-
@stormi installed on our pool hosts. Hosts boot normal. No vm boot issue Linux and Windows.
-
I have pushed the update to the
updatesrepo. Security bulletin should follow shortly on the blog. -
Installing now, seems to run fine.
-
Announcement live: https://xcp-ng.org/blog/2019/05/21/xcp-ng-security-bulletin-mds-hardware-vulnerabilities-in-intel-cpus/
Was a long write but should be a short read
")
-
I just released a batch of updates for XCP-ng 7.6. It is not a security update (except the
microcode_ctlupdate which brings updated microcode from Intel for some CPUs, such as the SandyBridge family).Here's the list:
microcode_ctl-2.1-26.xs5.1.xcpng: updated microcodes from Intel regarding the MDS attacks. They mainly include microcodes for the SandyBridge family of CPUs which were not available previously.sm-1.25.0-1.0.3.el7.centos:- partial ext4 and XFS support for local storage. Nothing new if you already installed the update candidate previously, I'm just pushing it to everyone. Installing the experimental
sm-additional-driverspackage is still required if you want to use such filesystems in local storage repositories. - NFS 4.1 support
- partial ext4 and XFS support for local storage. Nothing new if you already installed the update candidate previously, I'm just pushing it to everyone. Installing the experimental
xapi-1.110.1-1.7.xcpng:- enables storage migration during pool upgrade. Will allow storage migration when upgrading a pool from 7.6 to 8.0 or later. Tested on a few VMs, but we can't promise zero risk, so, as usual, backup before and start with the less critical VMs. If you have shared storage, move your VMs to shared storage before the pool upgrade, this will save you much work. Or turn the VMs down if you can afford it.
- automatically opens the VxLAN network port for XAPI to use it. This is needed to use VxLAN with the new SDN controller from Xen Orchestra.
xcp-emu-manager-1.1.2-1.xcpng: new implementation of xcp-emu-manager, the same as the one that has been tested in XCP-ng 8.0 beta. Might fix a few corner cases, but overall what's expected is that it just works as well as before, and provides better logs if anything goes wrong.xcp-ng-generic-lib-1.1.1-1.xcpng: a dependency of the new xcp-emu-managerxenopsd-0.66.0-1.1.xcpng: fixes live migration from older releases when the VM has no platform:device_id defined (see upstream bug).xcp-ng-updates_testingrepository. Thanks to lavamind for helping me debug this over IRC.xcp-ng-xapi-plugins-1.4.0-1.xcpng: replaces xcp-ng-updater. Includes the updater plugin that allows Xen Orchestra to install updates, as well as the new ZFS pool discovery plugin and the HyperThreading detection plugin (see latest Xen Orchestra blog post)xcp-ng-deps-7.6.0-5: update needed due to the renaming of xcp-ng-updater into xcp-ng-xapi-plugins
Some updates bring no change from user point of view. This is just some needed clean-up of the packaging, and I'm using the opportunity offered by this batch of update to include them:
conversion-plugin-8.0.0-1.1vendor-update-keys-1.3.6-1.1
Note that most of these update candidates have been available for a long time (months), but I did not get enough feedback so it had to wait until I was able to give them more testing myself. So don't hesitate to subscribe to this thread, make sure e-mail notifications are active, and take part in the testing of updates candidates to help us release in a timely manner.
As a reminder, the security update for XCP-ng 7.5 regarding MDS attacks, that took one of our developers some time to backport, is still an update candidate that can't be pushed to everyone unless it gets tested by the community (but maybe there's no real need to update it).
-
@stormi I've just done
yum update(Complete!) and rebooted.
Seems OK.Comparing before and after the reboot, the only differences in output of
xl dmesg(apart timestamps) are:< Detected 3504.246 MHz processor. --- > Detected 3504.212 MHz processor. < Init. ramdisk: 000000026ee32000->000000026ffff04b --- > Init. ramdisk: 000000026ee32000->000000026ffff164Also, microcodes don't seem to be newer:
# xl dmesg | grep -i microcode (XEN) [ 0.000000] microcode: CPU0 updated from revision 0x8e to 0xb4, date = 2019-04-01 (XEN) [ 18.296976] microcode: CPU2 updated from revision 0x8e to 0xb4, date = 2019-04-01 (XEN) [ 18.373666] microcode: CPU4 updated from revision 0x8e to 0xb4, date = 2019-04-01 (XEN) [ 18.450559] microcode: CPU6 updated from revision 0x8e to 0xb4, date = 2019-04-01but it's OK, isnt it?
-
@MajorTom only some microcodes have been updated since the last microcode update, yes.
-
@stormi just updated.
After the upgrade the reboot of the master failed with this screen: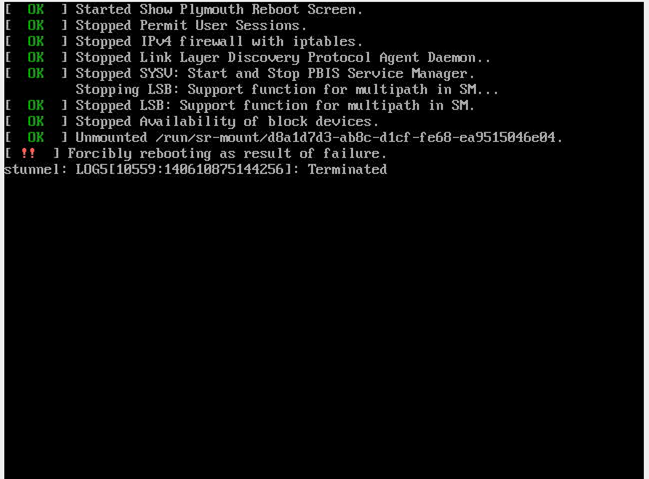
-
@maxcuttins Is there anything in the logs that would give information on what the "failure" was?
-
I'm trying to find the log
-
Another error while I was live migrating a VM from an host to another to reboot the host that need rebooting after the upgrade.
Migrating VM 'XXXXXX'
Internal Error:
Xenops_interface.Internal_error("Domain.Emu_manager_failure("Received error from emu-manager:xenguestInvalid Argument")") -
@maxcuttins Could you produce a system status report (on both hosts), upload them somewhere and send the link to me (in private if you prefer the host data not to be publicly available)?
-
So after a look at the logs, we are not sure where the issue comes from. Could be caused by faulty DIMM RAM because there are error messages related to RAM errors (but it's ECC RAM and it claims to have corrected them), but we're not sure.
-
I have withdrawn the update to
xenopsd.It does fix live migration from older releases when the VM has no platform:device_id defined (see upstream bug), but causes a transient live migration error during the update when the hosts have different patch levels. If you already installed the update and rebooted your hosts no problem, you're already past the issue. If you installed it but haven't moved your VMs around to reboot your hosts, make sure all your hosts have the same patch level and restart their toolstacks before migrating VMs. If you haven't installed the update but you want to install it, it is still available in the
xcp-ng-updates_testingrepository. Thanks to lavamind for helping me debug this over IRC. -
@stormi could you provide some more details about the "transient live migration error" with the xenopsd update?
I have been experiencing issues live migrating larger VM's (20-40GB Ram) especially when the memory is in active use (eg MariaDB database). As far as I can tell my issue is related to the VM dynamic memory being reduced to below the actual memory use of the VM at which point a random processes crash - but not sure why this is happening since both the source and target XCP host are under allocated on memory. We upgraded all hosts in the pool before xenopsd was withdrawn and are currently scheduling in downtime for each VM so we can migrate them in an off state which seems to bypass the issue.
-
@Digitalllama The issue you had is probably not related to that update. If that was caused by the update, then you'd have seen the VM reboot at the end of the migration process and it would have been duplicated on both hosts.
A dynamic memory minimum value set too low can cause the kind of process crash you experienced: the available memory for the VM being low, you may reach a point where the VM's kernel needs to fire the Out Of Memory Killer which will select a running process and kill it. If you want to be sure about that, you can try to set the same value for minimum and maximum dynamic memory and see if the migration issue still occurs.
-
To people not having updated their hosts yet with the latest update: wait a few more days! There's a kernel security update on its way, so you'll probably want to reboot only then.
Note that the security update will be mostly useful for people who put their hosts on a network that is reachable from a potential attacker.
-
The new kernel update candidate is available. As usual, I need some feedback before I can push it to everyone.
Citrix advisory: https://support.citrix.com/article/CTX256725
- XCP-ng 7.5: install it with
yum update kernel --enablerepo='xcp-ng-updates_testing' - XCP-ng 7.6: install it with
yum update kernel --enablerepo='xcp-ng-updates_testing' - XCP-ng 8.0 beta/RC1: simply
yum update
It is a security update. A distant attacker could manage to crash your host or raise its memory usage significantly with specially crafted network requests. Hosts isolated from public networks are safe, unless the attacker managed to get into your private network.
Reboot required (we do not support live patching at the moment, due to a closed source component in XenServer / Citrix Hypervisor).
Edit: update pushed: https://xcp-ng.org/blog/2019/07/12/xcp-ng-security-bulletin-kernel-update-sack-vulnerability/
- XCP-ng 7.5: install it with
-
Anyone available to test the security update on 7.5 and/or 7.6? It is a security update, so quite urgent.
-
Installed it a view minutes ago. Will report back.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login