
User stories #1 : XCP-ng at Vates
In this first episode of our "User stories", we'll see how XCP-ng is used at Vates. And we'll use a very recent example as we just moved from server rental at various places to a colo/rack unit to colocate our own machines.
Previous infrastructure
We've been hosted by different providers: Scaleway in France, and Hetzner in Germany (and OVH before).
Despite the fact they are very competitive on their hardware, sadly, it's always complicated when you want to build your own infrastrucutre, with your own storage choices or when you need some flexibility. You'll often end up with higher costs when it comes to getting shared storage and features outside the providers "basic offer".
Also having different sites that are across hostile networks required us to use the XOA SDN controller to have a 100% private management network for all VMs and hosts. Which is fine, but adds another moving piece in the infrastructure.
Note: our current production infrastructure is small. However, be assured you'll have more user stories in the future regarding very large deployments ;)
New objective: KISS and flexible
After years of building virtualized platforms, there's one advice I'm constantly giving that I think should be listened to: keep it simple and stupid.
So we decided to achieve more flexibility in our infrastructure, while ensuring it's resilient AND simple to manage. It means we could rely on non-expansive (but VERY fast) commodity hardware that we can replace easily.
The place: Rock DC Lyon
Last year we selected this datacenter as the right place to host our new infrastructure. We started by hosting our lab in a rack, and we've been happy with it. This DC is brand new (2019) and rather nice. You can follow this link to learn more (in French, but nice pictures!)

Our provider is Jaguar Network.
The hardware: EPYC at the core
Because we are now able to select our own hardware, we chose to use the following configuration.
Network
We are using rock solid and proven Ruckus hardware: 2x Ruckus ICX6610 units stacked in an HA configuration (with 4x40G interconnects).

These units have proven extremely reliable in our lab settings, and now production. Being in an HA pair, all important production hosts and storage platforms have a 10gbE link to each switch, bonded. If an entire switch goes offline for some reason, there will be no traffic loss.
These units also come with many premium L3 features such as VRFs which allow us to completely separate our lab, production, and management routing tables. For public production access, we are currently taking in routes for 3x IPv4 blocks, and one very large IPv6 block we have split up as we see fit. They also support goodies like OpenFlow SDN support which enables real world testing regarding the OpenFlow work happening within XCP-ng development.
The main advantage to commodity hardware like this is it's availability and price, we can afford to have cold spares ready to go in our rack should something ever need replacing.
Storage
While keeping to the KISS principle, we are using a dedicated storage host, running FreeNAS.
The host is a Dell R730, with 128GiB RAM and 2x Xeon @ 2.4GHz CPUs running FreeNAS. one of the biggest design considerations here was to present the storage to our hosts using NFS, not iSCSI. It is safe to say 20% or more of our XCP-ng support tickets are related to iSCSI issues from misconfiguration, issues with storage appliances, etc. NFS is a much simpler protocol, and is thin provisioned! As you can see from the numbers below, it also does not hinder performance on modern hardware.

The main storage repository is a mirrored pair of 2TiB Samsung 970 EVO Plus NVMe drives (to store VM systems and databases), our "slow" storage is comprised of 4x 1TiB SAS HDDs (to store files from our NextCloud instance etc). This is all connected to our backbone over a redundant pair of 10gbE connections from Intel series NICs.

It's a cheap configuration (approx 450USD/400EUR per NVMe drive) to achieve in one disk of one VM:
- 140k IOPS in read and 115k in write for 4k blocks
- Saturating 10G for read/write in 4M blocks (1000 MiB/s)
Obviously, it scales even better with multiple VMs!
Compute nodes
Because we are tech geeks and passionate about hardware, we couldn't pass up AMD EPYC CPUs. To be fair, we are also a bit bored pushing updates to fix Intel CPU flaws…
So we ordered 3x Dell R6515, with one EPYC 7302P + 128GiB RAM each. Pricing was really decent but this hardware is also very powerful for our requirements.

We added one Intel X710-BM2 NIC (dual 10G) in each node and connected 2x 10G DACs per node to the Ruckus switch pair (one DAC per switch).

They have also been licensed with iDRAC9 Enterprise for very easy remote management, including HTML5 based remote KVM - no more Java!
XCP-ng configuration
In this simple deployment, we are relying on using a redundant bond (2x10G) for all networks: management, storage and public. Each network is isolated in its own VLAN, this way we can logically split these networks (and also have a dedicated virtual interface in our VM for eg the public network). This is also one of many steps to isolate our management network from our public routing.
The rest of the configuration is pretty standard: 2x NFS SR (one for NVMe drives, the other for HDDs).
As for our non-public networks, the only route into them is via a jump box running a Wireguard VPN.
Backup
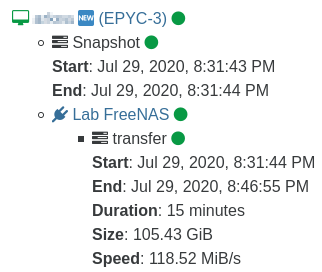
Obviously, we are using Xen Orchestra to backup all our VMs with Delta backups, to another separate FreeNAS machine.

Note that we are reaching very nice speeds for these backups as our whole backbone is 10gbE, thin provisioned, and simplified:
Migration
Having brand new infrastructure is good, but our production is still running on our old hardware. And because we shifted from Intel to AMD, we can't simply live migrate VMs! But also, an offline migration will be relatively long, considering it has to replicate the full disk first.

So how can we achieve low downtime during our migration? You can use something we could call "warm data migration".
In short, we are creating a Xen Orchestra Continuous Replication job on our current production VMs, to replicate them from our old infrastructure, to our new AMD hosts.

We'll run the first job pass while all VMs are running, so the long initial replication (the "full" replication) will be done without service interruption. After this first synchronisation, we can shutdown the VMs, and run the replication again. Now that it hgas a full initial replication to reference, only few blocks will need to be transferred since it's a delta from the last run.
And right after that, we can boot the replicated VMs on our AMD hosts! (and change their IP configuration, because we have new public IP blocks from a different provider).
New performance levels
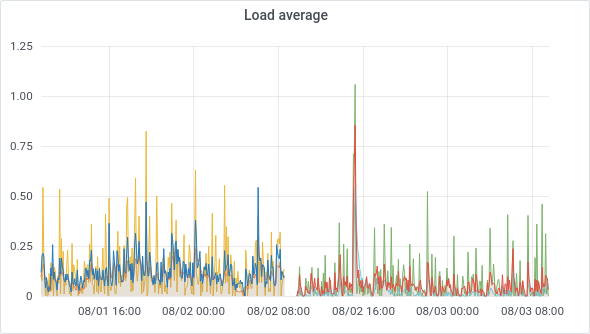
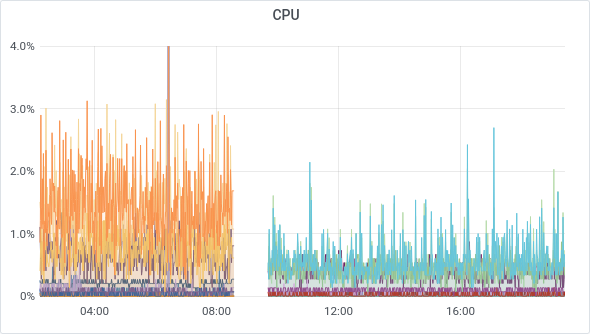
Outside of the really great backup performance (going from 20 min for our daily backups to… 2 minutes!), there's also less load average for all our VMs. It makes sense since the storage is faster, but also CPUs with great single and multithreaded performance is behind them.
This is very visible for some VM load averages:
But also CPU usage:
For our Koji Build system for XCP-ng packages, kernel packaging time previously took 1 hour, but now less than 20 minutes! And with the same VM spec (same number of cores). But since we had more cores, we even added 2 extra cores, and the build time was even shorter (less than 15 minutes).
Recap
So this big migration project was done in 3 phases:
- Physically racking the hardware in the DC (and connecting everything)
- Software install/configuration on the new hardware (XCP-ng setup, storage…)
- Migration
The result for us is: complete flexibility in our infrastructure, no external constraints on our internal network, faster VMs, faster backups and… an ROI of less than 1 year! The total time spent on these 3 phases was very contained: less than 3 days of actual work (probably a bit more with plan creation). Finally, most of the work was IP/DNS migration for the VMs themselves.
Oh, and AMD EPYC CPUs are really impressive: great single and multithread performance, with very reasonable power usage. And all of this with decent pricing!
Interested? We can deliver it for you!

If you want to enjoy this kind of configuration, released in a fully turnkey and hosted fashion, we can do it! That includes all the hardware, XCP-ng installation, the Xen Orchestra edition of your choice as well as our pro support for all the stack, in a fixed monthly price.
Take a look on our dedicated page to get more information.


