continuous replication job - no progress
-
I am struggling to get my continous replication job to work. I have tried many and none have succeeded. From what I've read, this should be simple and easy to configure, so I'm not sure what I'm missing.
I have the job configured in smart mode grabbing all vms with tag "Core" with the typical tag exclusions: Continuous Replication, Disaster Recovery, XOSAN, XOA Proxy.
I my current test configuration I am trying to replicate vms running on shared NFS storage to the local storages on each of my two xcp-ng hosts hosts.
After manually starting the job, I just get a series of [XO] Importing/Exporting VDI content... tasks, but no progress is ever displayed and not all VMs that should be included are being exported/imported. I am watching the real-time traffic via my TrueNAS Core dashboard, and there is basically no traffic being passed.
I'm a bit stuck. Any advice is appreciated! Thanks in advance.
-
@olivierlambert I just confirmed that I am indeed tracking
master. I am using a third party tool that basically follows the steps in your doc. I understand you have no obligation to support any procedure other than the official doc, but I do appreciate your suggestions and insights -- this is a home system, nothing is running in "production" per se, but I like when I can get things workin as expected")
I have updated to latest commit on master and rebuilt, I can confirm that my continuous replication to my local storage is working. Once that completes, I'll try replication to my NFS shared SR as well. Assuming that works, I'll try my metadata backup to my NFS Remotes, then finally I'll share my results here.
Thanks again!
-
@techjeff Did you set the Pools settings in smart mode? Does your SR target has enough space? Check XO -> Settings -> Logs. Does disabling smart mode work?
-
@tony thanks for the reply. Yes, the pool settings are set to Smart Mode.
All of my target SRs are thin-provisioned, the smallest has ~899GB, I'm attempting to back up 5 vms and the collective disk size is less than 250GB (not to mention that most of these disks are full to less than 2GB)
I've started the job again and after running for 5 minutes -- I'm not seeing anything in the logs. I'll let this job run overnight and check again, then I'll try disabling smart mode and share my results.
Possibly unrelated, I keep seeing this job appear and linger (4 currently):
Xapi#getResource /rrd_updates (on xcp-ng-1) 0% -
@techjeff Which version of XCP-ng/XO are you using? When I say the Pools settings in smart mode I mean
Resident on, are we talking about the same thing? In XO -> Settings -> Remotes, do you see the Disk and Speed information? Is the state enabled? -
@techjeff is your target host behind a NAT?
-
@tony xcp-ng: 8.2.0, xo-server: 5.82.1, xo-web: 5.87.0. I used a 3rd party tool (https://github.com/ronivay/XenOrchestraInstallerUpdater) to automatically build xoce from sources yesterday afternoon (9/12) because my past instance may have been botched while updating and of course I hadn't taken a snapshot.
In this case, I'm trying to configure replication to the local storage of each of my hosts.
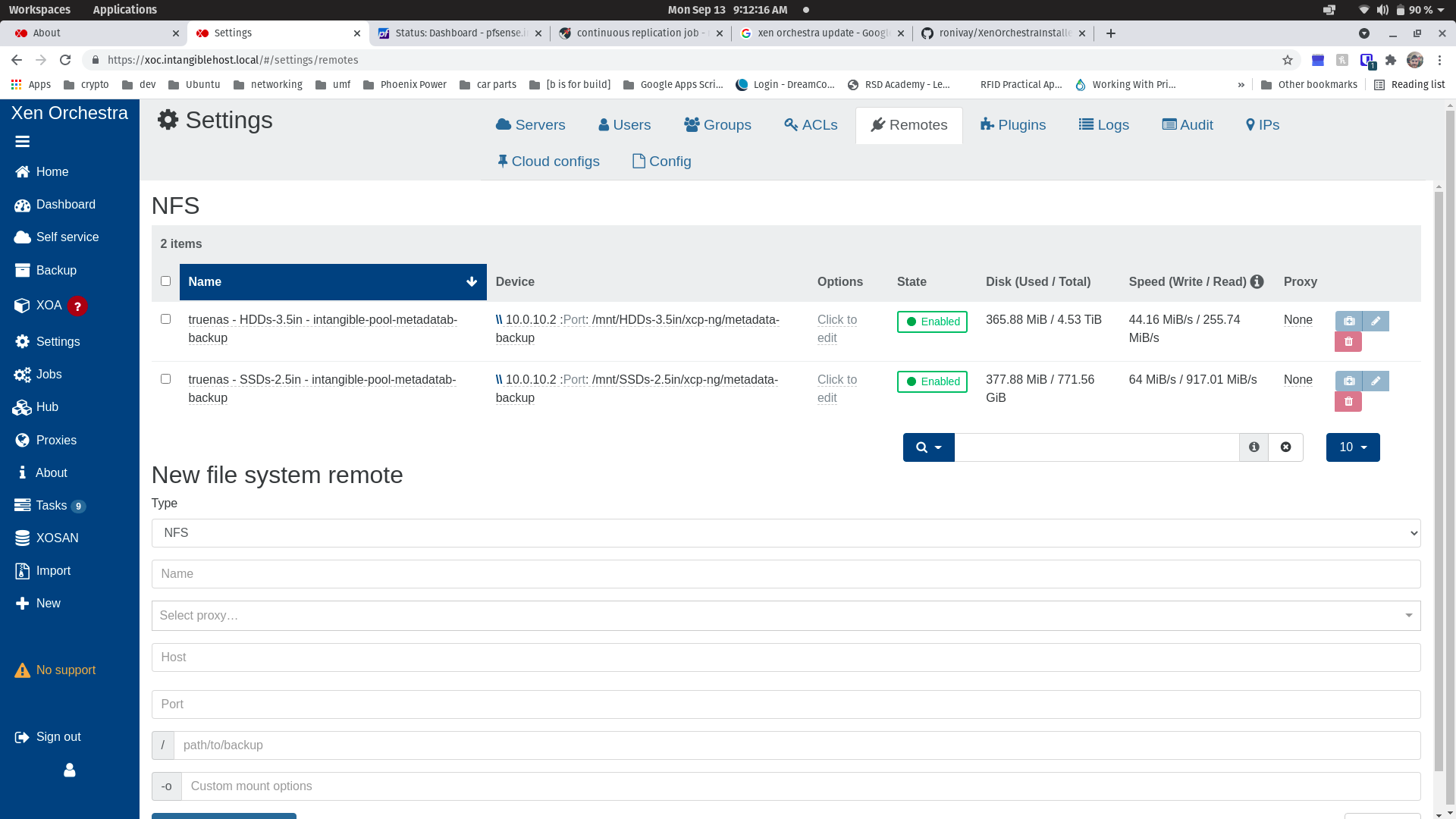
I had configured remotes for metadata backups and they appear to be working fine since I see the size and speed details and testing both with the test button indicates success. Nonetheless, I am not utilizing them for this backup job.
I mentioned yesterday I started the backup and left it overnight. As of this morning the job failed and here is the log file: 2021-09-13T04_02_55.680Z - backup NG.log.txt
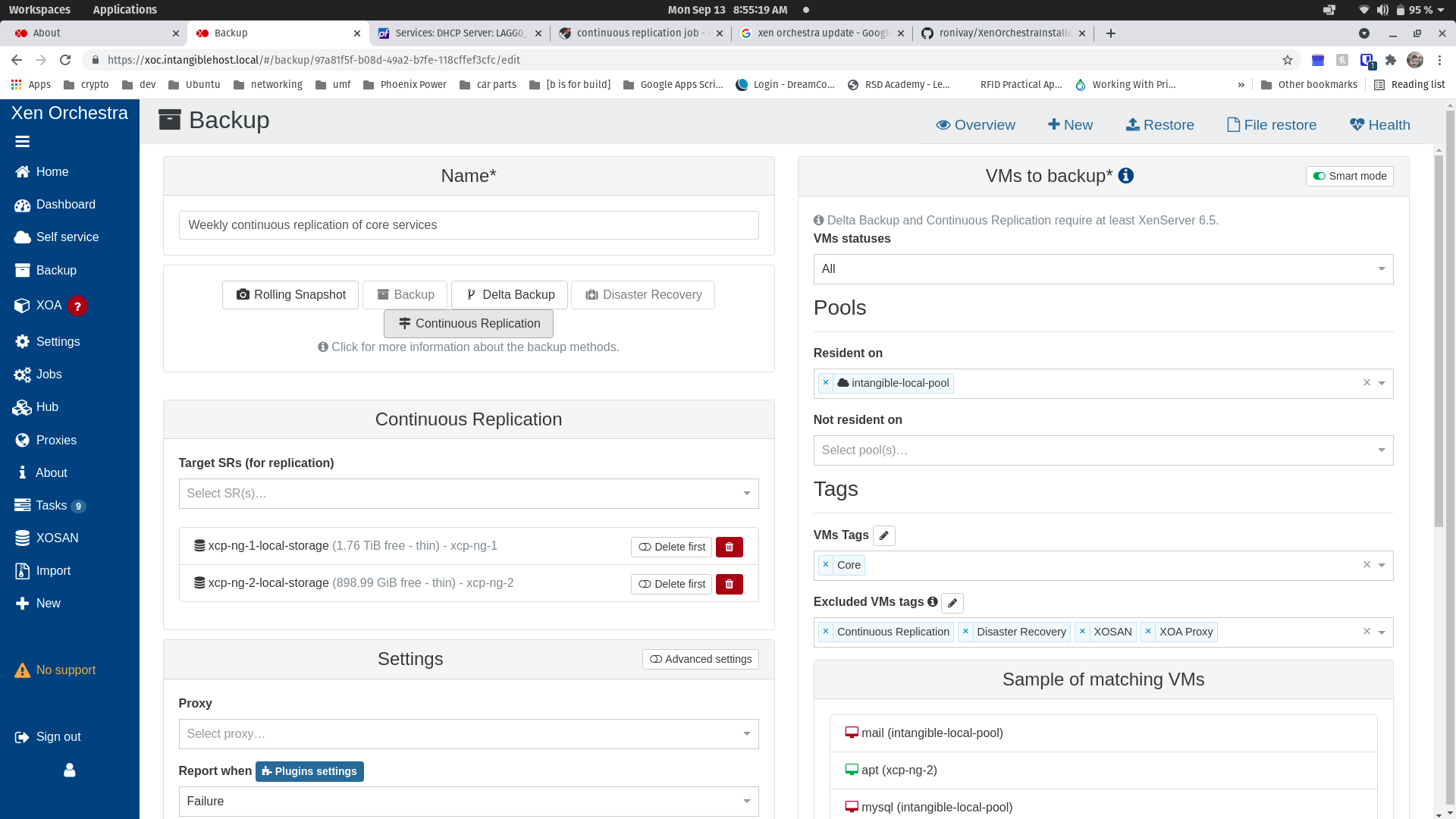
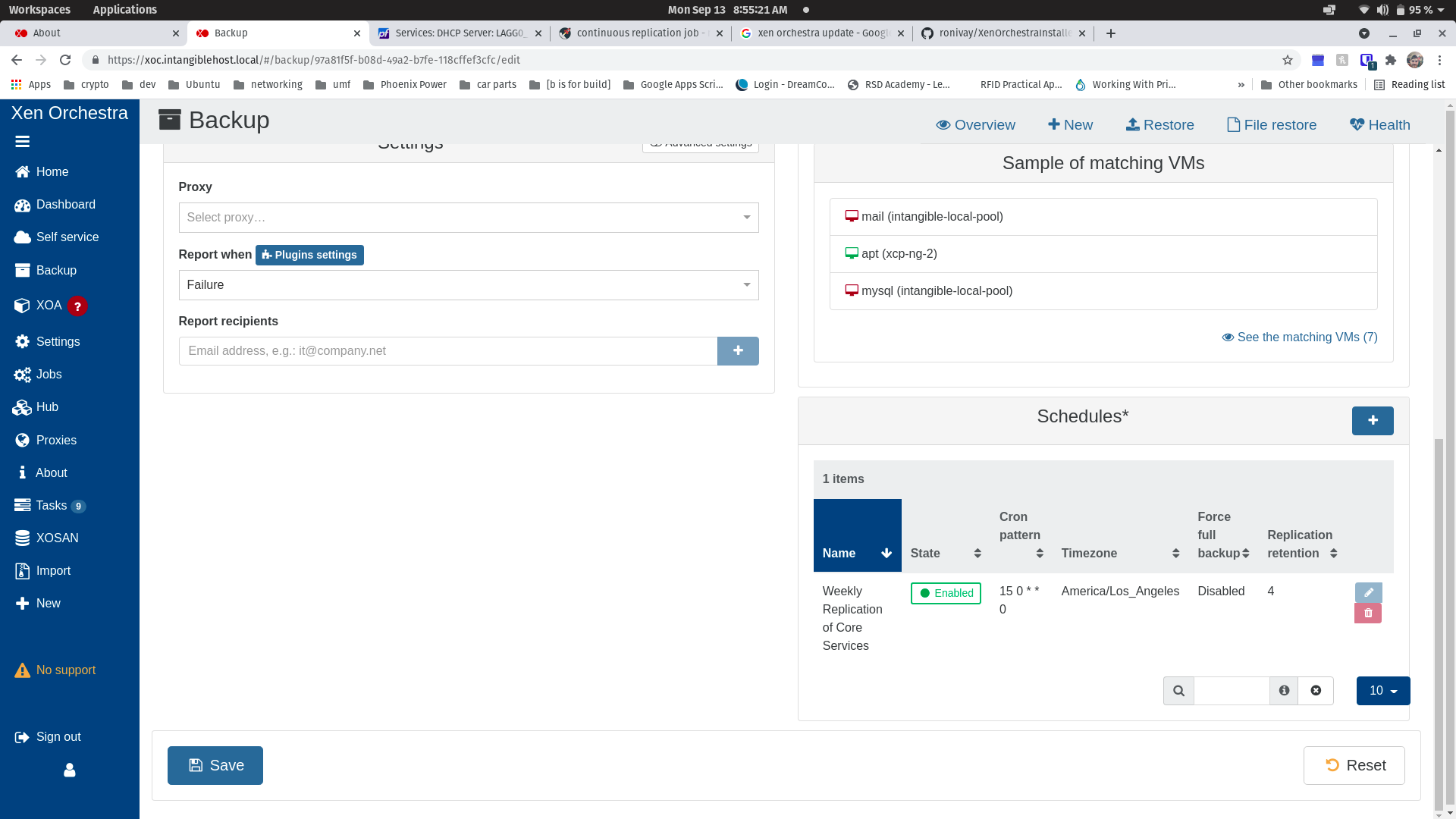
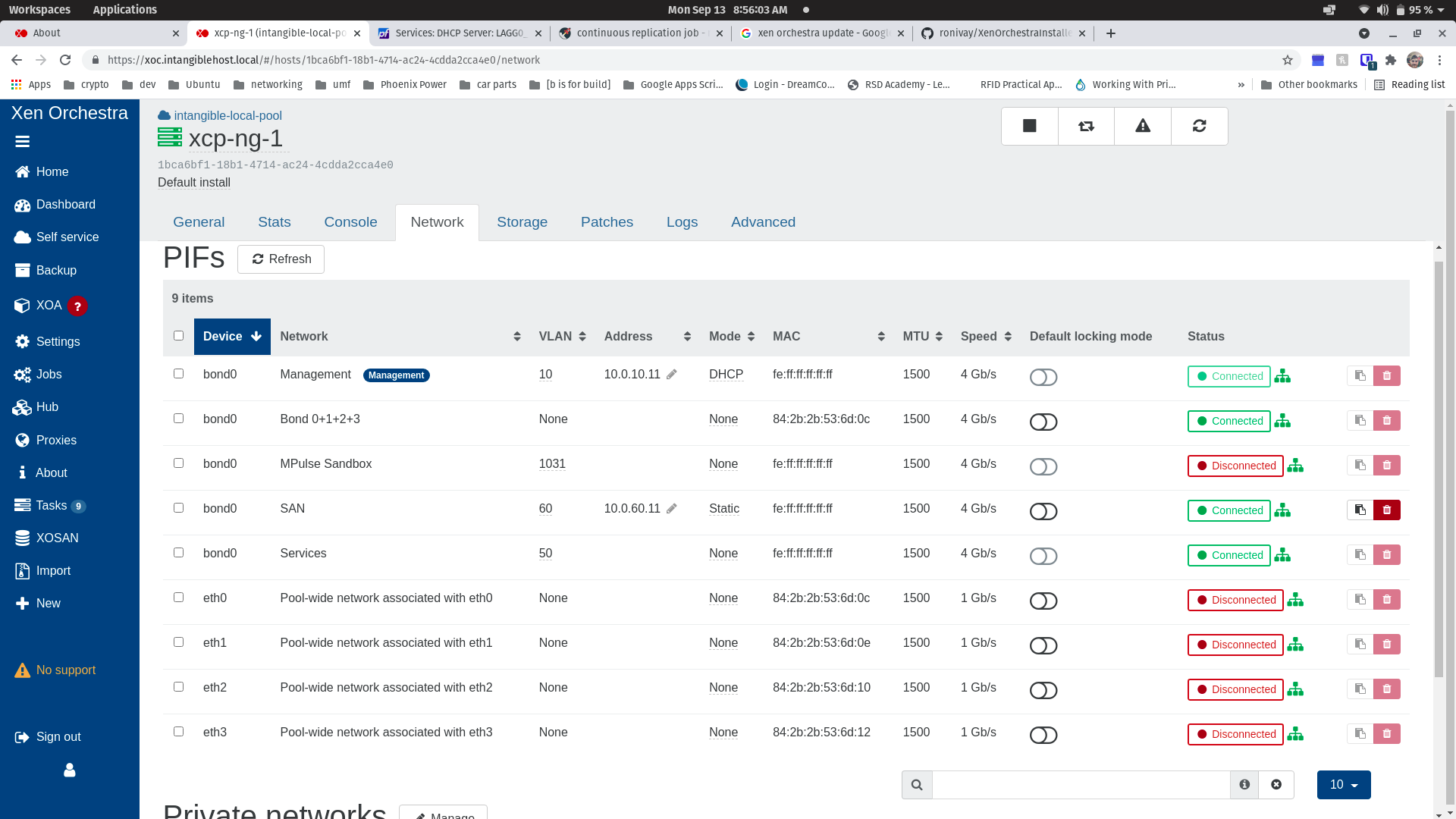
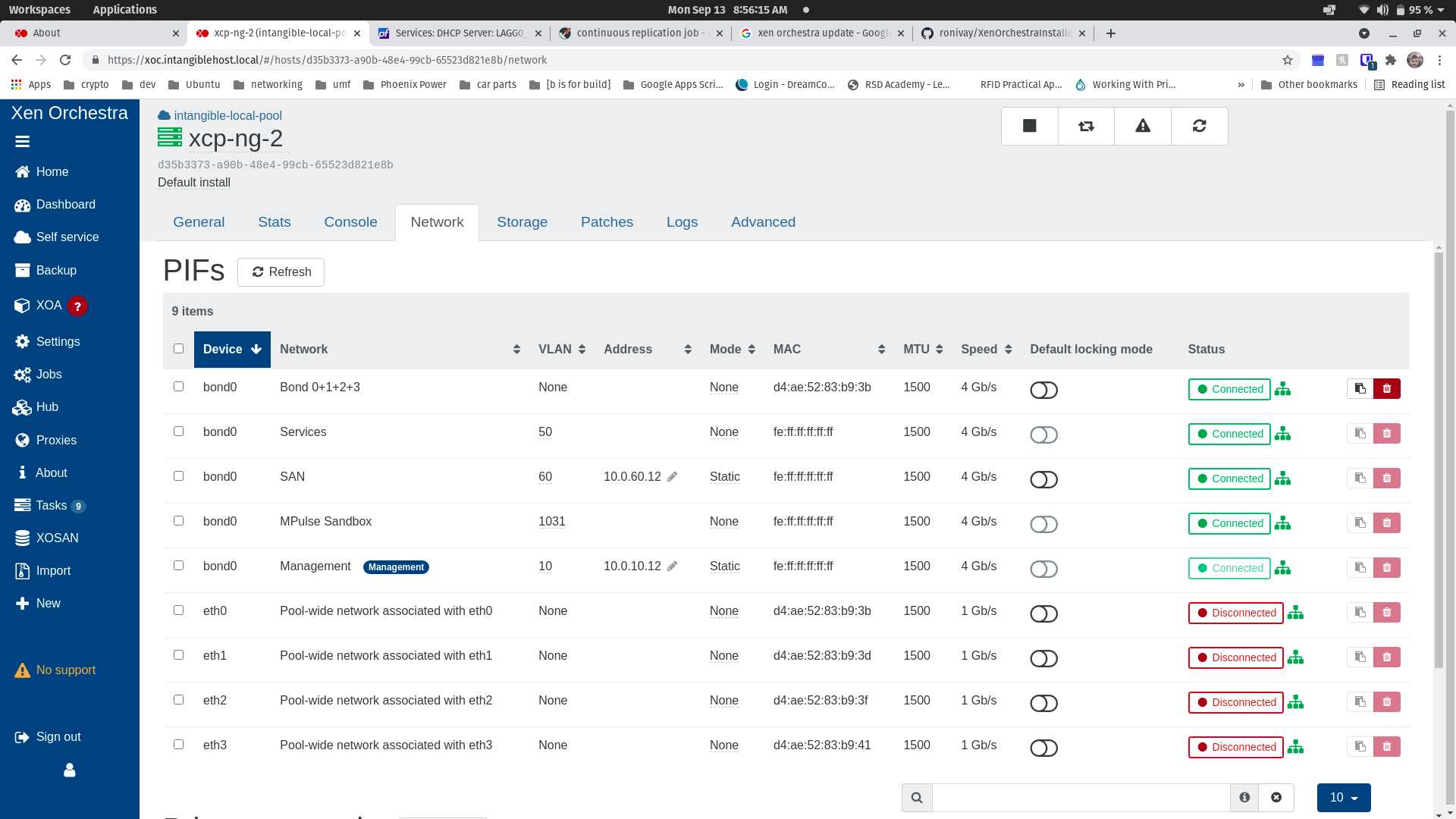
@olivierlambert - everything is in my home lab behind a dedicated DIY install of pfsense 2.5.2-Release, so all subnets are using RFC_1918 addresses. I've attached screenshots of my two hosts for reference. All traffic is passing through 4 bonded 1GbE NICs. No traffic is "untagged", management is tagged VLAN 10, and "SAN" is tagged VLAN 60. My shared NFS SRs (not remotes) are working fine on the "SAN" subnet.
The Remotes are NFS shares from my TrueNAS device. NFS is configured to listen on both 10.0.10.2 and 10.0.60.2 -- I added 10.0.10.2 because my xoce instance's IP is 10.0.10.10 and I wanted to avoid the firewall entirely for sake of simplifying testing.
-
@techjeff It seems that the transfer stopped (interrupted) immediately after it started, the snapshot went fine. Can you try to login into XOCE shell and transfer something to the back up remote mounts manually?
-
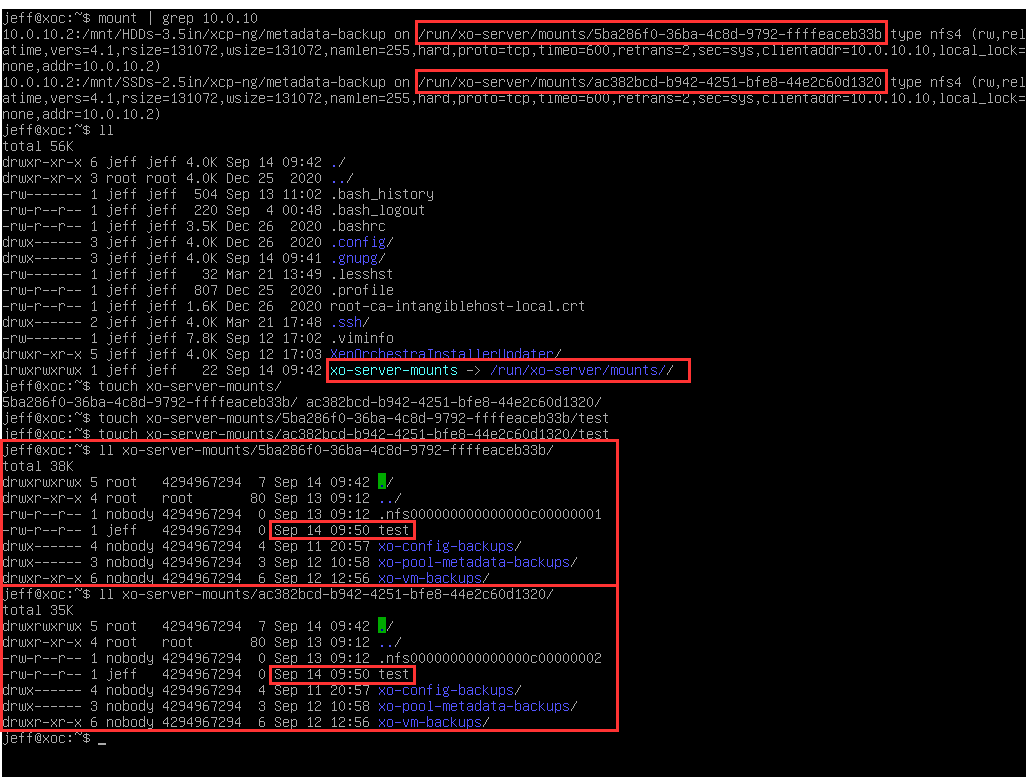
@tony I hadn't acutally put together that the "remotes" are features of XO and therefore would be mounted to my XOCE instance. Thank you for bringing that to my attention. Now that you mention it, I think "of course!"
I was able to "touch" a test file on both remotes without issue while logged on as a non-root user:
-
@techjeff So network permission is probably not the cause, but I'm still not sure why it hasn't worked right out of the box. Did you ever try replicating before setting up the NIC bonding? I only asked because your MAC address (FE:FF:FF:FF:FF:FF) is a bit weird. Also another thing you can try is delta backup instead of replication, just to see if that goes through.
-
@tony The MAC address of the NIC Bond seemed funny to me too, but it has been that way every time I have created a bond interface with xcp-ng—and I've made bone-headed mistakes and had to start over a few times over the years as I've learned the platform
 . It has seemed to work like that so I didn't bother to look into it further.
. It has seemed to work like that so I didn't bother to look into it further.I had also tried to set up a custom xapi-ssl.pem certificate from memory on the host that happens to be my pool master at the moment and it's possible I made a mistake since I didn't take notes last time and it's possible that this could be causing some issues as well.
All of this has happened because I didn't know how (and frankly still don't know for sure yet) to properly back up a host and I needed to shift hard drives around through my pool and NAS to make bet use of my resources. I ended up thrashing through vlans, vifs, and vdbs using xe because they were tied to the host that was lost without a backup >_<
I know, I'm piling complications onto this topic, but I'm just trying to focus on one thing at a time right now..
I haven't tried the replication before NIC bonding, but I could certainly give that a try. I will probably try to do a delta first before playing with nic bonding.
Thanks again for the help.
-
If you are using XO from the sources, can you update to the latest commit on
master? -
@olivierlambert I am using XO from sources. I haven't yet tried Tony's suggestions, but because a lot can change when tracking the master branch, I'll try updating then share my results.
-
That's the concept on being on the sources: you track the
masterbranch. You are very likely onmaster(except if you didn't follow our doc, in that case, there's little we can do to help). Just pull and rebuild, it might work now -
@olivierlambert I just confirmed that I am indeed tracking
master. I am using a third party tool that basically follows the steps in your doc. I understand you have no obligation to support any procedure other than the official doc, but I do appreciate your suggestions and insights -- this is a home system, nothing is running in "production" per se, but I like when I can get things workin as expectedI have updated to latest commit on master and rebuilt, I can confirm that my continuous replication to my local storage is working. Once that completes, I'll try replication to my NFS shared SR as well. Assuming that works, I'll try my metadata backup to my NFS Remotes, then finally I'll share my results here.
Thanks again!
-
Good, so the fix @julien-f pushed on
mastersolved itIn general, everytime you have an issue, follow the guide lines: get on latest commit on
masterand check if you still have the problem This will reduce the burden to answer multiple time to a problem already fixed.Thanks for the feedback!

-
@olivierlambert Now that you mention it, I do recall reading that we should always be on Master if I have issues -- I will commit that to memory and be sure to use that as a first-step
It's not often that we get to speak directly to the developers of quality projects and less often still that they are polite and helpful. Thank you for the assistance!
-
You are very welcome, happy to learn that it works for you
-
@olivierlambert
I experienced also failed backups yesterday, XOCE 5.82.1 / 5.87.0"message": "connect ECONNREFUSED 192.168.20.71:443", "name": "Error", "stack": "Error: connect ECONNREFUSED 192.168.20.71:443\n at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1148:16)\n at TCPConnectWrap.callbackTrampoline (internal/async_hooks.js:131:17)"First suspected the xcp-ng updates but I have had successfull backups after installing the patches so ruled that out.
I also had updated XOCE this week, so started looking into that.
Did an update to the current version of XOCE 5.82.2 / 5.87.0 and backups are working again.Only thing I did not figure out right away; how to kill the still active tasks from the failed backup jobs? But a restart of the toolstack on the xcp-ng server fixed that as well
Of course after all the troubleshooting I went to the forum and found this topic. Should have done that first thing

-
Always remember: as sources users, your "role" is to stay as close as possible to the latest
mastercommit. This way, you are actively helping the project to spot issues that been missed during our usual dev review process -
@olivierlambert -- this may be related to xcp-ng bug 5929, but perhaps I don't know what types of traffic I need to allow through my firewall xo allow xoc to communicate with my storage network.
I am again on the latest commit to master as of today.
My Default Migration Network was set to my Storage network (10.0.60.0/24).
My storage server is 10.0.60.2 which hosts my default NFS SR as well as my xo nfs remotes.
xcp-ng-1 management interface is 10.0.10.11 with 10.0.60.11 on storage net
xcp-ng-2 (pool master) management interface is 10.0.10.12 with 10.0.60.12 on storage netMy xoc instance only had one interface on management network with address 10.0.10.10 and backups didn't work.
I added firewall rules allowing 10.0.10.10 to access 10.0.60.11 and 10.0.60.12 via tcp/udp 111,443, and 2049, but that made no impact on backups -- I saw via pftop that 10.0.10.10 (xoc) was contacting my pool master, xcp-ng-2 via 10.0.60.12:443 when I tried to start the backup. I didn't pay super-close attention, the connections did not stay active and disappeared after 30 seconds - 1 minute
I then added an interface to xoc on my storage network with address 10.0.60.10 to avoid the firewall altogether and started a CR job which proceeded almost immediately.
I then disconnected the xoc interface on the storage network, configured my default migration network back to the Management network, disabled my firewall rules and the backups worked again.
As per @julien-f in xcp-ng bug 5929 xo uses the pool's default migration network for stats, backups, etc. as of 5.62 and that it might not have been a good idea because xo might not always be able to access the storage network. Wouldn't xo always want to communicate with the pool master via the master's management interface, even if management interface is not on the default migration network? I had always assumed that hosts only listen for xapi commands on the management interface's IP -- is that correct or a misunderstanding on my part?
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login