Backup stuck at 27%
-
I have what I think is a fully patched 8.3 running on low end AMD hardware and XO from sources that was updated today:
Xen Orchestra, commit 72f3c
Master, commit 72f3cI updated because I had some problems yesterday getting a full back up to finish, errored with deleting the CBT snapshot. So today I wanted to try saving a delta and see how well that worked. I'm handling this manually so I can watch the process, I'll schedule after things really work reliably.
All VMs were created on an Intel host, after I got my mini lab set up I warm migrated over to the AMD and mostly things were smooth and everything has been working.
I created a new SMB share and set this as my remote, checking this is says the remote is connected and giving me 200+mbps writes and 800+mbps reads which is a little slow on the writes and a little optimistic on the reads, but not completely out of line.
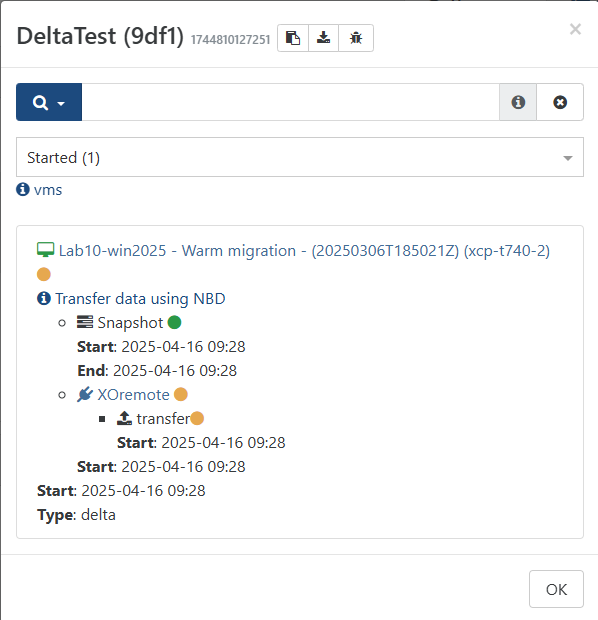
I've been stuck at this step since the first minute or two of the process:

I've since edited the job to not use NBD to see if that makes a difference, but can't cancel this job to try again.
I browsed to the share and checked, the first full backup is present (from yesterday), there is a lock file from today, there is no data written for today.
Not sure what else you need to help me figure out what has happened, but here are a couple more screen shots. 740-1 is dom0, XO is running on dom0, the VM that I'm trying to back up is on 740-2. A new snapshot was created this morning, it just isn't transferring, but I definitely still have access to the NAS and that specific share.
x520 10 gbps networking on all hosts, 64gb of ram on all hosts, 10gbase-t networking to the NAS, Truenas Scale 24.10.2. Processors are AMD v1756b which is 4c/8t and should be "good enough" for my little lab. VM being backed up is Windows Server 2025 running Xenserver tools 9.4. if it even errors out, I'll have to try Server 2022 and see if that works better.
If need be, I can burn this lab down and start everything from fresh (that's what a lab is for), but XCP-ng is only a few months old and was a fresh download at that time. XO has been running for a long time, and the NAS has been set up for a few months now, I don't think the NAS will be the problems unless there is a know issue with the version I have running. If I can get the task to end, I can shut everything down and update the NAS, I know I'm one patch behind right now.
-
@Greg_E restart pool toolstack and maybe XO itself.
if backup was interrupted it can stuck this way. -
Thanks, still a problem. I restarted the tool stack and got it to be "unstuck", but the system wouldn't migrate a VM from one host to another. So I shut down all the VMs, and shut down the hosts. After power up the VMs took a long time to go from yellow to green saying they were "starting", eventually everything came up, mostly. The Server 2025 had now lost the management agent (again), so I got tired of fooling with it and deleted the VM.
Then I built a new backup for a Server 2022 VM that seemed to be working fine, and ran it... Got to about 60% and failed. Restarted the job and it got stuck at 5% and was showing a VBD_force_unplug that would sit at zero, then go away (error out), then come back. I knew from a previous "successful" backup that this means it was going to fail and would hit my 3 hour time limit (didn't want to wait 24 hours this time).
Over all, something is broke and I don't know if it was the warm migration that got me here, or something else. The NAS seems to be working fine, files get created, lock file gets created, but this last time no image file was ever saved.
I think I'm going to burn it down and start fresh, right down to the OS install and see what's what.
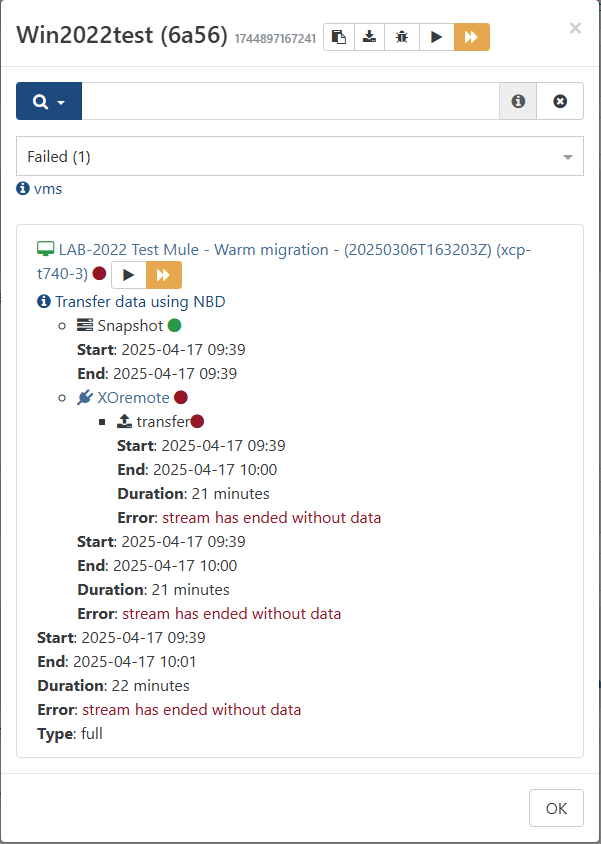

{ "data": { "mode": "delta", "reportWhen": "failure" }, "id": "1744897167241", "jobId": "e58a6a56-921a-41dd-b195-165b09023c8e", "jobName": "Win2022test", "message": "backup", "scheduleId": "d003e148-c436-42d5-8a8e-25dbd00154ce", "start": 1744897167241, "status": "failure", "infos": [ { "data": { "vms": [ "bcc13ee0-eefa-01c1-07ce-91af06db25d8" ] }, "message": "vms" } ], "tasks": [ { "data": { "type": "VM", "id": "bcc13ee0-eefa-01c1-07ce-91af06db25d8", "name_label": "LAB-2022 Test Mule - Warm migration - (20250306T163203Z)" }, "id": "1744897169111", "message": "backup VM", "start": 1744897169111, "status": "failure", "tasks": [ { "id": "1744897169132", "message": "clean-vm", "start": 1744897169132, "status": "success", "end": 1744897169142, "result": { "merge": false } }, { "id": "1744897169334", "message": "snapshot", "start": 1744897169334, "status": "success", "end": 1744897174214, "result": "1a8a2be6-f358-46a8-edaa-e1b8beeca77d" }, { "data": { "id": "b6edd4f2-4966-4237-bfb5-f3c1c7c2b66e", "isFull": true, "type": "remote" }, "id": "1744897174217", "message": "export", "start": 1744897174217, "status": "failure", "tasks": [ { "id": "1744897175621", "message": "transfer", "start": 1744897175621, "status": "failure", "end": 1744898432582, "result": { "message": "stream has ended without data", "name": "Error", "stack": "Error: stream has ended without data\n at readChunkStrict (/opt/xo/xo-builds/xen-orchestra-202504160916/@vates/read-chunk/index.js:80:11)\n at process.processTicksAndRejections (node:internal/process/task_queues:105:5)" } } ], "end": 1744898432583, "result": { "message": "stream has ended without data", "name": "Error", "stack": "Error: stream has ended without data\n at readChunkStrict (/opt/xo/xo-builds/xen-orchestra-202504160916/@vates/read-chunk/index.js:80:11)\n at process.processTicksAndRejections (node:internal/process/task_queues:105:5)" } } ], "infos": [ { "message": "Transfer data using NBD" } ], "end": 1744898501425, "result": { "message": "stream has ended without data", "name": "Error", "stack": "Error: stream has ended without data\n at readChunkStrict (/opt/xo/xo-builds/xen-orchestra-202504160916/@vates/read-chunk/index.js:80:11)\n at process.processTicksAndRejections (node:internal/process/task_queues:105:5)" } } ], "end": 1744898501426 } -
@Greg_E simple questions first. Do you have enough empty space on host and backup SR? basic recomendation x2 much than required.
-
Not an ideal situation, but everything is on shares on the same NAS (just a testing thing). Truenas has a 4TB pool, VMs are stored on an NFS share, remote is an SMB on a different vdev. The VM's I've been trying to back up are 60GB disk of which only about 25GB are used. I should have plenty of space. It shows 4% used in the Truenas control panel.
I'm creating a new VM to see if that changes anything (while I wait for another attempt to fail out). Everything on this pool was warm migrated, and I'm wondering if there is something to that process that is preventing things from working. Going to put up a basic Parrot Home OS (debian) and see what I can see.
I had a problem cold migrating one of the VMs off to a different pool (single host), had to make a copy and then reduce the CPU and RAM. Not sure what that was about, but I also reduced the CPU and RAM on the other VMs to see if that would help, answer is no.
-
@Greg_E
All VMs were created on an Intel host, after I got my mini lab set up I warm migrated over to the AMD
don't hear about limitation here, shouldn't be a problem. butAMD v1756bis pretty weak and not a server platform, so not sure. Some people have problems with some new ryzen CPUs. -
Nope, even a fresh VM is failing, but different error for the recent ones:
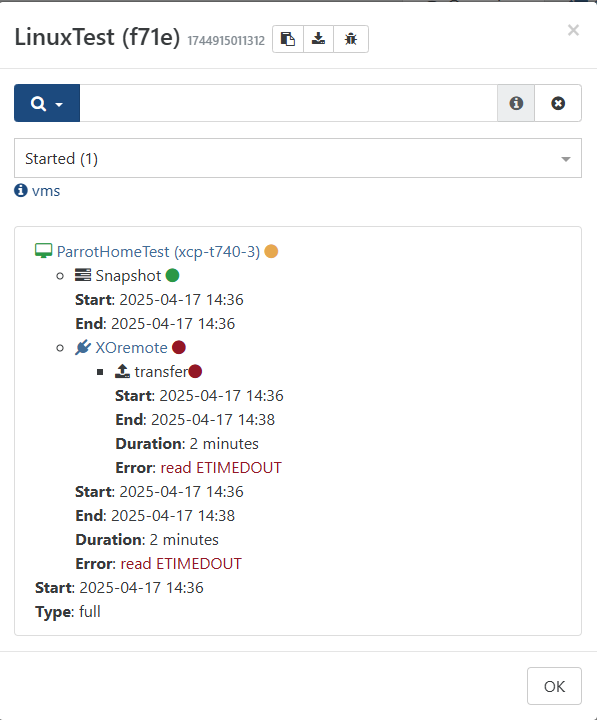
That's a storage issue of some kind, I'll have to figure it out. The funny thing is that obviously I have read and write to the NFS share, I just created a VM on it, and I see folders placed on the remote share, so it has write permissions (should have full control).
But I'm probably going to burn this down tomorrow and start fresh with a fresh NFS share and fresh remote share and see what happens. The only VM I cared about has been moved to a single host and is running (needs more ram on this host (have to order at least one more 64GB pair). Time to start downloading fresh installers and make sure I have all the drivers and MA ready.
-
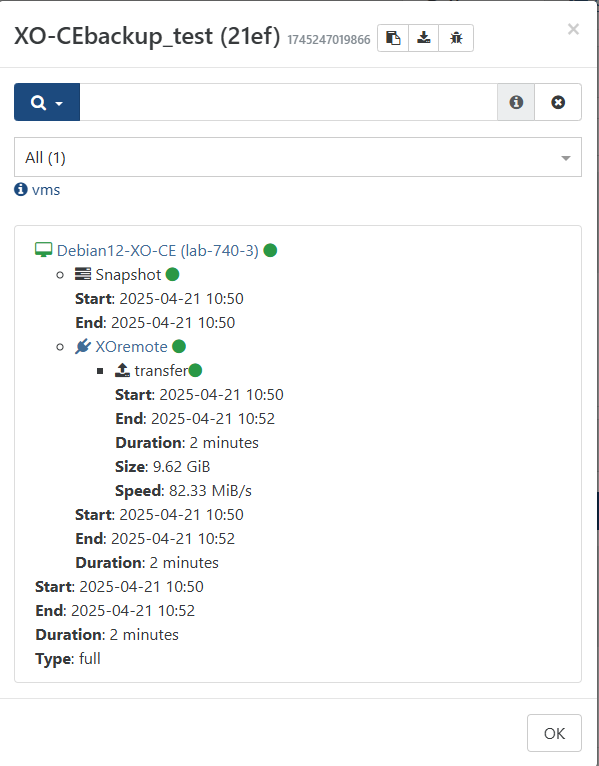
Not sure what or why, but fresh install of everything in my lab has allowed a successful "standard" backup, I'll get into the other flavors when I have a chance as I build the lab back out.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login