is impossible, but as I've seen it once I don't know anymore - Run
depmod -a
- Update the
intel-ixgbepackage from the testing repo:yum update intel-ixgbe --enablerepo=xcp-ng-testing - Reboot
Note: I'm not 100% sure that I picked the right patch, nor that this patch alone is sufficient.
- If you had previously installed
-
@stormi I have installed intel-ixgbe 5.5.2-2.1.xcpng8.2 on my server s0267. Let's wait a some days to check if the memleak is solved by this patch.
-
@stormi
It seems to be good here!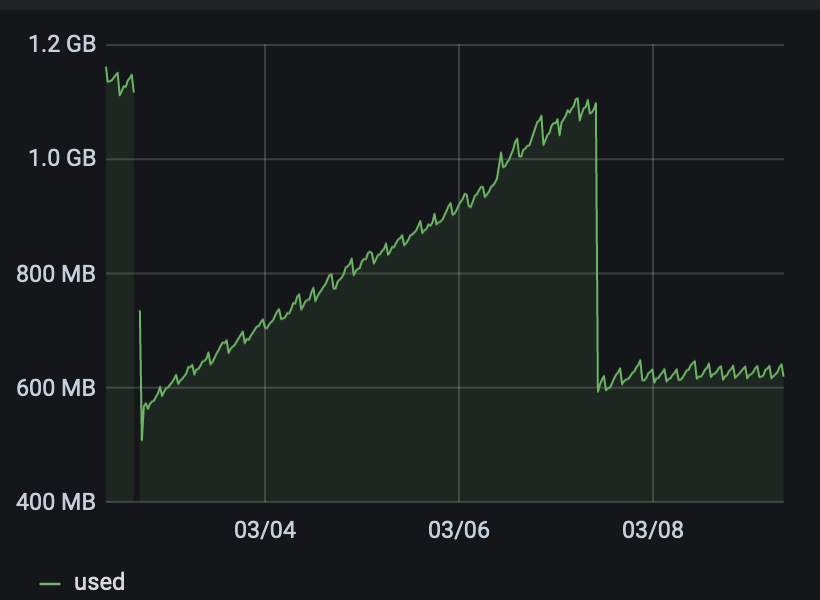
-
So we found the good patch
That was a really tricky issue to find! -
Once again, an issue that was present in vendor drivers but not in the mainline kernel. It's becoming harder and harder to trust vendor drivers. But that's what they require for support...
-
Our Citrix ticket has been worked and they concluded that the NIC driver is to blame here as well. They had us collect debug info using:
/opt/xensource/libexec/xen-cmdline --set-dom0 page_owner=onThey then confirmed the memory leak was from the NIC driver. They are intending to release a public hotfix for this issue.
-
Nice to see Citrix are also getting to the same conclusions
edit: thanks @fasterfourier for your feedback!
-
Official Citrix update has been posted: https://support.citrix.com/article/CTX306529
-
\o/
What I still find really weird is the fact we had report of the issue far longer before Citrix. And we had roughly 10 people affected while Citrix got only 1 report

-
Probably plenty of Citrix customers were affected, but they would rather reboot on schedule than spend months working through the support process
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login