
ZFS-ng: an intro on SMAPIv3
Following our overview of the existing storage stacks in XCP-ng, we wanted to share with you our initial work building a ZFS driver on top of the latest storage stack, called SMAPIv3. If you missed it, read our previous article for more details:
 Olivier Lambert
Olivier Lambert
Nonetheless, this article is still a first episode, and we'll test more things in future articles (different drives, configurations, RAID levels and so on).
BYOD: Build Your Own Driver
What's great with SMAPIv3 are the choices you have:
- you choose or create your own datapath (the way your data is read and written between the VM and the storage)
- you can build from scratch a "driver" to manage your volumes (virtual disk creation, deletion, snapshots…)
This level of choice allows you to get rid of the "VHD format"-monolith you had with SMAPIv1. For our first official PoC on top of SMAPIv3, we made the choice to create an implementation of ZFS volumes, using a "raw" datapath from tapdisk. No modification is needed from the VM at all.
xvda for example) and what's stored inside the Dom0 (eg a ZFS volume). It can work in raw or in vhd mode.In the future, we will probably build other datapath plugins for specific use cases or performance reasons. tapdisk is great but we imagine implementing completely custom stuff too (like… SPDK? 👼).
Getting most of the usual commands
Now that we've made our datapath choice, we have to write a volume driver. This is done by writing some mapping between VDI commands and what we'll tell the driver to execute (SR creation, volume commands and such).
In our ZFS case, a simple example is to tell it that a VDI.create will do a zfs create -V {volume_name} {volume_size} behind the scenes. The same applies for VDI.snapshot (yay! native ZFS snapshots!) and others, like VDI.destroy and such.
Native storage capabilities
It also means that our ZFS SMAPIv3 implementation won't have to deal with snapshot chains, which are basically copy-on-write chains that you have to coalesce yourself, since it will be entirely managed by ZFS itself (and its Zvols). Clearly, ZFS will be far more efficient than a custom program running in Dom0 to merge blocks in Copy on Write file format (vhd , qcow2 or whatever similar), and even read/write penalty to use a chain will be reduced since it will be entirely delegated by ZFS.
Wrapping everything
When you get all these commands, it's time to wrap it up and deploy the driver on your host. Then, it's up to you to create your SR without any specific ZFS knowledge:
xe sr-create type=zfs-ng name-label=zfsng device-config:file-uri=file:///dev/sdbThis will create the Zpool for you, while being ready to create new volumes:
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
zfsng 19,5G 422K 19,5G - - 0% 0% 1.00x ONLINE -Now, you can use Xen Orchestra to create your new disks, as if it was a normal Storage Repository.
Benchmarks
So how does the ZFS-ng driver compare vs the "legacy" (SMAPIv1) ZFS driver? If you don't remember, the SMAPIv1 ZFS driver is pretty basic:
- you need to create your ZFS pool manually
- then you tell the SMAPIv1 ZFS driver to use the mount point
- after that, it will create flat VHD files inside it
So you still rely on tapdisk in VHD mode, and all the coalesce work will be handled by SMAPIv1 (garbage collecting, coalescing and so on). All of this is avoided with the new ZFS driver.
lz4 by default since it's always a win.🐄 Requiem for a CoW
ZFS in "file system" mode is using CoW (in fact, it's actually a RoW: Redirect on Write, see this article). Adding a pseudo-filesystem on top of it is REALLY BAD. CoW-on-RoW (or Cow-on-CoW) will cause various amplifications in the datapath. We'll see how catastrophic it is in most situations, unlike using a "plain"/raw block storage for the VM disk (and leave the RoW doing the heavy lifting). Let's test!
Test setup
On the hardware side, we have an HPE ProLiant DL385 Gen10 with an AMD EPYC 7302, with XCP-ng 8.2.1 (8GiB RAM for the Dom0). The test VM is Debian 11, with 4 vCPUs and 4GiB RAM. The single test drive is a cheap Samsung QVO 1TiB SSD.
We obviously rely on fio to do our benchmarks. In random read/write, we use 4k blocksize. 4M is used for sequential. IOdepth is set to 128 and the size to bench is 10GiB on a 50GiB virtual disk. To compare apples to apples, we use lz4 compression on both drivers (legacy ZFS vs ZFS-ng).
Unless specified, we use fio directly on the guest device (eg /dev/xvdb) instead of using a filesystem on top of it.
Sequential throughput
First benchmark is without snapshot chain whatsoever, just one active disk:
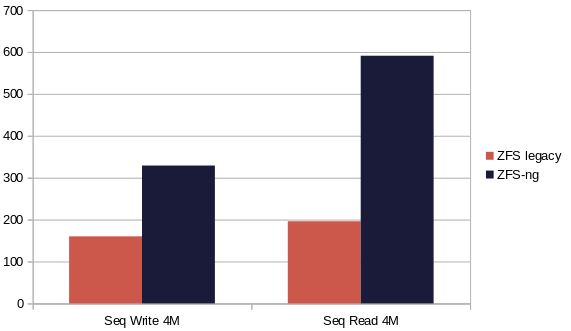
In sequential write, ZFS-ng is simply twice as fast vs storing VHDs on a ZFS filesystem. In read, it's even better: almost tripling the speed. But that's even not the most visible gap!
Random IOPS
Let's do the same benchmark with random reads and writes:
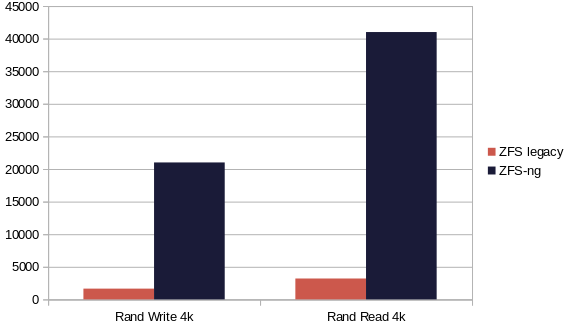
I should probably chose a log scale, because the difference is HUGE. In fact, in random read it's roughly 13 times faster, while being simply 12 times faster in random write.
And with a snapshot chain?
Let's see if having a snapshot will change something in both scenarios. We first create the disk, we snapshot it and finally then we add 10GiB with fio:
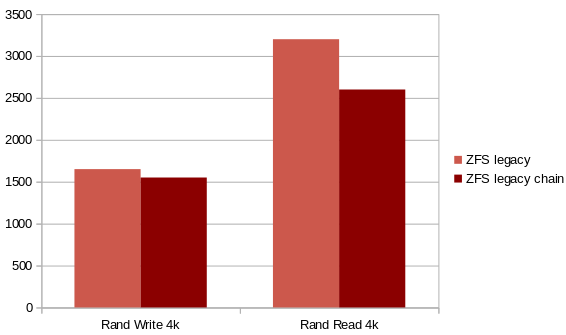
The impact is non-negligible in ZFS on SMAPIv1. Few % in random write, but larger in random read!
So what about the same test in SMAPIv3 with ZFS-ng?
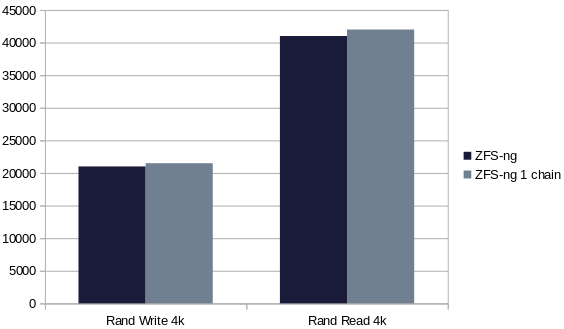
I will consider this an "overall" draw. So it means our current ZFS-ng driver doesn't suffer from read or write penalty when using a snapshot, at least at this small scale. I triple-checked the results, and yes, the snapshot is here:
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 4,14M 899G 108K /mnt/zfs
zfsng 51,6G 847G 47,5K /zfsng
zfsng/1 51,6G 889G 10,1G -
zfsng/2 0B 847G 12K -
Apples to apples?
Okay so we compared a storage using tapdisk with a copy-on-write file format inside (vhd mode) vs tapdisk in raw format leveraging ZFS storage capabilities (snapshots and so on). What if we use a raw format on top of SMAPIv1 ZFS storage (instead of VHD)? We can, thanks to a "custom" VDI create command:
xe vdi-create type=user sm-config:type=raw virtual-size=50GiB sr-uuid=<SR_UUID> name-label=rawdriveAnd the result is… the same! Regardless of tapdisk mode, ZFS on SMAPIv1 is slower because it relies on the ZFS filesystem layer, unlike ZFS-ng writing blocks all along the data path to the ZFS volume.
In short, using a file system like ZFS, with RoW/CoW capabilities without actually using them (because we rely on VHD format), is just a waste of resources.
Comparing against non-CoW filesystem
Okay but what about a local ext SR against our new ZFS-ng driver?
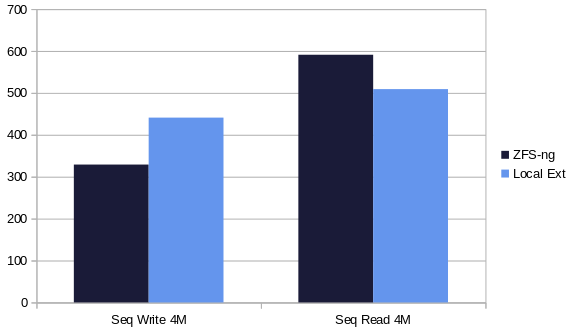
ext), the performance will be reduced for your first write benchmark. This is explained easily: when your VHD file grow with the writes, your local filesystem has to manage a growing file, using more resources. The overall penalty can grow up to 50% of capable write speed. Luckily, as soon the space is used, you'll enjoy the maximum speed. In production use-cases, this is barely visible. In our benchmarks here, we always do at least 3 runs and use the average between the last 2.Those results are interesting. ZFS-ng is a bit better in sequential read, which could be caused by the ZFS lz4 volume compression that we do not have with ext (so the result is more variable depending on the data set). In sequential write, the speed with local ext is still better. In the end, that's likely because ext is far more simple (ie "dumb") so there's less overhead.
But we can say that using a CoW file based storage (VHD) on top of a "non-CoW" filesystem (like ext4) works very well, since we can even reach 50k IOPS. At least for one virtual disk and one physical disk. But keep in mind that in VHD mode, the Dom0 will have to deal with the whole chain logic by itself (coalesce, garbage collecting removed snapshots and so on). The toll of doing this is in fact bigger than we can imagine:
- when you have tons of VHD files, each rescan/cleanup will take longer
- coalescing multiple chains is also taking a lot of resources
- race conditions are very dangerous if your code isn't perfect (eg: one missing parent and the whole chain is dead!)
All of this can be dealt with directly by your favorite CoW/RoW filesystem, like ZFS, leaving the Dom0 to focus on better things: less complexity, less risks, more mature dedicated solutions for your data, and so on.
But also… what about having ZFS managing your RAID? Mirrors, RAIDz and so on: ZFS is offering you a very powerful storage solution. In a coming article, we'll test up to 4 drives in RAIDz1, RAIDz2 and 2x mirrored vdev against a equivalent mdadm solution with ext4 on top, and see the results.
Does it scale?
One usual known bottleneck of SMAPIv1 is the performance per disk (which is the worst case scenario). Luckily, when you use multiple disks with multiple VMs, SMAPIv1 in VHD actually scales. We regularly see SMAPIv1 pools saturating very fast shared storage. Expect some benchmarks soon with multiple VMs/disks with this driver to see if it scales, but since we use a very similar datapath, I'm pretty sure it will. Stay tuned!
Another datapath?
It's also possible to test another datapath, since it's relatively simple in that case, using raw blocks. However, tapdisk is pretty mature and efficient. Another alternative is to tweak tapdisk to use faster code to read/write on a device, like io_uring. And yes, there's also plans for it! Damien, our PhD at Vates, is also working on getting an SPDK datapath for NVMe drives, which should bring very powerful storage performances! The future of storage in XCP-ng is VERY exciting!
What's missing then?
This first PoC ZFS-ng driver will be obviously available for those who want to test it (look for a announcement on our forum soon). We are integrating cool features pretty fast like the ability to create multiple kinds of ZFS setups (mirrors, RAIDZ1, Z2…) without using any ZFS commands. So your xe sr-create command will do everything for you when you pass the right parameters.
So what's left? Right now, the elephant in the room is the inability to migrate a VDI from SMAPIv1 to SMAPIv3, at all. Right now, you simply can't migrate any VDI at all in the SMAPIv3 world. And obviously, no live storage migration either. These are the things we are exploring. Another detail: you don't have any IOPS/throughput reporting view for SMAPIv3 SRs yet (no RRDs data exported so nothing visible in XO).
What about backup and delta capabilities? Some tests need to be done, but we'll clearly need to adapt Xen Orchestra to it: for that, we'll likely rely on NBD and that will be very interesting vs VHD export. Indeed, our initial tests are showing a LOT better performance in NBD than in VHD. But again, some pieces are missing, more news on this later 😊
Conclusion
I hope you liked this "tour" on the current ZFS PoC we are working on. By the way, if you are passionate about low-level storage solutions, we are hiring 😉


