DR backup - Error: IMPORT_ERROR_PREMATURE_EOF()
-
I'm testing dr backup but have some error - what could be the reason of that?
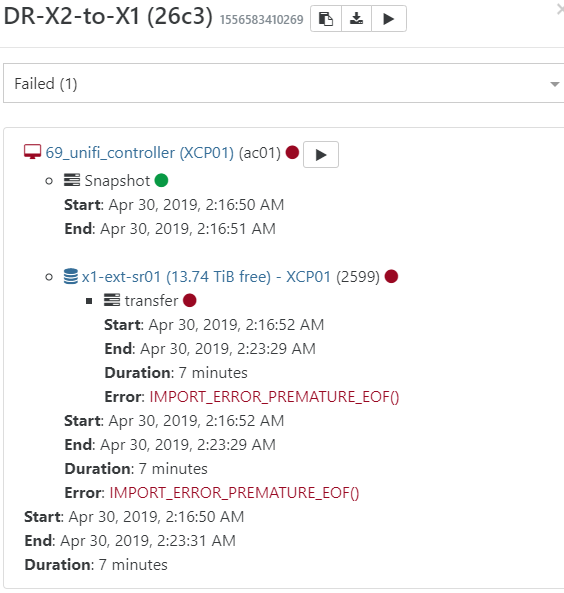
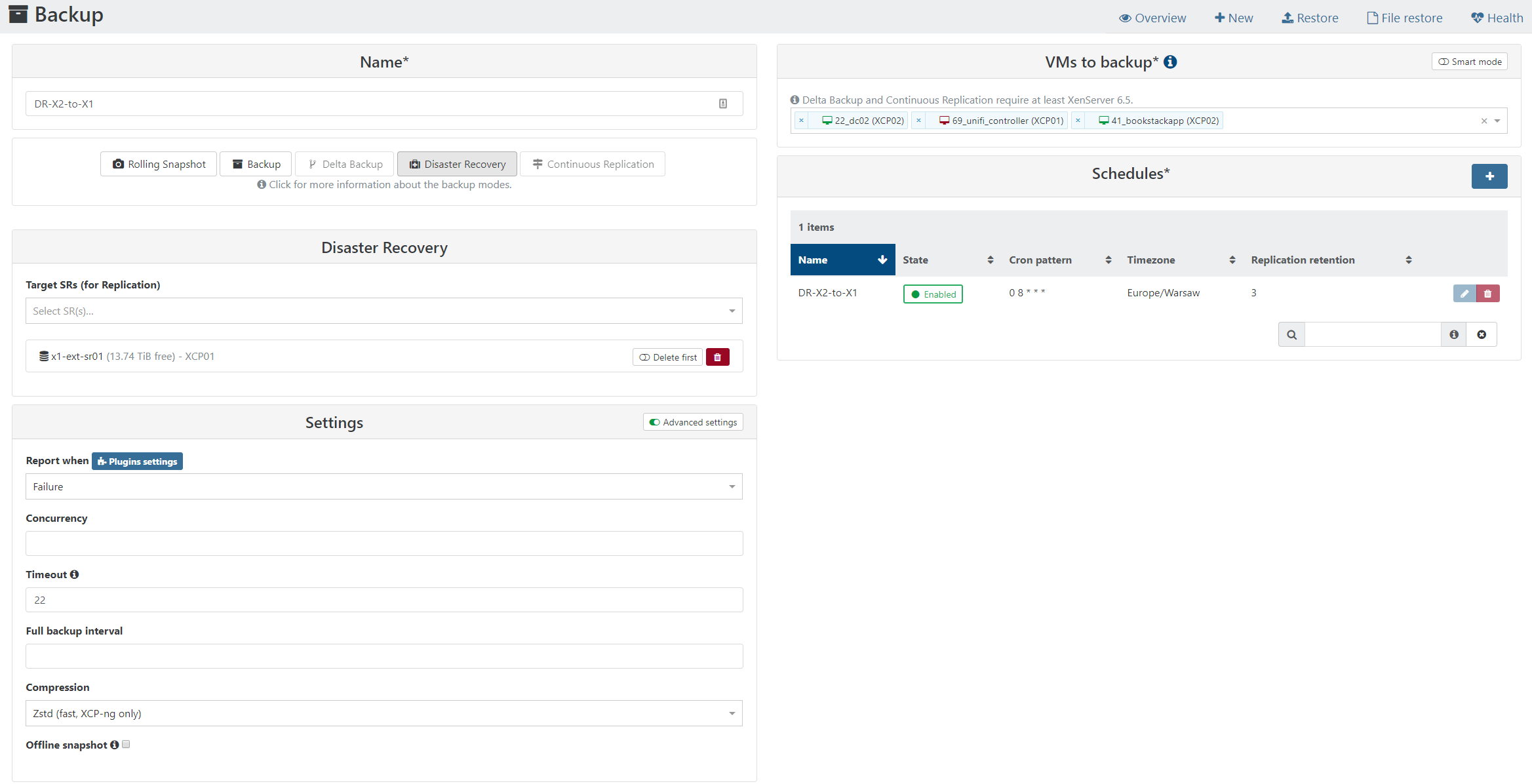
69_unifi_controller (XCP01) (ac01) Snapshot Start: Apr 30, 2019, 2:16:50 AM End: Apr 30, 2019, 2:16:51 AM x1-ext-sr01 (13.74 TiB free) - XCP01 (2599) transfer Start: Apr 30, 2019, 2:16:52 AM End: Apr 30, 2019, 2:23:29 AM Duration: 7 minutes Error: IMPORT_ERROR_PREMATURE_EOF() Start: Apr 30, 2019, 2:16:52 AM End: Apr 30, 2019, 2:23:29 AM Duration: 7 minutes Error: IMPORT_ERROR_PREMATURE_EOF() Start: Apr 30, 2019, 2:16:50 AM End: Apr 30, 2019, 2:23:31 AM Duration: 7 minutesThis is my backup setup (DR-X2-to-X1):
-
Double check all your XCP-ng hosts are up to date (source and destination host). It seems the exported file isn't recognized correctly on destination (
zstdformat).Otherwise, try without compression to see if it comes from this issue.
-
Everything up to date. Problem gone on next backup. Where to start to troubleshoot this situation in future? Do we already have a github section troubleshooting xcp-ng?
-
Just ping again in this thread if it happens again. I'd like to have GH issues only on reproducible problems to avoid bothering devs without enough content to start tracking a bug
")
-
Of course. But I'm talking about whole section with information of where to start troubleshooting common problems
-
For anyone else who comes across the same issue, we had this occur with XCP-ng 8.2 , XO-server 5.71.2 which we isolated to using Zstd compression. It was solved by reducing concurrency and assigning a couple of extra vCPUs.
In response to @olivierlambert's point above - it is 100% reproducible if you have an under-resourced XO and fast target remote so the bottleneck becomes the CPU rather than iowait or memory acting as a throttle, but in our instance only for VMs of a reasonable size (>50gb) containing complex databases with lots of incompressible data.
-
How could XO could be a problem? zstd is done on the host side, not in XO.
-
@olivierlambert Can't answer that I"m afraid. It's reproducible, and the above resolved the issue, and if I limit the CPU resource to XO then it re-occurs. Potentially the issue is less in Zstd and more in terms of how the resource queuing works? I can't tell why, simply that there was an issue and above solved it, and I can reverse the change and have the problem re-occur.
Can send over logs of before and after if it helps?
-
We are using Node streams with back pressure. So it shouldn't be the case. Maybe zstd behavior is a bit different and when it waits for a while it drops, I don't know.
-
@shorian Thanks for your response. Please see my new thread https://xcp-ng.org/forum/topic/3971/unable-to-export-reliable-backups/1
I tried adding more vCPUs and even upped the RAM to XOA to 8gig. It starts to generate a backup but then dies out 1-5GB into a 50GB output XVA.
Ideas?
-
@bsodmike Increase memory to node.js as described in the docs under memory management. Adding mem to VM is insufficient in isolation, so my post above may have been misleading (sorry!).
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login