VDI Chain on Deltas
-
@nvoss Hello, The
UNDO LEAF-COEALESCEusually has a cause that is listed in the error above it. Could you share this part please?")
-
@dthenot when I grep looking for coalesce I don't see any errors. Everything is the undo message.
Looking at the line labeled 3680769 in this case corresponding with one of those undo's I see lock opens, variety of what looks like successful mounts and subsequent snapshot activity then at the end the undo. After the undo message I see something not super helpful.
Attached is that entire region. Below an excerpt.

It's definitely confusing as to why a force on the job works instead of the regular run?
-
@nvoss Could you try to run
vhd-util check -n /var/run/sr-mount/f23aacc2-d566-7dc6-c9b0-bc56c749e056/3a3e915f-c903-4434-a2f0-cfc89bbe96bf.vhd? -
@dthenot sure, here you go!
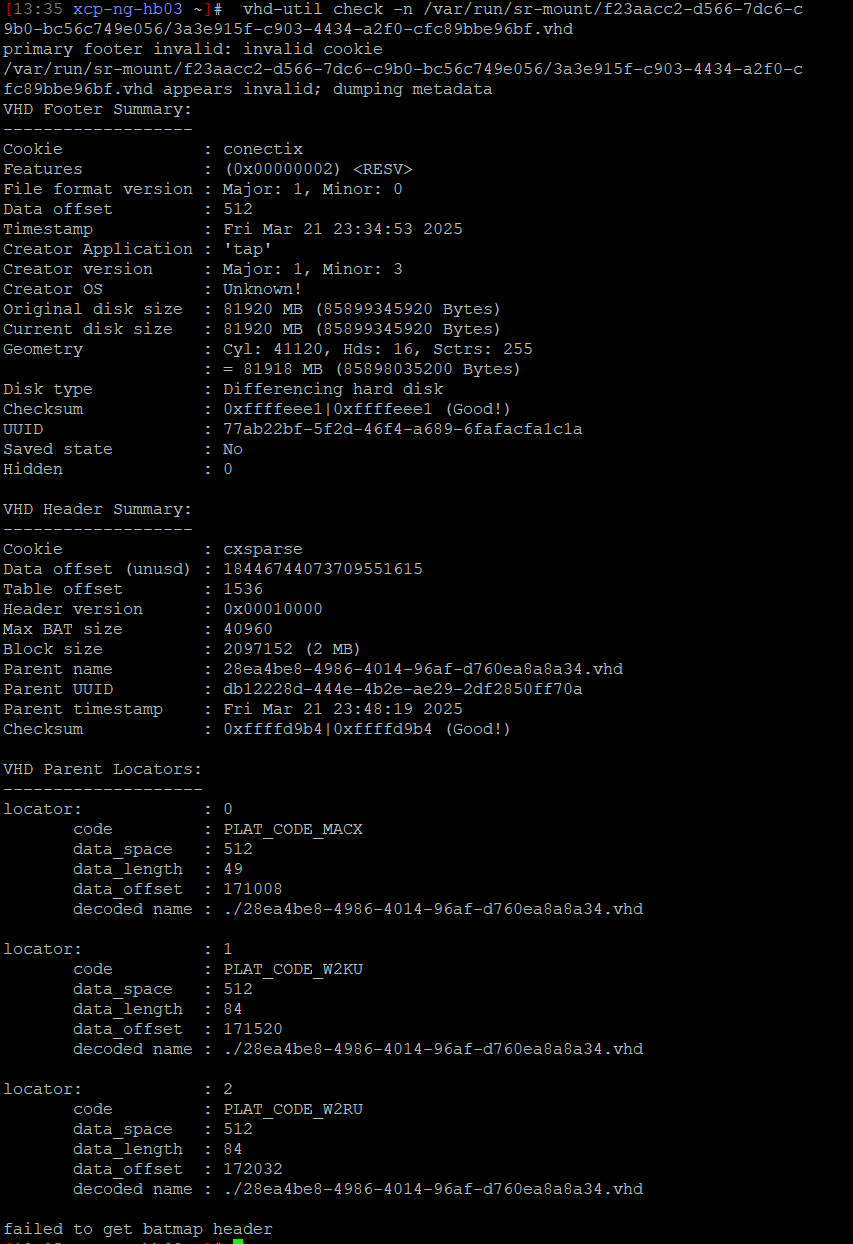
-
@nvoss The VHD is reported corrupted on the batmap. You can try to repair it with
vhd-util repairbut it'll likely not work.
I have seen people recover from this kind of error by doing a vdi-copy.
You could try a VM copy or a VDI copy and link the VDI to the VM again and see if it's alright.
The corrupted VDI is blocking the garbage collector so the chain are long and that's the error you see on XO side.
It might be needed to remove the chain by hand to resolve the issue. -
@dthenot every one of our VMs report this same error on a scheduled backup. Does that mean every one has this problem?
I'm not sure how it would've happened? It seems like the problem started after doing a rolling update to the 3 hosts about 2 months back.
I'm also not super clear on what the batmap is
-- just a shade out of my depth!Appreciate all the suggestions though. Happy to try stuff. Migrating the VD to local storage and back to the NAS, etc?
What would make the force restart work when the scheduled regular runs dont?
-
@nvoss No, the GC is blocked because only one VDI is corrupted, the one with the check.
All other VDI are on a long chain because they couldn't coalesce.
Sorry, BATMAP is the block allocation table, it's the info of the VHD to know which block exist locally.
Migrating the VDI might work indeed, I can't really be sure. -
@nvoss said in VDI Chain on Deltas:
What would make the force restart work when the scheduled regular runs dont?
I'm not sure what you mean.
The backup need to do a snapshot to have a point to compare before exporting data.
This snapshot will create a new level of VHD that would need to be coalesced, but it's limiting the number of VHD in the chain so it fails.
This is caused by the fact that the garbage collector can't run because it can't edit the corrupted VDI.
Since there is a corrupted VDI it's not running to not create more problem on the VDI chains.
Sometime corruption mean that we don't know if a VHD has any parent for example, and if doing so we can't know what the chain looks like meaning not knowing what VHD are in what chain in the SR (Storage Repository).VDI: Virtual Disk Image in this context
VHD being the format of VDI we use at the moment in XCP-ngAfter removing the corrupted VDI, maybe automatically by the migration process (maybe you'll have to do it by hand), you can run a
sr-scanon the SR and it launch the GC again. -
@dthenot sorry not sure how the "force restart" button option works for both our full and our delta backups vs the regular scheduled backup jobs because doing the force restart lets the job run fully each time regardless of the specific machine that may have the bad/corrupt disk? That's the orange button
And a manual snapshot works on all machines I believe too?
Is there a smooth way to track that VHD disk GUID back to its machine in the interface?
-
I was able to track down that particular UUID to the machine in question and we took it out of the backup routine. Unfortunately the issue persists and the backups continue to fail their regularly scheduled runs (in this case the delta).
There again though if we use the force restart command in the XO GUI on the backup job then it runs fine -- both full and delta are able to take snapshots, record backup data, and transmit said backup to both remotes.
I'm at a bit of a loss where to go next. My best guess is to try to migrate storage on all the VMs and migrate it back and see if that fixes it, but since removing the one VM didn't fix the issue I'm afraid it may be all of them that are impacting the backup job.
-
@dthenot the plot thickens!
If we try to migrate storage on one of these machines we get SR_BACKEND_FAILURE_109 with snapshot chain being too long. So coalescing is definitely not working right.
Do we have decent options to clean it up? The machines themselves are working fine. Manual snapshots are fine, but even force run of the backup job results in these failures too.
"result": { "code": "SR_BACKEND_FAILURE_109", "params": [ "", "The snapshot chain is too long", "" ], "task": { "uuid": "71dd7f49-e92c-6e46-8f4c-07bdd39a4795", "name_label": "Async.VDI.pool_migrate", "name_description": "", "allowed_operations": [], "current_operations": {}, "created": "20250612T15:27:02Z", "finished": "20250612T15:27:14Z", "status": "failure", "resident_on": "OpaqueRef:c1462347-d4ae-5392-bd01-3a5c165ed80c", "progress": 1, "type": "<none/>", "result": "", "error_info": [ "SR_BACKEND_FAILURE_109", "", "The snapshot chain is too long", "" ], -
Without answering for the root cause of the issue, one option is to migrate while the VM is off (IIRC, it won't use a snapshot but I'm not 100% sure). Another solution is to do a VM (or VDI) copy to the destination storage while the VM is off.
-
@olivierlambert Unfortunately even when shutdown the migration from NAS to local storage fails with the same SR_BACKEND_FAILURE_109 error.
At this point we're trying copying the VHD, destroy the VM, re-create with the copied VHD on at least one machine.
But it definitely appears to be more than one VM with the problem, unless the one machine causing the problem is preventing coalescing on all the other machines too somehow. The previously identified machine is the one I'm starting with.
-
We went the route of copying all the VMs, deleting the old, starting up the new versions. Snapshots all working after machines created.
This weekend my fulls ran and 4 of the machines continue to have VDI chain issues. The other 4 back up correctly now.
Any other thoughts we might pursue? The machines still failing don't seem to have any consistency about them. Windows 2022, 11, and linux in the mix. All 3 of my hosts are in play. 2 are on 1 and the other 2 machines are split amongst the other two hosts. All hosts are fully up-to-date patch-wise as is XO.
The machines DO backup right now if we choose force restart button in the XO interface for backups. For now. That worked before for a few months then also stopped working. When we do the force restart it does create a snapshot at that time. During the failed scheduled backup the snapshot is not created.
Somehow despite these being brand new copied VMs I see the same things in the SMlog file (attached is a segment of that file where at least 3 of those undo coalesce errors show) where it looks like an undo leaf-coalesce but no other real specifics.
Anything else we can troubleshoot with?
Thanks,
Nick -
Sorry I don't see any error, it's just a message from the GC. However, I have to admit I don't have time to take a deeper look myself.
If you have support, might be the right time to open a ticket, alternatively someone will take a look when they can
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login