Best CPU performance settings for HP DL325/AMD EPYC servers?
-
@fohdeesha Thanks for the feedback! I did enable the NUMA setting but can't really tell if it made any different in XCP-ng. There is no new information in dmesg and I don't have
numactlornumastatpackages in XCP-ng. -
I think it's normal because NUMA is handled at Xen level, not from Linux kernel (pinging @dthenot )
-
I think it's normal because NUMA is handled at Xen level, not from Linux kernel (pinging @dthenot )
I had a look at http://manpages.ubuntu.com/manpages/trusty/man7/numa.7.html which seems to indicte that the kernel isn't configured with
CONFIG_NUMAas there is no/proc/<pid>/numa_mapsfile.But as you say, it might be handled in Xen and not in guests/dom0. A freshly booted Ubuntu guest says this in dmesg:
# dmesg |grep numa -i [ 0.018056] No NUMA configuration found -
@olivierlambert @S-Pam Indeed, it's normal, Dom0 doesn't see the NUMA information and the hypervisor handle the compute and memory allocation. You can see the wiki about manipulating VM allocation with the NUMA architecture if you want. But in normal use-cases it's not worth the effort.
-
Thanks!
The link to https://wiki.xenproject.org/wiki/Xen_on_NUMA_Machines explains it pretty well.
xl info -nshows numa config# xl info -n host : srv01 release : 4.19.0+1 version : #1 SMP Tue Mar 30 22:34:15 CEST 2021 machine : x86_64 nr_cpus : 48 max_cpu_id : 47 nr_nodes : 8 cores_per_socket : 24 threads_per_core : 2 cpu_mhz : 2794.799 hw_caps : 178bf3ff:76f8320b:2e500800:244037ff:0000000f:219c91a9:00400004:00000500 virt_caps : pv hvm hvm_directio pv_directio hap shadow total_memory : 65367 free_memory : 10394 sharing_freed_memory : 0 sharing_used_memory : 0 outstanding_claims : 0 free_cpus : 0 cpu_topology : cpu: core socket node 0: 0 0 0 1: 0 0 0 2: 1 0 0 3: 1 0 0 4: 2 0 0 5: 2 0 0 6: 4 0 1 7: 4 0 1 8: 5 0 1 9: 5 0 1 10: 6 0 1 11: 6 0 1 12: 8 0 2 13: 8 0 2 14: 9 0 2 15: 9 0 2 16: 10 0 2 17: 10 0 2 18: 12 0 3 19: 12 0 3 20: 13 0 3 21: 13 0 3 22: 14 0 3 23: 14 0 3 24: 16 0 4 25: 16 0 4 26: 17 0 4 27: 17 0 4 28: 18 0 4 29: 18 0 4 30: 20 0 5 31: 20 0 5 32: 21 0 5 33: 21 0 5 34: 22 0 5 35: 22 0 5 36: 24 0 6 37: 24 0 6 38: 25 0 6 39: 25 0 6 40: 26 0 6 41: 26 0 6 42: 28 0 7 43: 28 0 7 44: 29 0 7 45: 29 0 7 46: 30 0 7 47: 30 0 7 device topology : device node 0000:00:03.1 6 0000:c3:00.0 0 0000:80:07.1 2 0000:c0:03.1 0 0000:00:08.0 6 0000:c0:08.0 0 0000:c5:00.3 0 0000:00:18.3 6 0000:02:00.2 6 0000:40:05.0 4 0000:c2:00.2 0 0000:80:02.0 2 0000:43:00.0 4 0000:40:03.1 4 0000:c1:00.4 0 0000:40:08.0 4 0000:c5:00.1 0 0000:00:18.1 6 0000:02:00.0 6 0000:00:01.0 6 0000:c2:00.0 0 0000:42:00.2 4 0000:80:05.0 2 0000:c0:01.0 0 0000:40:01.2 4 0000:01:00.2 6 0000:c1:00.2 0 0000:80:03.1 2 0000:00:04.0 6 0000:80:08.0 2 0000:42:00.0 4 0000:c0:04.0 0 0000:00:14.3 6 0000:40:01.0 4 0000:82:00.2 2 0000:01:00.0 6 0000:c1:00.0 0 0000:41:00.2 4 0000:00:07.0 6 0000:c0:07.0 0 0000:40:04.0 4 0000:00:00.2 6 0000:82:00.0 2 0000:80:01.0 2 0000:c0:00.2 0 0000:00:18.6 6 0000:41:00.0 4 0000:81:00.2 2 0000:c0:01.5 0 0000:40:07.0 4 0000:00:00.0 6 0000:80:04.0 2 0000:c0:00.0 0 0000:40:00.2 4 0000:00:08.1 6 0000:c0:08.1 0 0000:00:18.4 6 0000:02:00.3 6 0000:81:00.0 2 0000:00:03.0 6 0000:80:07.0 2 0000:c0:03.0 0 0000:40:00.0 4 0000:80:00.2 2 0000:40:08.1 4 0000:c5:00.2 0 0000:00:18.2 6 0000:00:01.1 6 0000:42:00.3 4 0000:c0:01.1 0 0000:40:03.0 4 0000:80:00.0 2 0000:c5:00.0 0 0000:00:18.0 6 0000:80:08.1 2 0000:42:00.1 4 0000:40:01.1 4 0000:c1:00.1 0 0000:80:03.0 2 0000:00:07.1 6 0000:c0:07.1 0 0000:80:01.1 2 0000:00:02.0 6 0000:00:18.7 6 0000:c0:02.0 0 0000:40:07.1 4 0000:00:14.0 6 0000:c3:00.2 0 0000:00:05.0 6 0000:00:18.5 6 0000:c0:05.0 0 0000:40:02.0 4 numa_info : node: memsize memfree distances 0: 10240 1505 10,11,11,11,11,11,11,11 1: 8192 1918 11,10,11,11,11,11,11,11 2: 8192 1932 11,11,10,11,11,11,11,11 3: 8192 847 11,11,11,10,11,11,11,11 4: 8192 912 11,11,11,11,10,11,11,11 5: 8192 912 11,11,11,11,11,10,11,11 6: 8192 1038 11,11,11,11,11,11,10,11 7: 8179 1326 11,11,11,11,11,11,11,10 xen_major : 4 xen_minor : 13 xen_extra : .1-9.9.1 xen_version : 4.13.1-9.9.1 xen_caps : xen-3.0-x86_64 xen-3.0-x86_32p hvm-3.0-x86_32 hvm-3.0-x86_32p hvm-3.0-x86_64 xen_scheduler : credit xen_pagesize : 4096 platform_params : virt_start=0xffff800000000000 xen_changeset : 6278553325a9, pq 70d4b5941e4f xen_commandline : dom0_mem=4304M,max:4304M watchdog ucode=scan dom0_max_vcpus=1-16 crashkernel=256M,below=4G console=vga vga=mode-0x0311 sched-gran=core cc_compiler : gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-28) cc_compile_by : mockbuild cc_compile_domain : [unknown] cc_compile_date : Thu Feb 4 18:23:36 CET 2021 build_id : a76c6ee84d87600fa0d520cd8ecb8113b1105af4 xend_config_format : 4I wonder if the CPU scheduler can do NUMA node in addition to core, CPU and socket?
-
@s-pam said in Best CPU performance settings for HP DL325/AMD EPYC servers?:
I wonder if the CPU scheduler can do NUMA node in addition to core, CPU and socket?
I'll answer myself here. It seems that Xen already does this by default:
NUMA aware scheduling, as it has been included in Xen 4.3, means that it is possible for vCPUs of a domain to just prefer to run on the pCPUs of some NUMA node. The vCPUs will still be allowed, though, to run on every pCPU, guaranteed much more flexibility than having to use pinning.
-
Sorry for spamming the thread.
")
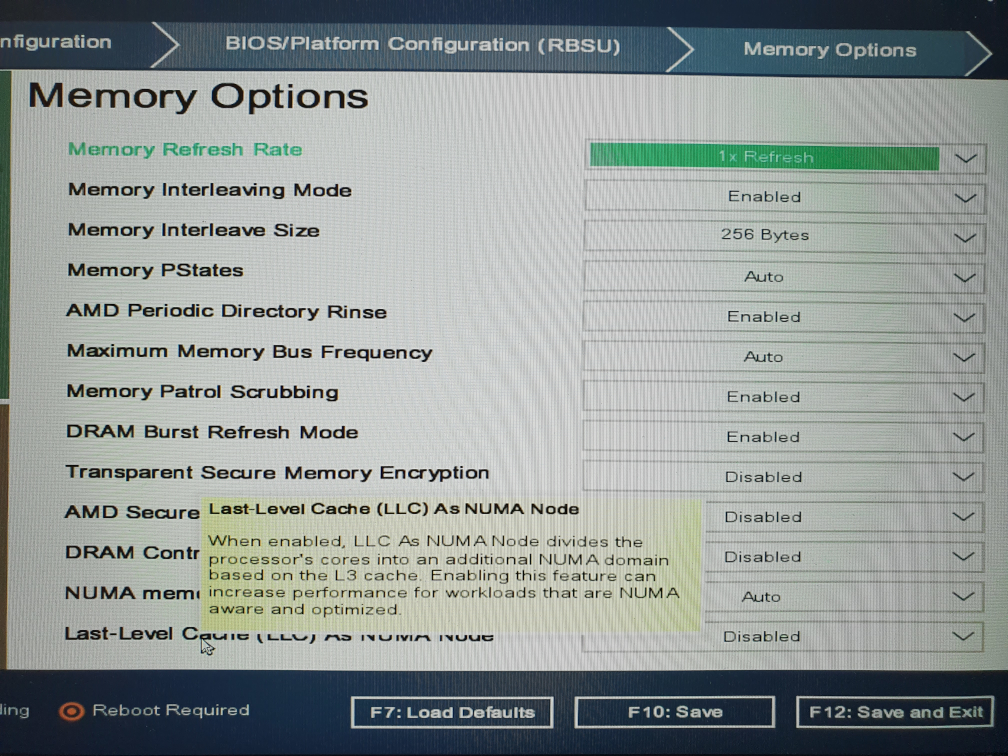
I have two identical servers (srv01 and srv02) with AMD EPYC 7402P 24 Core CPUs. On srv02 I enabled the
LLC as NUMA Node.I've done some quick benchmarks with
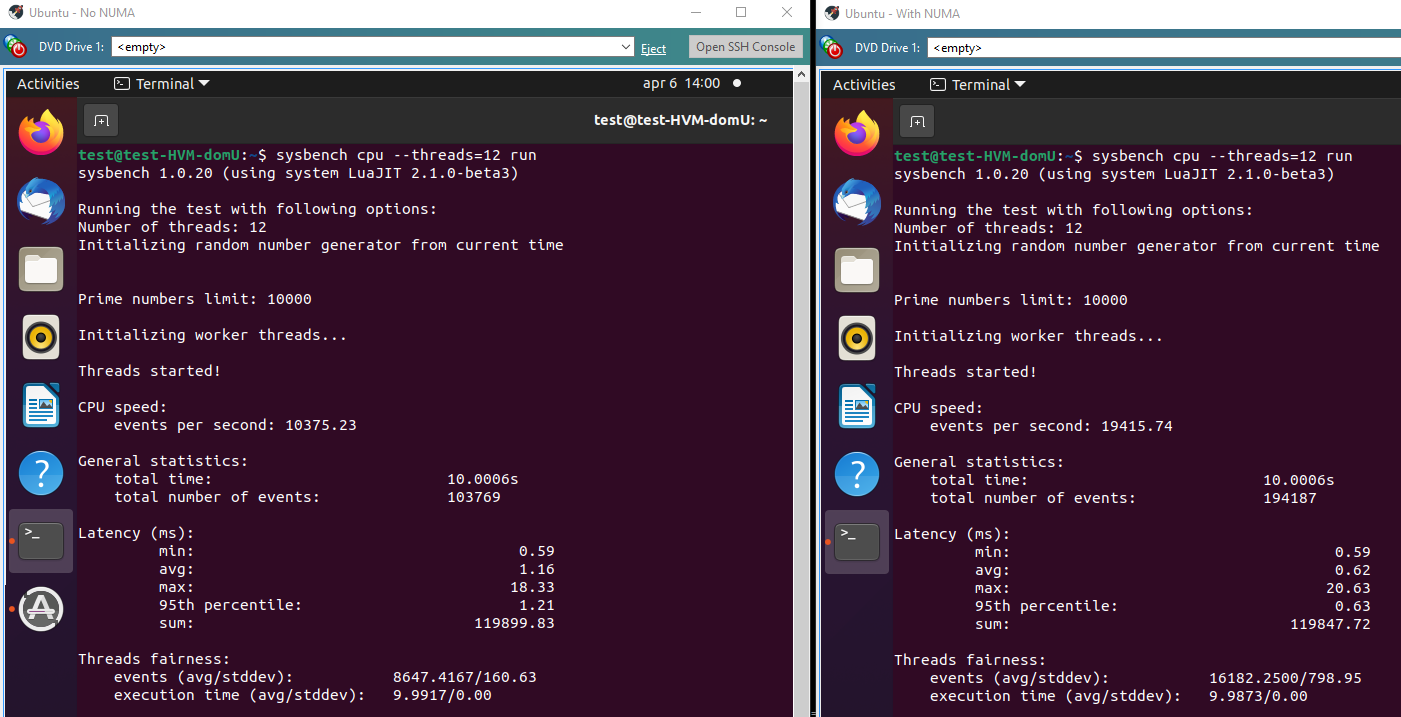
Sysbenchon Ubuntu 20.10 with 12 assigned cores. Command line:sysbench cpu run --threads=12It would seem that in this test the NUMA option is much faster, 194187 events vs 103769 events. Perhaps I am misunderstanding how sysbench works?
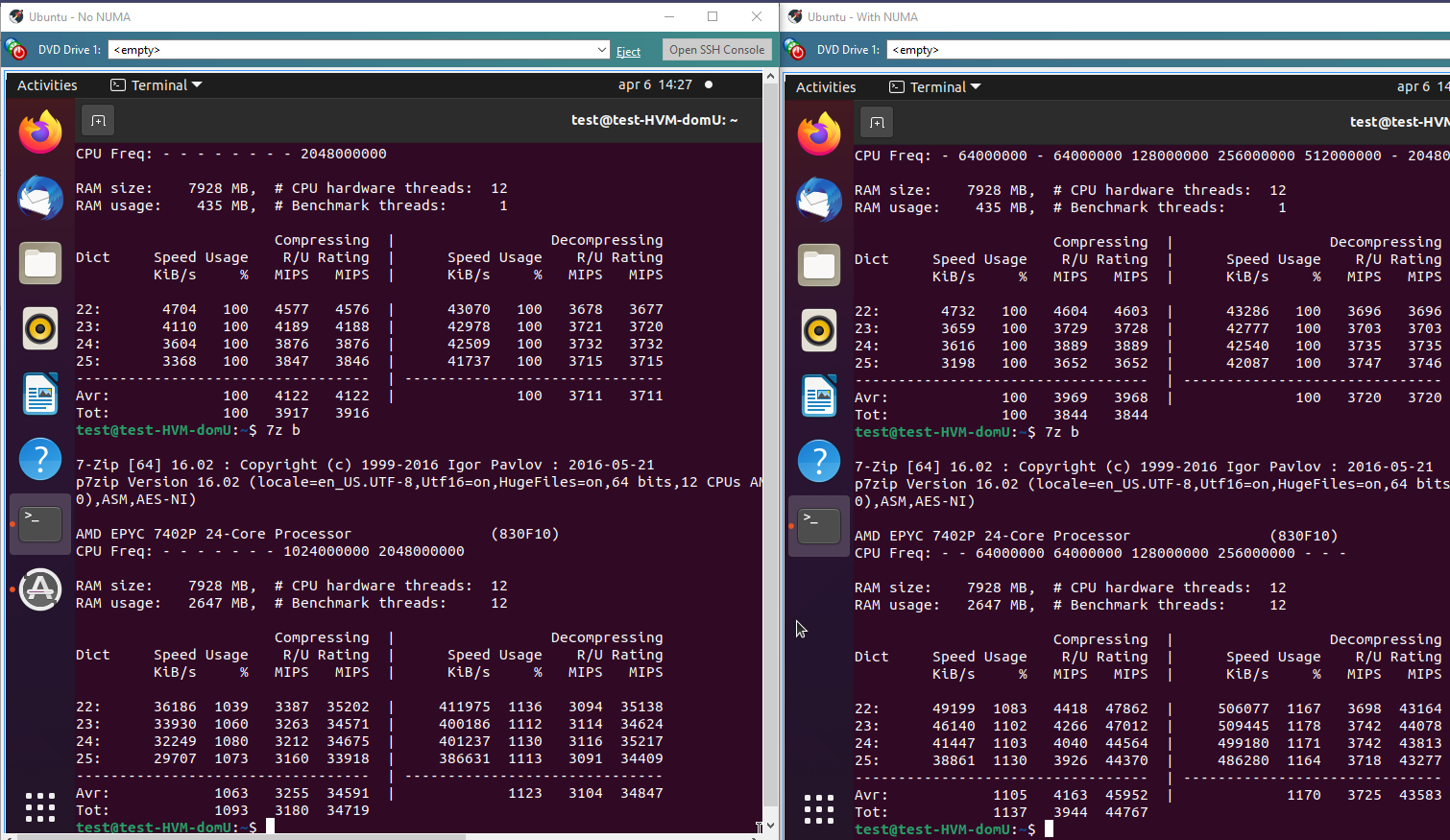
With 7-zip the gain is much less, but still meaningful. A little slower in single-threaded performance but quite a bit faster in multi-threaded mode.
-
I ran a simulation run with Dassault's SIMULIA Abaqus FEA. Simulation went down from 75 to 60 minutes, so a big win there too
")
-
It's not spam, it's interesting feedback
Never hesitate to share it! -
@olivierlambert said in Best CPU performance settings for HP DL325/AMD EPYC servers?:
It's not spam, it's interesting feedback
Never hesitate to share it!Thanks!
The last benchmark is a real-world example. We have a master thesis student that needs to run approximately 150 simulations as part of the program and she is pretty thrilled to be saving several days on the run time
-
That's great! I think @dthenot would be interested reading this

-
@s-pam Damn, computer are really magic. I'm very surprised about these result.
Does the NONUMA really mean no NUMA info being given by the firmware?
I have no idea how the scheduler of Xen uses this information, I know that the memory allocator strip the memory of the VM on all nodes the VM is configured to be allocated on. As such it would mean the scheduler is doing good work on scheduling the VCPU on nodes, without even knowing about the memory positioning of the current process running inside the guest.
Did you touch anything in the config of the guest? It's interesting result nonetheless. Can you share the memory allocation of the VM? You can obtain it withxl debug-keys u; xl dmesgfrom the Dom0. -
@dthenot said in Best CPU performance settings for HP DL325/AMD EPYC servers?:
@s-pam Damn, computer are really magic. I'm very surprised about these result.
Does the NONUMA really mean no NUMA info being given by the firmware?
I have no idea how the scheduler of Xen uses this information, I know that the memory allocator strip the memory of the VM on all nodes the VM is configured to be allocated on. As such it would mean the scheduler is doing good work on scheduling the VCPU on nodes, without even knowing about the memory positioning of the current process running inside the guest.
Did you touch anything in the config of the guest? It's interesting result nonetheless. Can you share the memory allocation of the VM? You can obtain it withxl debug-keys u; xl dmesgfrom the Dom0.I can't look at the dmesg today as I'm home with a cold...

Configuration between the two servers are identical except that on the "NUMA" one I enabled
Last-Level Cache as NUMA nodein the BIOS. When this is enabled I can see there are now 8 NUMA nodes inxl info -n.The VM was identical too. I just made a fast-clone and run it parallell on each server. I also migrated the VMs back and forth between the two servers to verify that the results were correct.
I did experiment with
xl cpupool-numa-splitbut this did not generate good results for multithreaded workloads. I believe this is because VMs get locked to use only as many cores as there are in each NUMA domain and this 7402P CPU has 24 cores with only 3 in each CCX. -
@s-pam
I can't look at the dmesg today as I'm home with a cold...
I hope you get well soon
I did experiment with
xl cpupool-numa-splitbut this did not generate good results for multithreaded workloads. I believe this is because VMs get locked to use only as many cores as there are in each NUMA domain.Indeed, a VM in a pool get locked to use only the cores of the pool and its max amount of VCPU being the number of core in the pool. It is useful if you have the need to isolate completely the VM.
You need to be careful when benching these things because the memory allocation of a running VM is not moved but the VCPU will still run on the pinned node. I don't remember exactly if cpu-pool did have a different behavior than simple pinning in that case though. I remember that hard pinning a guest VCPU were not definitely not moving its memory. You could only modify this before booting.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login