-
Redhat has EOL'ed the oVirt downstream projects RHGS (Gluster storage) and RHV (virtualization orchestration) so I am looking for a new home.
So this first post is also about the philosophical differences, which you may find interesting.
What I found attractive about Gluster is that it's a file layered abstraction, that doesn't even implement a file system, but just uses the one below (e.g. ext4 or xfs) with a very smart overlay. It supports replicated or erasure coded dispersed storage at file level, but adds a chunking layer in case your files are in fact machines or databases and too big to ensure fair load distribution without. Unfortunately Gluster and oVirt were never properly aligned and the flexibility of Gluster never quite carried over into oVirt's HCI templates (e.g. dispersed volumes with dynamic growth in the number of bricks).
It was also decoupled in the sense, that not every HCI node needs to be the same size or even contribute all parts: should you have nodes with lots of storage but little compute and vice versa, you can have them contribute only those attractive parts. In my lab made of left-overs and some hot-shot elements, that was a good match.
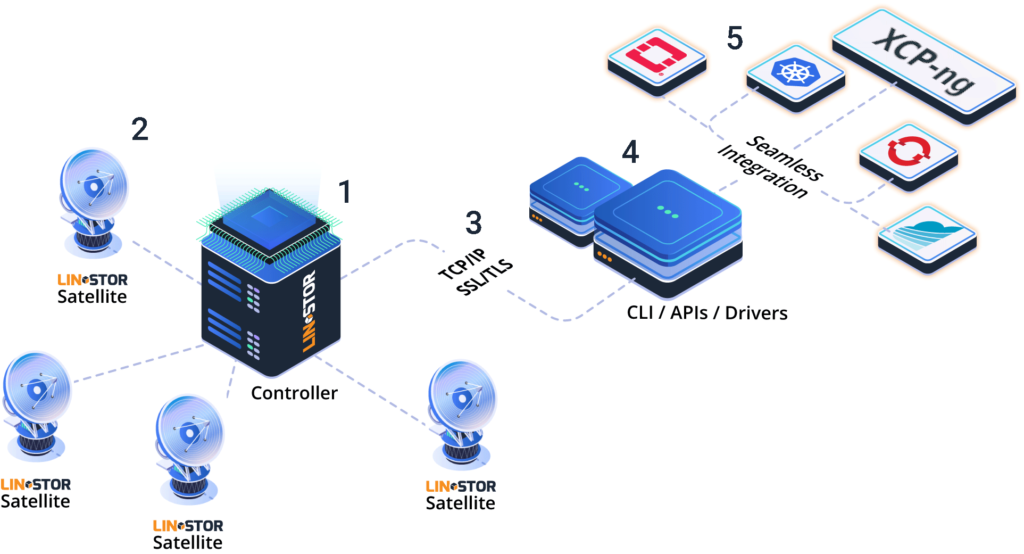
LINSTOR is blocks and feels much more like a HCI-SAN. With Xcp-ng storage needs to "look" local, so either it really is, or you contribute at least parts. Actually, since the current setup seems to be full replica-only, you do always have a full copy of all blocks. I hope the big advantage vs. Gluster will be bullet-proof simplicity, perhaps even performance: Gluster had me bite my nails far too often, until healing had completed without issues.
Full replica mode obviously has a huge impact on performance. Since I am just testing currently, I am using a setup based fully on nested virtualization. So hosts are in fact VMs run on VMware workstation on a single machine with lots of RAM and NVMe storage.
Setup is unbelievably quick (compared to an oVirt 3node HCI install) and I quite enjoyed playing around with the provided and the self-compiled orchestrator: I quite like that the xoa is so fully stateless, that I can have one run as a VM inside and another say as a VM on a laptop's VirtualBox in case the former has gone titsup. An oVirt/RHV management engines that fail to start on an oVirt cluster is very scary, let me tell you!
It's typically there and then when you notice that your Postgres management database backup is more than a little stale.I started with 5 nodes, wanting to go with the smallest dispersed configuration, but only replica seems supported for now. When VMs failed to start after having been moved to XOSAN, I got a little scared until I understood that the fifth node happened to be the one the VM was to be started on, and that didn't participate in XOSAN and therefore couldn't run the VM...
After its removal things behaved as expected: Seamlessly!
Performance is as you'd expect from the 4x replica: Write-performance on XOSAN is 25% of read performance, while with local storage the two are very much the same.
I very much dislike VDI being used to mean disks (far too many other usages), but I like the ease of moving them between storage repositories. Moving disks between storage domains or between different farms in oVirt was a major nightmare with plenty of bugs.
The Windows host I am using to run the "virtual bare metal" was actually running out of space while I was migrating a disk from local storage to XOSAN (meaning 5x storage required temporarily), which meant all hosts got suspended on write failures and I couldn't even log into the machine to create some room.
That is not quite the complete power loss on a data centre but still something that should never happen.
I got the super-host machine to restart via the power button (shutdown, not power cycle or reset) and fully expected some serious damage even if only the xoa VM was actually running...
But no, no damange was done. I could restart all nodes and the xoa VM.
While the XOSAN image copy was incomplete, the original local storage disk was still intact and after I had created the proper space the operation could just be repeated.Such failure testing is a lot more fun using nested virtualization with consistent snapshots to recover from and that's what I'll be playing with a little more to gain confidence in the whole thing: so far it's looking very good!
Please let me know ASAP, when a dispersed option is available so I can start testing the really interesting variants!
And perhaps you could add a VDO (deduplication/LZ4 compression) option to the nodes? I used the full set of options on oVirt, VDO and thin allocation to ensure I got every last bit of space out of those pricey NVMe SSDs...
-
Hi @abufrejoval
I truly loved the Gluster approach we used with XOSAN (one big filesystem, simple, robust), but sadly it's pretty slow in 4k random read/write

That's why we decided to keep the Gluster driver for people who wanted to keep using it, but focusing on block replication for XOSTOR, based on LINSTOR.
However, in the future, with the new storage stack (SMAPIv3), we might decide to re-bench all of this and provide another alternative, Gluster based
")
-
Salut Olivier,
yes, I saw your Gluster support but it seems that Redhat is ready to let it die. I believe it had a major brain drain some time ago and suffered from lack of adoption and evolution since.
And quite honestly, when something isn't quite right, it can be nerve wrecking and very hard, if not impossible, to fix. In the most typical HCI scenario with 2 replicas and 1 arbiter I found myself recreating the replica and arbiter (can't be done in a single operation either) too often, when perhaps only a couple of blocks might have been really bad.
In short, they current state of Gluster isn't quite good enough and with Redhat discontinuing the commercial product, it's hard to believe it will ever get there.
But VDO (hint, hint!) is still there
")
-
Yeah I did some tests on VDO, but I have to admit I only used it for compression I think
 What's the state of it from your perspective?
What's the state of it from your perspective? -
Well, at least it doesn't seem to be one of Redhat's acquisitions that's EOL yet.
I've used it perhaps without thinking it through all too well on all my oVirt setups, mostly "because it's an option you can tick". It was only afterwards that I read that it shouldn't be used in certain use cases, but Redhat is far from consistent in its documentation.
I've searched for a studies/benchmark/recommendations and came up short, apart from a few vendor sponsored ones.
I support a team of ML researchers and they have massive amounts of highly compressible data sets, which they then compressed and de-compressed manually, often enough with both of them lying around afterwards.
So there my main intent was to just let them store the stuff how it's easiest to use, as plain visible data, and not worry about storage efficiency. There LZ4 code and the bit manipuliation support in today's CPUs seem to work faster than any NVMe storage and they use it mostly in large swaths of sequential pipes. In ML even GPU memory is far too slow for random access so I'm not concerned about storage IOPS.
It's actual use case seems to have come from VDI (that's virtual desktop infrastructure!) or Citrix' old battle ground, where tons of virtual desktop images might fill and bottleneck the best of SANs in a morning's boot storm.
Again, I like its smart approach, which isn't about trying to guarantee the complete elimination of all duplicate blocks. Instead it will eliminate the duplicates that it can find in its immediate reach within a fixed amount of time and effort, by doing a compression/checksum run on any block that is being evicted from cache to see if it's a duplicate already: compression pays for the effort and the hash delivers the dedup potential on top! Just cool!
So if you have 100 CentOS instances in your farm, there is no guarantee it will avoid you having duplicates of all code or indeed even eliminating a single one, because they might never be in the same cache on the same node or the same offset as they are being written (no lazy duplicate elimination going on the background).
And then it just very much depends on your use case, whether there will actually be any benefit, of if it's just needlesly spent CPU cycles and RAM.
Operationally it's wonderfully transparent on CentOS/RHEL and even fun to set up with Cockpit (not so much manually). When VDO volumes are consistent, they are also recoverable even without any external metadata e.g. from another machine, which is a real treat. I don't think that they record their hashes as part of the blocks they write, which could be great to deliver some ZFS like integrity checks.
But it just takes a single corrupted block, to make everything on top get unusable, which I've seen happen when an onboard defective RAID controller got swapped with a motherboard and data had only been committed to the BBU backed cache.
That's where Gluster helped out and why I think they might compensate a bit for each other with VDO compensating the write amplification of Gluster and Gluster the higher corruption risk of compressed data and opaque data structures.
And with Gluster underneath, it's never felt like the bottleneck was in VDO
-
 O olivierlambert referenced this topic on
O olivierlambert referenced this topic on
-
So my first XOASAN tests using nested virtual hosts were rather promising so I'd like to move to physical machines.
Adding extra disks on virtual hosts is obviously easy, but the NUCs I'm using for that only have one single NVMe drive each without any option to hide the majority of the space e.g. via a RAID controller. The installer just grabs all of that for the default local storage and I have nothing left for XOASAN.
It does mention an "advanced installation option" somewhere in those dialogs, but that never appears.
Any recommendation on how to either keep the installer from grabbing everything or shrink the local storage after a fresh install?
-
Hi @abufrejoval
Just having a doubt: it's now called XOSTOR, so you tested XOSTOR right?
Regarding your installer question: you can uncheck the disk for VM storage, then it will leave free space on the disk after the installation
-
sorry, XOSTORE of course
And why did I think I had already tried that?
Must be late...
Merci!
-
You are welcome and thanks a lot for your tests! It's very important for us to have external users playing with it
-
Hi,
I have been able to create a small lab with 2 xcp-ngs and would like to use the XOSTOR. First I create a first xcp-ng box (xcp-ng-01) create a new XOSTOR with all the command above. All is working. I have a new SR with 1 host only.
Now If I want to add a new host to the SR how can I do this ? I would like to simulate adding new host/disk to the SR. Is it possible ?
-
Hi, the 8.2.1 test five image wouldn't let me install XOSTOR yet (and it wasn't recommended): so is this release variant again compatible with XOSTOR?
-
@abufrejoval @ronan-a has updated the test packages in the linstor test repository, so it should.
-
I tried to do the setup with 3 hosts, and followed the commands. Now I get this error when I try to create the SR.
xe sr-create type=linstor name-label=XOSTOR host-uuid=43b39fc0-002f-4347-a3e8-16e1284cfcb3 device-config:hosts=xcp-ng-01,xcp-ng-02,xcp-ng-03 device-config:group-name=linstor_group/thin_device device-config:redundancy=3 shared=true device-config:provisionning=thinError code: SR_BACKEND_FAILURE_5006 Error parameters: , LINSTOR SR creation error [opterr=Could not create SP `xcp-sr-linstor_group_thin_device` on node `xcp-ng-01`: (Node: 'xcp-ng-01') Expected 3 columns, but got 2],No idea of what I need to do with this error. looks like an error when inserting into the DB.
-
Let me ping @ronan-a
-
@dumarjo Well, check if the lvm group is activated using
vgchange -a y [group]. -
@ronan-a I did this on all this server and now the SR is up.
For the sake of scalability, is it possible to add a new host or a new disk in a host easily ? Do you have a tips about it ?
Regards,
-
@dumarjo Well, for the moment we don't have a script to do that. But you can modify manually the linstor database:
- You must find where is running the controller (for example with the command:
linstor) - Then execute this command on the host to add:
linstor --controllers=<CONTROLLER_IP> node create --node-type combined $HOSTNAMEwhereCONTROLLER_IPis given by the first step. - If you want to add a new disk, you must create a LVM/VG group with the name used in the other storage pools:
linstor --controllers=<CONTROLLER_IP> storage-pool list. - Than you can create the storage pool:
linstor --controllers=<CONTROLLER_IP> storage-pool create {lvm or lvmthin} $HOSTNAME <STORAGE_POOL> <POOL_NAME>(Check the two last params are the same in the DB.) - The PBDs of the current SR must be modified to use the new host, and a PBD must be created on the new host.
It's a little bit complex. So I think I will add a basic script to configure a new host or to remove an existing one. I do not recommend the usage of these commands, except in the case of tests.
- You must find where is running the controller (for example with the command:
-
@ronan-a said in XOSTOR hyperconvergence preview:
- The PBDs of the current SR must be modified to use the new host, and a PBD must be created on the new host.
I'm relatively new with xcp-ng, and I'm a bit lost for this part. I'll give you more info on my current setup
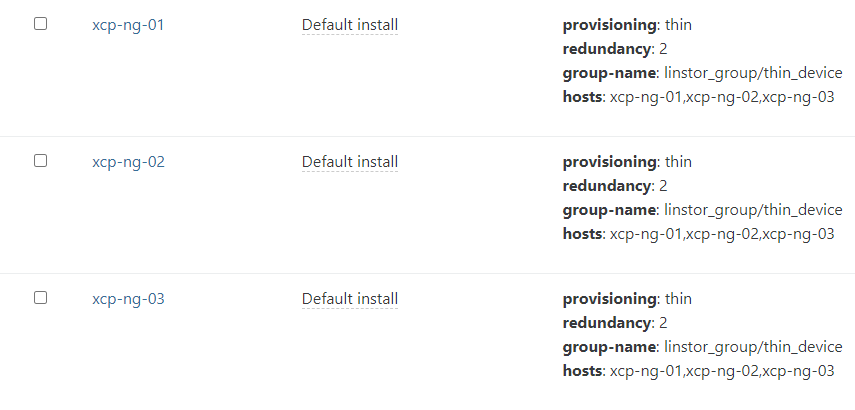
For now I have 3 hosts that are connected and working. I can install new VMs and start them on this SR.
The new host is already added to the pool (xcp-ng-04).
It's a little bit complex. So I think I will add a basic script to configure a new host or to remove an existing one. I do not recommend the usage of these commands, except in the case of tests.
Agree. This can help a bit.
-
@ronan-a
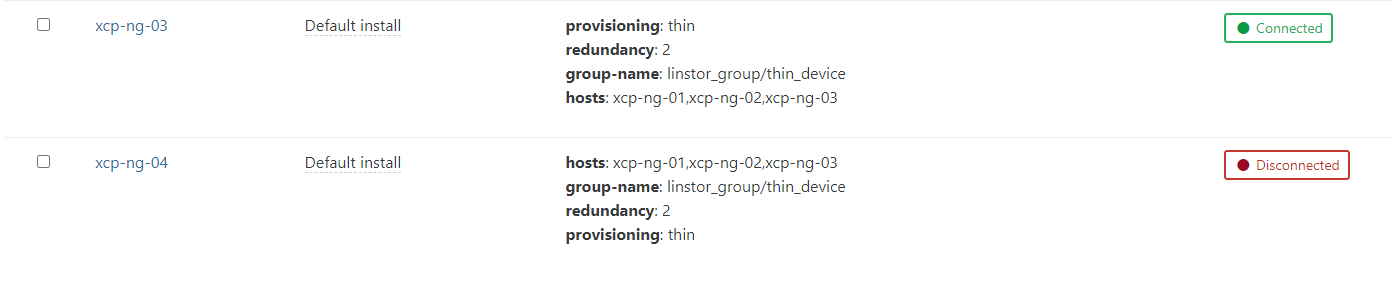
Another situation is that I cannot use the SR on all the host that are not part of the group (linstor_group/thin_device).for now I have my new xcp-ng-04 host joined to the pool, and I would like to connect the SR to it.
The first error I get is that the driver is not installed. So I installed all the package used on the install script (without the init disk section), and try to connect the SR to the xcp-ng-04. Now I get those error in the logfile.
[12:33 xcp-ng-01 ~]# tail -f /var/log/xensource.log | grep linstor Mar 2 12:34:10 xcp-ng-01 xapi: [debug||2306 HTTPS 192.168.2.94->:::80|host.call_plugin R:98517b08066b|audit] Host.call_plugin host = '8ac2930f-f826-4a18-8330-06153e3e4054 (xcp-ng-02)'; plugin = 'linstor-manager'; fn = 'hasControllerRunning' args = [ 'hidden' ] Mar 2 12:34:10 xcp-ng-01 xapi: [debug||2033 HTTPS 192.168.2.94->:::80|host.call_plugin R:e39e097fe8cb|audit] Host.call_plugin host = '81b06c7f-df55-4628-b27f-4e1e7850f900 (xcp-ng-03)'; plugin = 'linstor-manager'; fn = 'hasControllerRunning' args = [ 'hidden' ] Mar 2 12:34:11 xcp-ng-01 xapi: [debug||2306 HTTPS 192.168.2.94->:::80|host.call_plugin R:16602b9fb9d1|audit] Host.call_plugin host = '8ac2930f-f826-4a18-8330-06153e3e4054 (xcp-ng-02)'; plugin = 'linstor-manager'; fn = 'hasControllerRunning' args = [ 'hidden' ] Mar 2 12:34:11 xcp-ng-01 xapi: [debug||2033 HTTPS 192.168.2.94->:::80|host.call_plugin R:20c5d5ce11dc|audit] Host.call_plugin host = '81b06c7f-df55-4628-b27f-4e1e7850f900 (xcp-ng-03)'; plugin = 'linstor-manager'; fn = 'hasControllerRunning' args = [ 'hidden' ] ..... ..... Mar 2 12:34:43 xcp-ng-01 xapi: [error||6940 ||backtrace] Async.PBD.plug R:4bbaefcdb2cb failed with exception Server_error(SR_BACKEND_FAILURE_47, [ ; The SR is not available [opterr=Error: Unable to connect to any of the given controller hosts: ['linstor://xcp-ng-03']]; ]) Mar 2 12:34:43 xcp-ng-01 xapi: [error||6940 ||backtrace] Raised Server_error(SR_BACKEND_FAILURE_47, [ ; The SR is not available [opterr=Error: Unable to connect to any of the given controller hosts: ['linstor://xcp-ng-03']]; ])it's look like a controller need to be started on all the hosts to be able to "connect" the new host ?
Like I said, This is a new test to know if a xcp-ng that are not part of the VG can use this SR.
Hope my intention is clear...I just click on the disconnected button on UI
regards,
-
HI,
Do the vm HA is suppose to work if the VM is hosted on a SR with XOStore based ? I try to get it work, but the VM never restart if I shutdown the hosts where the VM is running.
Regards,
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login