
Using SPDK with Xen
This devblog will provide an intro on why changing the datapath for your VM disk can have a big impact on the performance, and our future plans for this.
Note: this blog post is mostly a written version of my last FOSDEM presentation available here:
⚙️ How it currently works
For now (and for the last decade), the link between your virtual disk (eg: a VHD file on your local disk) and the block device seen in your VM, is done by tapdisk.
In short, this piece of software gets all the storage requests from the PV driver, and sends them to the actual/real storage:
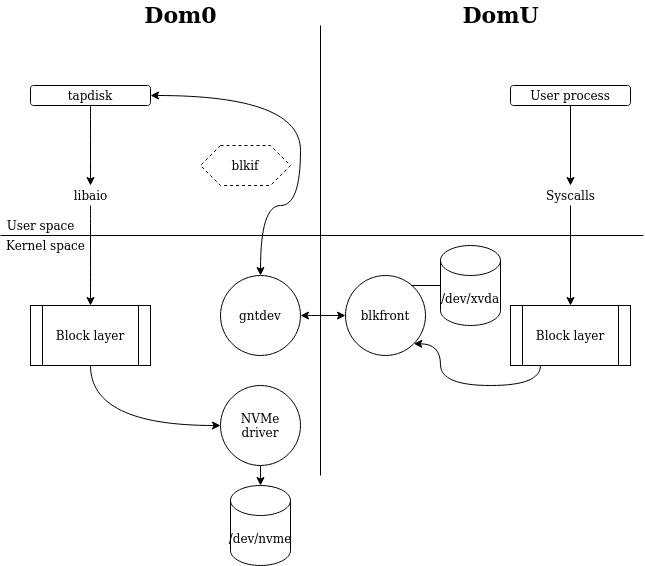
If you want more details on how it works (and how "Xen Grants" are helping to isolate the memory of your VMs), you can read this deep dive:

⏳ Limitations
The issue with tapdisk: it's rather efficient, and despite the fact it scales with multiple disks, the "per VM disk" performance isn't great, mostly because it's mono-threaded. If you use multiple disks at once (any real life load actually, because nobody uses only one virtual disk per physical host), the overall performance is great.
But there's also other known limitations, like a lack of live discard support, which isn't great in 2023. Could we replace tapdisk with another datapath without any VM modification? Yes! And that's what we'll experiment with here.
🏎️ SPDK: another data path
First, what is SPDK? It stands for "Storage Performance Development Kit", it's a set of tools and libraries for writing high performance, scalable and user-mode applications. In our case, we'll use it as an NVMe driver, or in other words, as a drop-in replacement for the tapdisk datapath in the storage stack.
Also, with the challenge of no modification in the VM: we want to get SPDK standing in as a blkif backend, taking requests from VMs and writing them directly on the NVMe disk. Note, however, that the entire NVMe drive must be dedicated to work with SPDK.
Why SPDK?
Because it is… fast. It handles a lot of things, like multi-queue (dealing with stuff in parallel) and discard among many other perks. Also, this is a great way to investigate any bottleneck elsewhere in the datapath, comparing with tapdisk and improving potentially the whole platform. A great test bench!
Keeping security in mind
This replacement is not a plug-and-play thing: we must get SPDK to "speak" the blkif protocol, but also working with Xen: meaning there's no "open bar" access to the entire host's memory (unlike virtio on KVM for example).
The blkfront driver in the DomU is explicitly giving access to a buffer of data. Xen can limit access to what memory the virtual machine wants to share with the backend and therefore Xen will stay the trusted 3rd party to authorize (or not) any guest memory access.
✅ What we have already done
Currently, we have a functioning multi-queue blkif backend that can connect to a pre-existing VM using the blkfront existing in upstream Linux.
The multi-queue support of this driver is already functioning and nothing is needed to be changed inside the guest.
The virtual drives appears in the guest as a /dev/xvd that can be then partitioned and use like any normal block device. Our implementation allows us to use any type of storage that SPDK is capable of handling, mostly a NVMe drive in our case.
Initial results
Keep in mind we are comparing results to tapdisk, a mature and optimized project spanning the last 10 years, versus our "fresh" SPDK prototype, which still has room for even better performance. Also, we are testing the performance for one drive only, a known "sub-optimal" scenario since you probably have more than one virtual drive used on your physical storage. But this is the point: working on removing any known bottleneck of the existing solution!
fio on an Intel Optane drive (900P series). The CPU used is rather old (Xeon E5-2637 v2), which also doesn't help tapdisk but demonstrates our point.Let's start where SPDK with multiqueue support is shining: 4k blocks with 4 fio jobs:
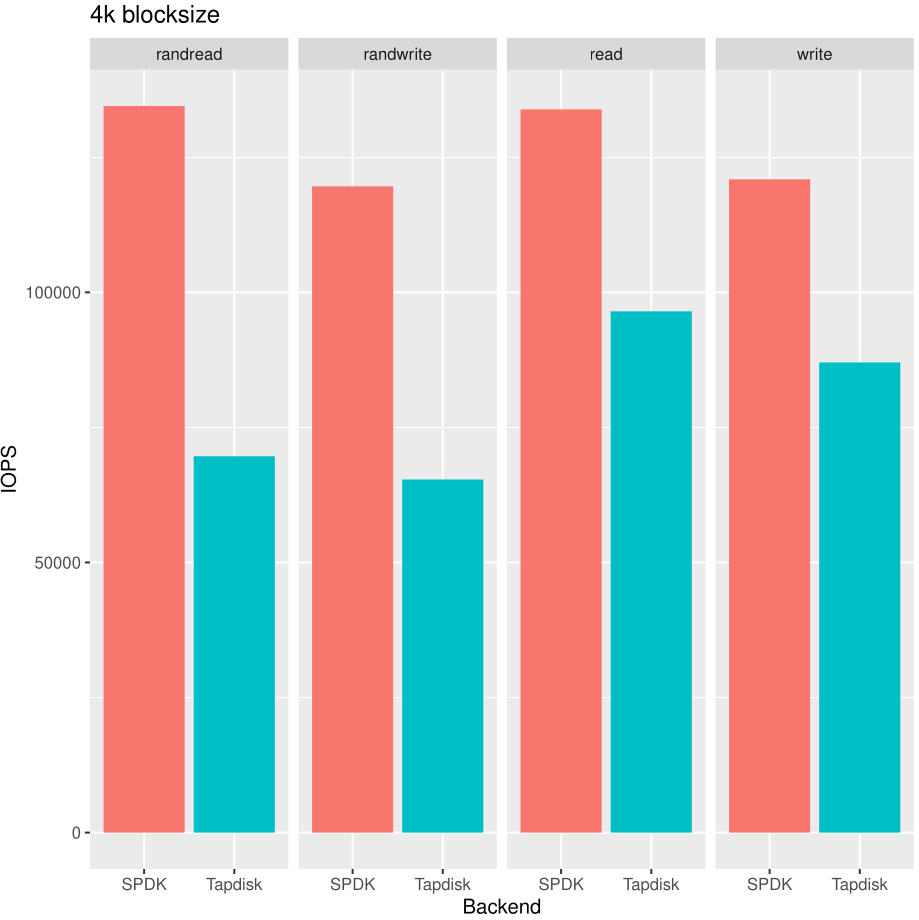
In random read and write, our new SPDK backend is basically destroying tapdisk, by almost doubling the IOPS (near +100%) in read or write random mode. It's also worth noting that random performance doesn't hurt SPDK a lot -vs sequential- unlike tapdisk. So even in sequential mode, SPDK is sitting comfortably ahead.
Let's go for the bandwidth test, now with a 1M block size:
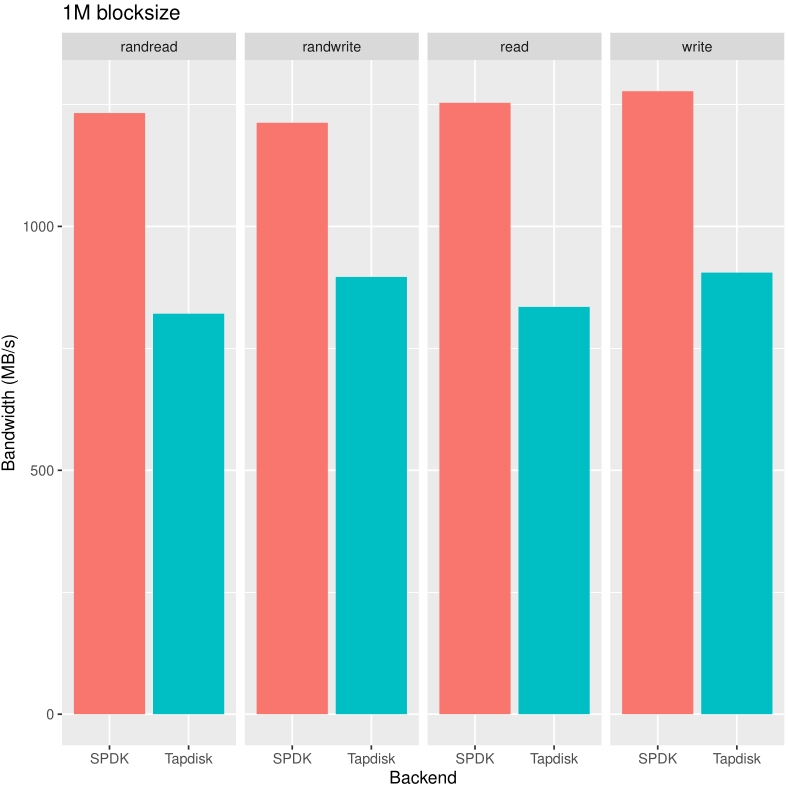
In this case, the impact of random vs sequential is far less visible, both for tapdisk and SPDK. Since blocks are bigger, it's rather logical: there's less blocks to deal with in the same amount of time.
However, even if it's less spectacular, SPDK is leading with an impressive 25% improvement against a tapdisk backend.
Bonus points
While this is already impressive on the performance side, we can add that the live discard feature is already working with our SPDK backend. That's due to the fact that both SPDK and the transport protocol blkif support it natively.
discard wasn't implemented in tapdisk for some specific reasons, like when using a shared block device (eg iSCSI), to avoid data corruption. However, when using local disks, this lack of online discard is kind of disappointing.Finally, even at this stage, this experiment is proof that we can combine both high performance while enjoying Xen "defense in depth" isolation in the middle.
🔮 What remains to be done
We still have a decent amount of work to obtain a stable and performant storage backend, even if the priority is to measure things first, we could decide to make it generally available at some point. And if we go there, some work will be needed regarding the integration in the toolstack, likely using the SMAPIv3 "framework".
Furthermore, tapdisk is a stable backend for XCP-ng and XenServer, as such it was given special care to optimize it in its scope. As such, not all IO behaviors are better using the SPDK backend, at least for now. For example, it will impact more the multi-thread IO applications than single-threaded ones. We will continue to work on this subject to have the best performance we can obtain from the hardware.
As you can see, the alternative SPDK backend provides a very interesting way to compare the performance with the existing stack, helping us to maybe find common bottlenecks and finally leading to better performance in all scenarios. As such, it won't end up directly in the platform on the short term, but you know that we are committed to improving it 🧑🔬


