Google Coral TPU PCIe Passthrough Woes
-
@jjgg Can you please also post XEN traces after the VM is stopped.
(either inhypervisor.logor just typexl dmesg(under root account in your dom0) -
xl dmesgfrom the host in question. Note the last set prefixed with 739760 appeared just after I attempted to install the drivers, the depmod process was just running, it turns off before dpkg finishes. I've just included the whole set as I suspect this is from several different attempts.Additional note, I actually have two Coral PCI devices installed. For the final test I only passed one through to the VM.
(XEN) [523317.173290] d19v4 EPT violation 0x1aa (-w-/r-x) gpa 0x000000f1846800 mfn 0xd0246 type 5 (XEN) [523317.173297] d19v4 Walking EPT tables for GFN f1846: (XEN) [523317.173302] d19v4 epte 9c00005519618007 (XEN) [523317.173306] d19v4 epte 9c00002af3b9b007 (XEN) [523317.173309] d19v4 epte 9c0000244004d007 (XEN) [523317.173313] d19v4 epte 9c500000d0246845 (XEN) [523317.173318] d19v4 --- GLA 0xffffb4c880209800 (XEN) [523317.173333] domain_crash called from vmx_vmexit_handler+0xea6/0x1b00 (XEN) [523317.173338] Domain 19 (vcpu#4) crashed on cpu#23: (XEN) [523317.173348] ----[ Xen-4.13.5-9.30 x86_64 debug=n Not tainted ]---- (XEN) [523317.173351] CPU: 23 (XEN) [523317.173355] RIP: 0010:[<ffffffffad54987f>] (XEN) [523317.173359] RFLAGS: 0000000000010202 CONTEXT: hvm guest (d19v4) (XEN) [523317.173369] rax: ffffb4c880209800 rbx: ffffb4c8806a3aac rcx: 0000000000000000 (XEN) [523317.173373] rdx: 00000000fee97000 rsi: ffffb4c8806a3aac rdi: 0000000000000001 (XEN) [523317.173381] rbp: ffff904f409e6380 rsp: ffffb4c8806a3a60 r8: 000000000000000d (XEN) [523317.173385] r9: ffff904f413d52f8 r10: ffff904f4162a700 r11: 00000000000393e0 (XEN) [523317.173389] r12: 0000000000000097 r13: 0000000000000011 r14: 000000000000000d (XEN) [523317.173393] r15: ffff904f413d52f8 cr0: 0000000080050033 cr4: 00000000001706e0 (XEN) [523317.173398] cr3: 0000000103736006 cr2: 00007f23d938f6b7 (XEN) [523317.173402] fsb: 00007f23d9e298c0 gsb: ffff90563e700000 gss: 0000000000000000 (XEN) [523317.173407] ds: 0000 es: 0000 fs: 0000 gs: 0000 ss: 0018 cs: 0010 (XEN) [524620.959493] d23v1 EPT violation 0x1aa (-w-/r-x) gpa 0x000000f1846800 mfn 0xd0246 type 5 (XEN) [524620.959498] d23v1 Walking EPT tables for GFN f1846: (XEN) [524620.959501] d23v1 epte 9c00005730d5f007 (XEN) [524620.959504] d23v1 epte 9c0000245bedd007 (XEN) [524620.959506] d23v1 epte 9c00002af3b93007 (XEN) [524620.959509] d23v1 epte 9c500000d0246845 (XEN) [524620.959512] d23v1 --- GLA 0xffffb82103411800 (XEN) [524620.959520] domain_crash called from vmx_vmexit_handler+0xea6/0x1b00 (XEN) [524620.959523] Domain 23 (vcpu#1) crashed on cpu#10: (XEN) [524620.959529] ----[ Xen-4.13.5-9.30 x86_64 debug=n Not tainted ]---- (XEN) [524620.959531] CPU: 10 (XEN) [524620.959534] RIP: 0010:[<ffffffff95027075>] (XEN) [524620.959537] RFLAGS: 0000000000010202 CONTEXT: hvm guest (d23v1) (XEN) [524620.959542] rax: 00000000fee97000 rbx: ffff9213b9164480 rcx: 0000000000000000 (XEN) [524620.959545] rdx: ffffb82103411800 rsi: 0000000000000000 rdi: ffffb82103411800 (XEN) [524620.959549] rbp: ffffb8210664f9ac rsp: ffffb8210664f960 r8: 0000000000000001 (XEN) [524620.959552] r9: ffff9213be007600 r10: 0000000000001001 r11: 0000000000001001 (XEN) [524620.959556] r12: 0000000000000011 r13: ffff9213ba74f2a8 r14: ffff9213ba74f0a8 (XEN) [524620.959558] r15: 0000000000000097 cr0: 0000000080050033 cr4: 00000000001606e0 (XEN) [524620.959561] cr3: 00000007c9230004 cr2: 000055d28bf759a8 (XEN) [524620.959564] fsb: 00007f9f132264c0 gsb: ffff9213be440000 gss: 0000000000000000 (XEN) [524620.959567] ds: 0000 es: 0000 fs: 0000 gs: 0000 ss: 0018 cs: 0010 (XEN) [524887.457380] d24v0 EPT violation 0x1aa (-w-/r-x) gpa 0x000000f1846800 mfn 0xd0246 type 5 (XEN) [524887.457385] d24v0 Walking EPT tables for GFN f1846: (XEN) [524887.457389] d24v0 epte 9c000057150c0007 (XEN) [524887.457392] d24v0 epte 9c000022442f9007 (XEN) [524887.457395] d24v0 epte 9c00002af3b93007 (XEN) [524887.457398] d24v0 epte 9c500000d0246845 (XEN) [524887.457401] d24v0 --- GLA 0xffffa20b43411800 (XEN) [524887.457411] domain_crash called from vmx_vmexit_handler+0xea6/0x1b00 (XEN) [524887.457415] Domain 24 (vcpu#0) crashed on cpu#27: (XEN) [524887.457422] ----[ Xen-4.13.5-9.30 x86_64 debug=n Not tainted ]---- (XEN) [524887.457424] CPU: 27 (XEN) [524887.457427] RIP: 0010:[<ffffffff97027075>] (XEN) [524887.457430] RFLAGS: 0000000000010202 CONTEXT: hvm guest (d24v0) (XEN) [524887.457437] rax: 00000000fee97000 rbx: ffff96aab4ed67e0 rcx: 0000000000000000 (XEN) [524887.457440] rdx: ffffa20b43411800 rsi: 0000000000000000 rdi: ffffa20b43411800 (XEN) [524887.457445] rbp: ffffa20b4ca4f9ac rsp: ffffa20b4ca4f960 r8: 0000000000000001 (XEN) [524887.457448] r9: ffff96aabe007600 r10: 0000000000001001 r11: 0000000000001001 (XEN) [524887.457452] r12: 0000000000000011 r13: ffff96aaba7482a8 r14: ffff96aaba7480a8 (XEN) [524887.457456] r15: 0000000000000097 cr0: 0000000080050033 cr4: 00000000001606f0 (XEN) [524887.457459] cr3: 00000007eb0ea003 cr2: 00007ff2ba681fa7 (XEN) [524887.457463] fsb: 00007ff2ba6844c0 gsb: ffff96aabe400000 gss: 0000000000000000 (XEN) [524887.457466] ds: 0000 es: 0000 fs: 0000 gs: 0000 ss: 0018 cs: 0010 (XEN) [525662.181596] d29v1 EPT violation 0x1aa (-w-/r-x) gpa 0x000000f1846800 mfn 0xd0046 type 5 (XEN) [525662.181599] d29v1 Walking EPT tables for GFN f1846: (XEN) [525662.181602] d29v1 epte 9c00005519559007 (XEN) [525662.181604] d29v1 epte 9c000022442f9007 (XEN) [525662.181605] d29v1 epte 9c0000284bed3007 (XEN) [525662.181607] d29v1 epte 9c500000d0046845 (XEN) [525662.181609] d29v1 --- GLA 0xffffb41dc3409800 (XEN) [525662.181615] domain_crash called from vmx_vmexit_handler+0xea6/0x1b00 (XEN) [525662.181617] Domain 29 (vcpu#1) crashed on cpu#0: (XEN) [525662.181621] ----[ Xen-4.13.5-9.30 x86_64 debug=n Not tainted ]---- (XEN) [525662.181623] CPU: 0 (XEN) [525662.181625] RIP: 0010:[<ffffffffb8c27075>] (XEN) [525662.181626] RFLAGS: 0000000000010202 CONTEXT: hvm guest (d29v1) (XEN) [525662.181630] rax: 00000000fee97000 rbx: ffff8abaf4d72060 rcx: 0000000000000000 (XEN) [525662.181632] rdx: ffffb41dc3409800 rsi: 0000000000000000 rdi: ffffb41dc3409800 (XEN) [525662.181635] rbp: ffffb41dc67b79ac rsp: ffffb41dc67b7960 r8: 0000000000000001 (XEN) [525662.181637] r9: ffff8abafe007600 r10: 0000000000001001 r11: 0000000000001001 (XEN) [525662.181639] r12: 0000000000000011 r13: ffff8abafa7492a8 r14: ffff8abafa7490a8 (XEN) [525662.181641] r15: 0000000000000097 cr0: 0000000080050033 cr4: 00000000001606e0 (XEN) [525662.181643] cr3: 00000007f6df2006 cr2: 000055f23e274c78 (XEN) [525662.181645] fsb: 00007f3828fce4c0 gsb: ffff8abafe440000 gss: 0000000000000000 (XEN) [525662.181647] ds: 0000 es: 0000 fs: 0000 gs: 0000 ss: 0018 cs: 0010 (XEN) [739760.414382] d30v3 EPT violation 0x1aa (-w-/r-x) gpa 0x000000f1846800 mfn 0xd0046 type 5 (XEN) [739760.414387] d30v3 Walking EPT tables for GFN f1846: (XEN) [739760.414391] d30v3 epte 9c00005730d5f007 (XEN) [739760.414394] d30v3 epte 9c000022442f8007 (XEN) [739760.414396] d30v3 epte 9c0000224437a007 (XEN) [739760.414399] d30v3 epte 9c500000d0046845 (XEN) [739760.414402] d30v3 --- GLA 0xffffae9003411800 (XEN) [739760.414411] domain_crash called from vmx_vmexit_handler+0xea6/0x1b00 (XEN) [739760.414414] Domain 30 (vcpu#3) crashed on cpu#9: (XEN) [739760.414420] ----[ Xen-4.13.5-9.30 x86_64 debug=n Not tainted ]---- (XEN) [739760.414422] CPU: 9 (XEN) [739760.414425] RIP: 0010:[<ffffffff97427075>] (XEN) [739760.414428] RFLAGS: 0000000000010202 CONTEXT: hvm guest (d30v3) (XEN) [739760.414433] rax: 00000000fee97000 rbx: ffff96a3f95d7cc0 rcx: 0000000000000000 (XEN) [739760.414437] rdx: ffffae9003411800 rsi: 0000000000000000 rdi: ffffae9003411800 (XEN) [739760.414441] rbp: ffffae900d0779ac rsp: ffffae900d077960 r8: 0000000000000001 (XEN) [739760.414444] r9: ffff96a3fe007600 r10: 0000000000001001 r11: 0000000000001001 (XEN) [739760.414448] r12: 0000000000000011 r13: ffff96a3fa7482a8 r14: ffff96a3fa7480a8 (XEN) [739760.414451] r15: 0000000000000097 cr0: 0000000080050033 cr4: 00000000001606e0 (XEN) [739760.414454] cr3: 00000007f7266001 cr2: 00007f22e42b42b0 (XEN) [739760.414457] fsb: 00007f22e412f4c0 gsb: ffff96a3fe4c0000 gss: 0000000000000000 (XEN) [739760.414460] ds: 0000 es: 0000 fs: 0000 gs: 0000 ss: 0018 cs: 0010 -
@jjgg Thank you. Yes the same problem - ept violation.. Look, I'll try to figure out what we can do here. There's a patch that comes from Qubes OS guys that normally shold fix the MSI-x PBA issue (not sure that this is the good fix, but still... worth trying) This patch applies on recent Xen and wasn't accepted yet. I will take a look if it can be easily backported to XCP-ng Xen and come back to you.
-
-
@andSmv thanks. Completely understand this appears more of a hardware issue here, but happy to test anything. The host that these cards are installed in isn't running critical infrastructure and can be rebooted relatively easily.
@exime your initial post was a top Google result, was still helpful! Thanks.
-
@jjgg Here's the link to
xen.gz.You need to put it in your
/bootfolder (backup your existent file!) and make sure your grub.cfg is pointing to it.But first: Backup all you want to backup! The patch is totally untested and doesn't apply as is (so I needed to adapt it). Normally not such a big deal and should not do no harm, but... you never know.
I'm also not sure that the issue would be fixed. We unfortunatelly do not have Coral TPU device at Vates, so we can't do the more deep analysis on this. The guy who wrote this patch tried to fix other device.
@exime - this is 4.13.5 XCP-ng patched xen, so there's chances it wouldn't work for you (from what I saw you're running 4.13.4 xen)
Anyway, if we have good news, we'll find the way to fix it for everybody.
-
-
Ok so testing setup.
Downloaded xen.gz, renamed to xenept.gz and put into /boot:

Updated grub.cfg to point to that file:
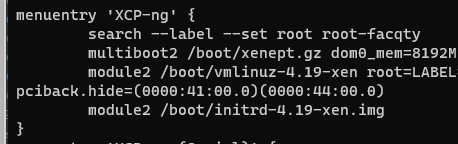
Rebooted host.
Got to the grub screen, let it load as normal, as soon as it disappeared (so it had made the default selection) the server rebooted.
I ended up just placing xen.gz in /boot and removing the symbolic link to the original and attempting, no difference.
Of note, messing with kernels / grub is not something I've got experience with. I may have made a mistake / need things explained in a bit more detail if I'm potentially misunderstood some instructions above.
-
Booted into fallback and put things back the way they were. Happy to keep testing if there's additional bits to test.
-
Ah, just found these things exist..... Then just found this issue exists too
 ️
️ -
If only they could have done PCI hardware that follow the PCI specifications

-
Maybe this one will come to life again https://xcp-ng.org/forum/topic/7066/coral-tpu-pci-passthrough/14
Don't really want to buy one knowing its not working!!
-
Definitely frustrating and no fault of xcp-ng - I have a lot of spare cpu cycles so it isn't majorly impacting me that I know of. I'm still available to test fixes though.
Looks like most of the Proxmox users have got this working in an LXC container by installing the drivers on the host itself and passing through the actual Apex devices. Not a route that's applicable to us but just a datapoint.
-
@jjgg it would be great if we could get this working. My CPU utilisation is fine too, but when I shut down my Zoneminder VM things go a lot quieter (fans) so I'm sure there would be a benefit CPU and power wise.
-
@jmccoy555 // @jjgg
Did anyone of you get your Coral USB TPU working and passthrough to a VM?
-
@Nornode hey, nope I did not. I ended up moving my infrastructure to Proxmox.
Honestly this is no fault of XCP-ng and XCP-ng suits my hardware / setup a lot better, but it was either that or I had two servers that needed to be bare metal.
-
PCI passthrough might cause problems with this device, but USB could work.
-
@olivierlambert Seems like a reasonable place to ask as any - I am currently using a USB Coral over IP (Virtualhere) but would rather load it into my VM directly - what's the current status of snapshots/backups with a vUSB?
I've been reading that XO can now support disk exclusions with
[NOBAK]but this probably doesn't apply to a Coral. Is an offline backup still the best available method? -
For NOBAK and on 8.3 yes, but I'm not sure it will be related to USB. You should use offline, that should work. Alternatively, we have plans to detect the error, to unplug the USB device, do the snap and replug it just after.
-
@olivierlambert Thanks that's good to know. That functionality would be great down the line!
I do have a spare M.2 E-key on my XCP host running the VM Coral is needed for, but seems like I'd have trouble going by this thread. Might even have trouble with the USB Coral, it hasn't been much better so far in terms of whacky non-standard behavior...