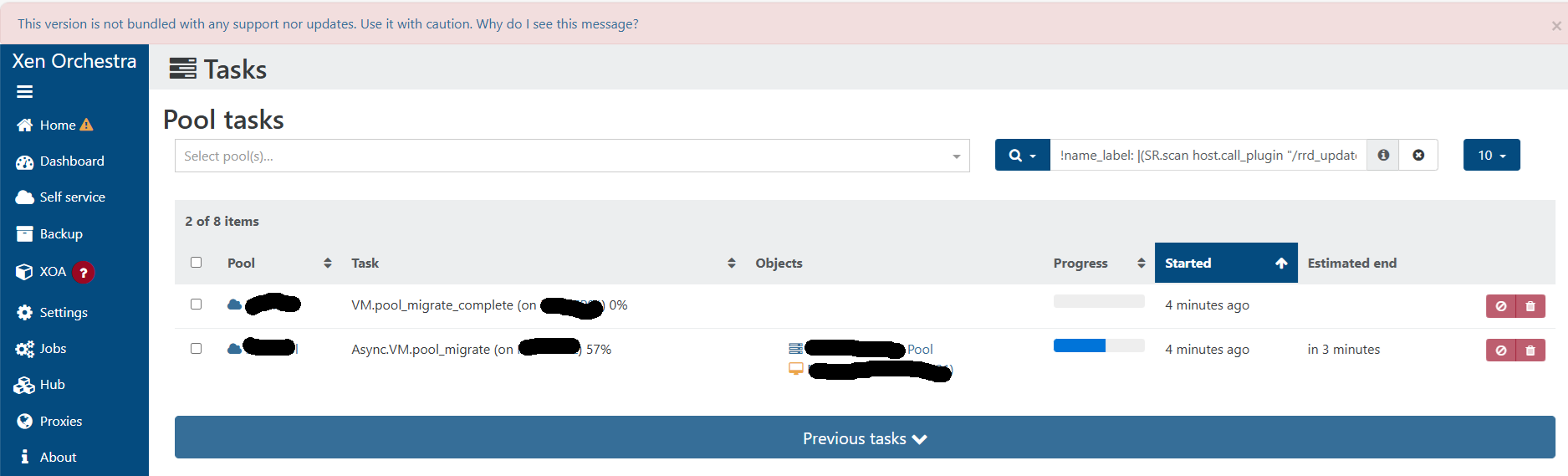
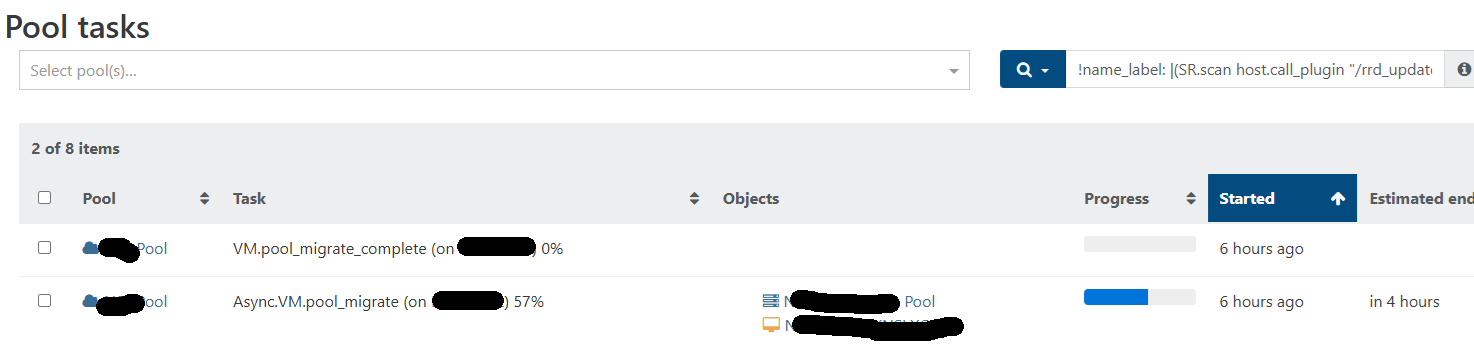
Async.VM.pool_migrate stuck at 57%
-
Hi,
I'm having issue with live migration between xcp-ng host in a pool. The migration looks ok. The VM migrated to Host #1 from Host #2, but the task stuck at 57% (Async.VM.pool_migrate stuck at 57%). I have to restart the toolstack to make the tasks go away. Any idea?
I'm using XO from source and on the latest commit.
Thank you.
Best regards,
Azren -
W wmazren marked this topic as a question on
-
Hi,
It's likely not an XO problem, but an issue with XCP-ng.
- Check your OS is having static RAM settings and enough RAM
- Do you have tools installed in your OS?
- Time sync between the hosts?
-
-
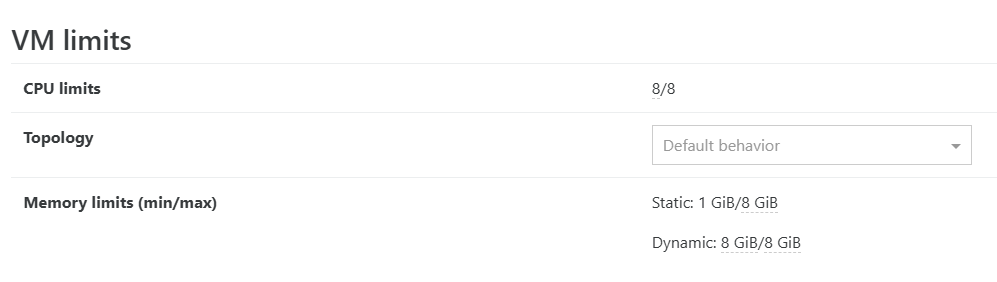
Check your OS is having static RAM settings and enough RAM
Yes
-
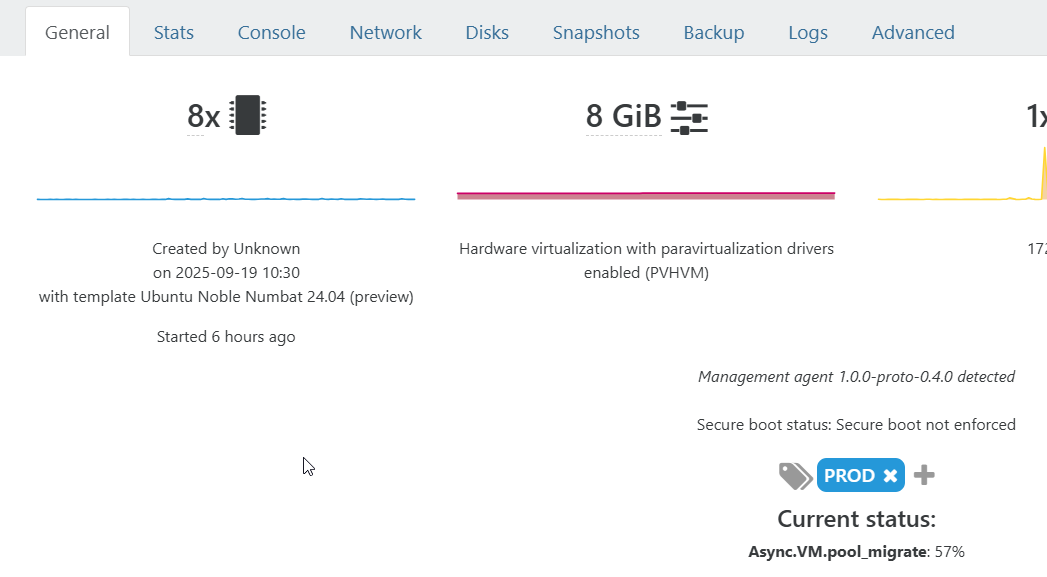
Do you have tools installed in your OS?
Yes
-
Time sync between the hosts?
Yes
Anything else I can check?
Best regards,
Azren -
-
Do you have the issue with all guests or just this VM?
-
@wmazren I had a similar issue which costed my many hours to troubleshoot.
I'd advise you to check "dmesg" output within the VM that is not able to get live migrated.
XCP-ng / Xen behaves different than VMWare regarding live migration.
XCP-ng will interact with the linux kernel upon live migration and the kernel will try to freeze all processes before performing the live migration.
In my case a "fuse" process blocked the graceful freezing of all processes and my live migration task also stuck in task view similar to your case.
After solving the fuse process issue and therefore making the system able to live migrate the issue was gone.
All of this can be viewed in dmesg as the kernel will tell you about what is being done during live migration via XCP-ng.
//EDIT: another thing you might want to try is toggling "migration compression" in pool settings as well as making sure you have a dedicated connection / VLAN configured for the live migration. Those 2 things also helped my live migrations being faster and more robust.
-
I also went troubleshooting and found the same as @MajorP93. Specifically I saw this in the kernel logs (viewable either in
dmesgor usingjournalctl -k) :Freezing of tasks failed after 20.005 seconds (1 task refusing to freeze, wq_busy=1)Quoting askubuntu.com:
Before going into suspend (or hibernate for that matter), user space processes and (some) kernel threads get frozen. If the freezing fails, it will either be due to a user space process or a kernel thread failing to freeze.
To freeze a user space process, the kernel sends it a signal that is handled automatically and, once received, cannot be ignored. If, however, the process is in the uninterruptible sleep state (e.g. waiting for I/O that cannot complete due to the device being unavailable), it will not receive the signal straight away. If this delay lasts longer than 20s (=default freeze timeout, see
/sys/power/pm_freeze_timeout(in miliseconds)), the freezing will fail.NFS, CIFS and FUSE amongst others have been historically known for causing issues like that.
Also from that post:
You can grep the problematic task like this
# dmesg |grep "task.*pid"In my case it was prometheus docker containers.
-
-
I would check XCP-ng logs to watch what's going on regarding the migration, also making sure you are fully up to date on your 8.3.
What kind of hardware do you have?
-
My dmesg...
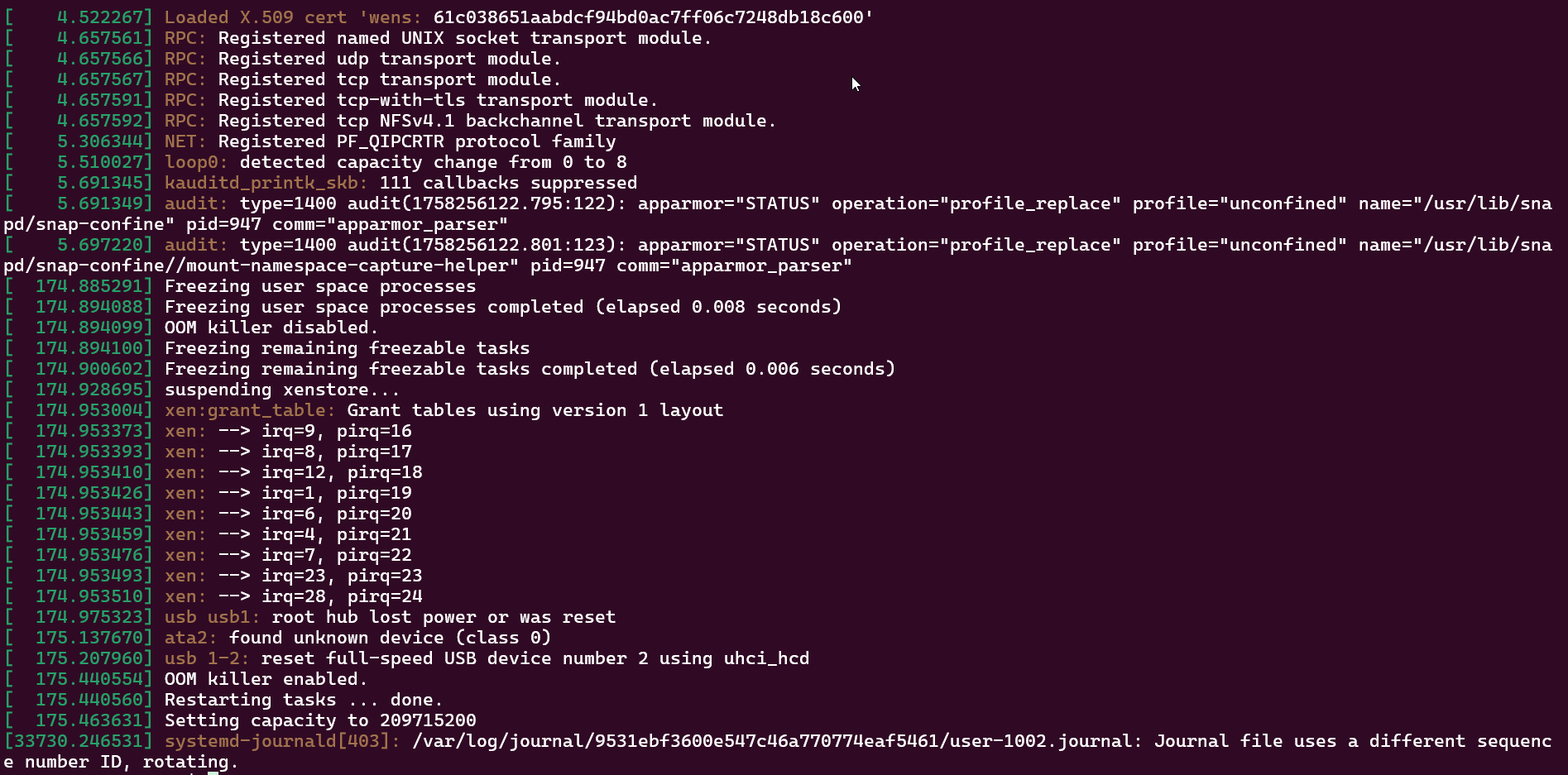
This is the XO VM that I try to migrate, but issue also happen to other VMs running MS WIndows.
Best regards,
Azren -
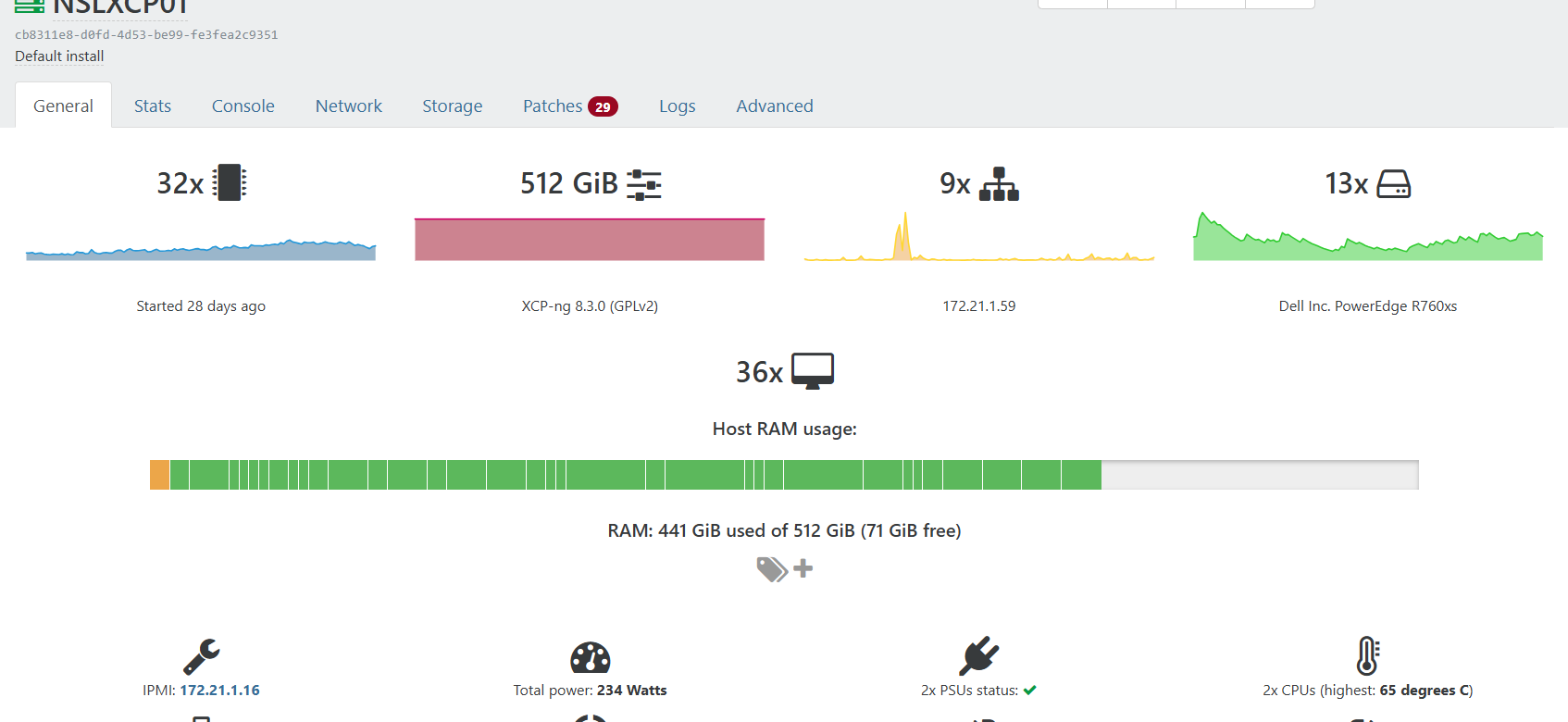
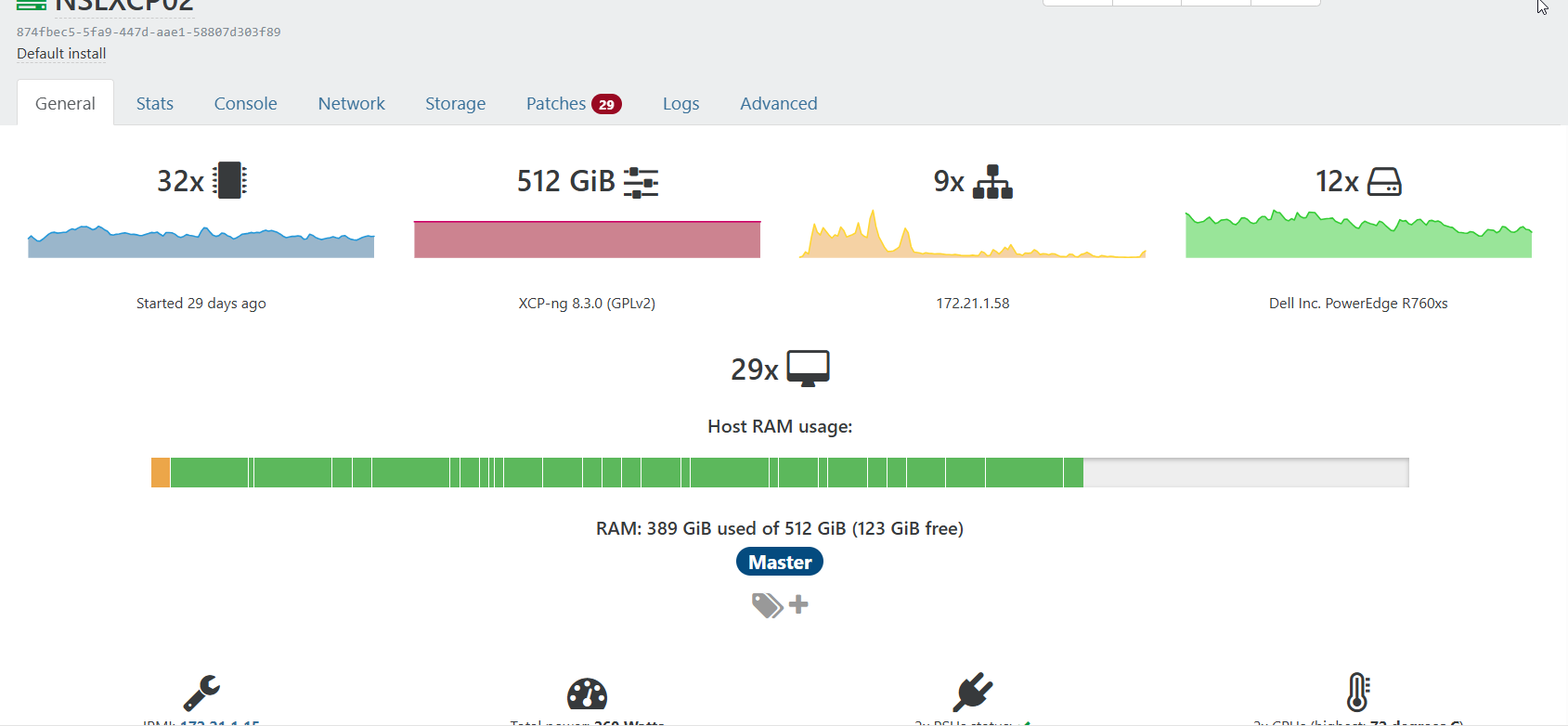
Both hosts are Dell PowerEdge R760 dual processor with 512GB of memory. Missing this month patches. I'm trying to live migrate VMs to 1 host so that I can start installing patches and reboot.
Host#1
Host#2
Host#1: dmesg
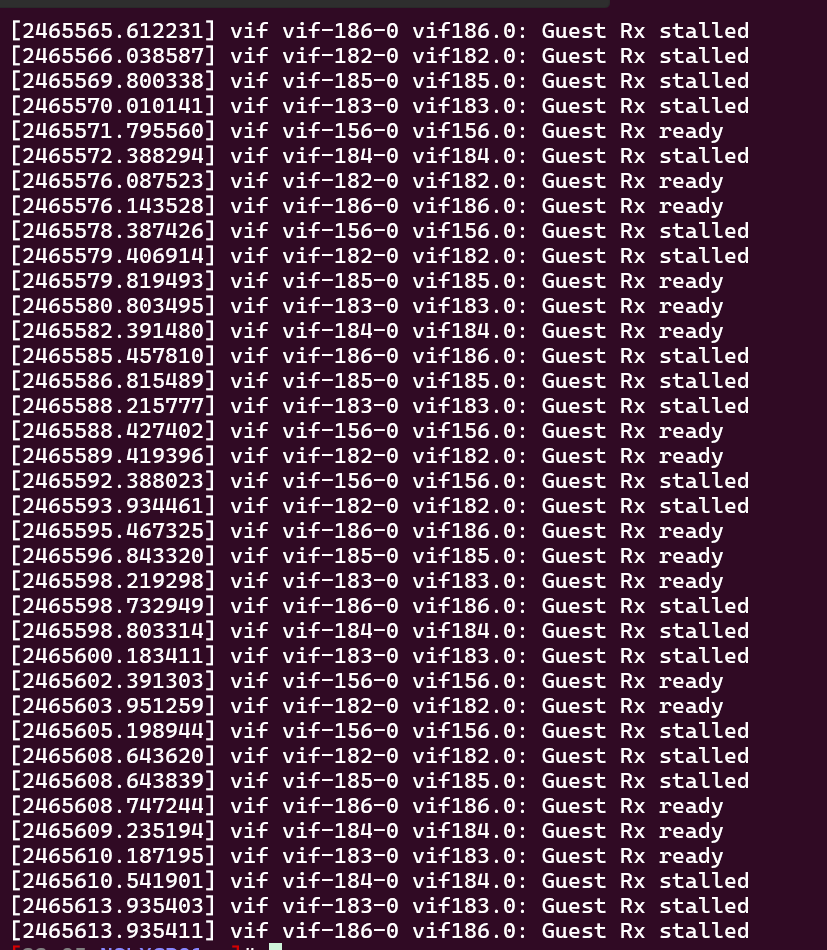
Host#2: dmesg
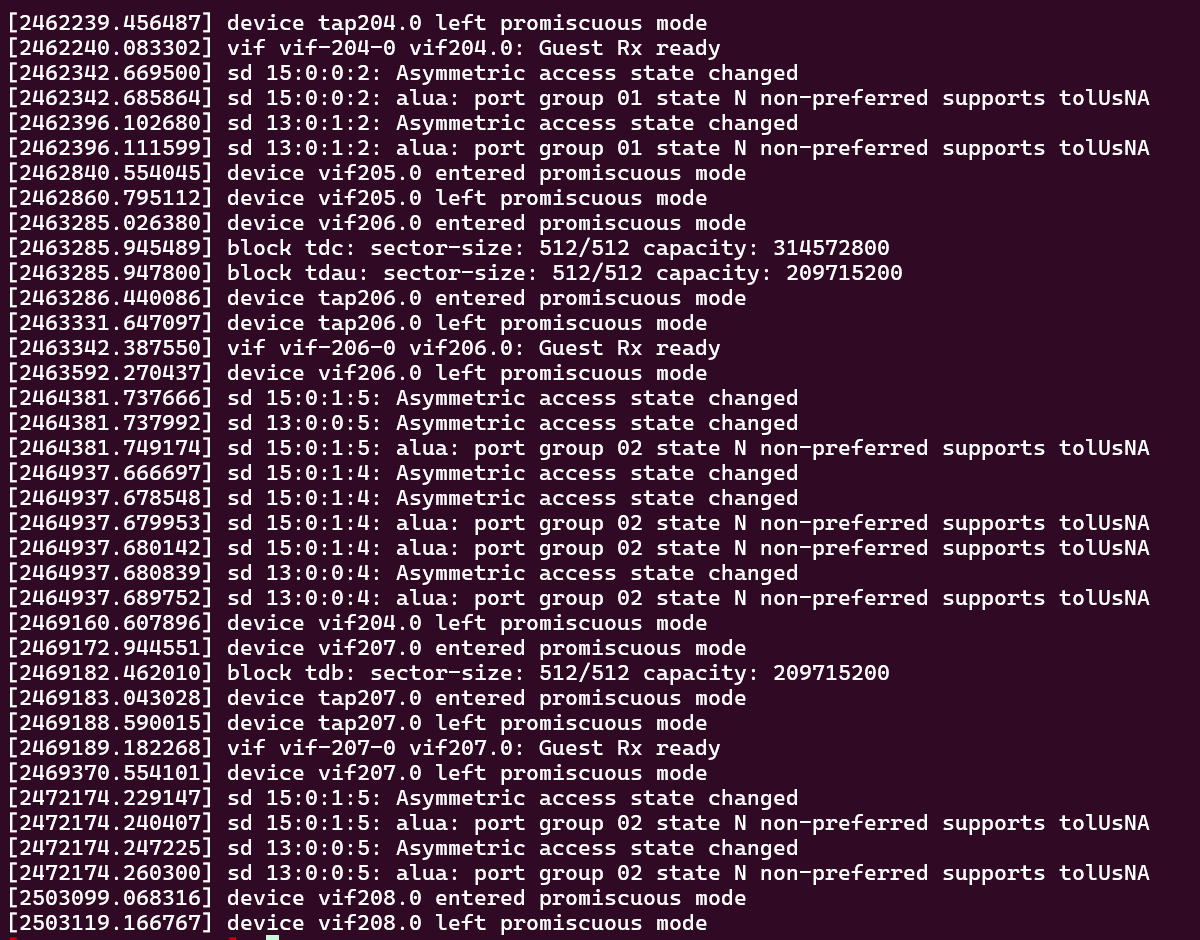
-
It appears that the issue is related to Host #1. Any migration into or out of Host #1 tends to cause problems. Occasionally, virtual machines (VMs) lose network connectivity during migration and become unresponsive — they cannot be shut down, powered off (even forcefully), or restarted, often getting stuck in the process.
I’ve added Host #3 to the pool. Migration between Host #2 and Host #3 works smoothly in both directions.
Any idea how can I kill the stuck VM?
xe vm-reset-powerstate force=true vm=MYVM03 This operation cannot be completed because the server is still live. host: cb8311e8-d0fd-4d53-be99-fe3fea2c9351 (HOST01)Best regards,
Azren -
Is it the pool master?
-
-
Then reboot than broken host and in the meantime, re-issue the power reset command from the master.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login