Delta backup fails for specific vm with VDI chain error
-
GC is an architectural problem in XenServer | CH. I've been fighting about this with Citrix for a long time and I never see this problem being in fact solved or a documentation of a troubleshooting that really works.
For Enterprise Support | Premium, the procedure to be executed is always the FULL COPY of the VM, which is unfeasible in most cases for a problem that is so recurring.
In CH8 (updated) I have the same problems and I started to have problem in other Pools 7.1 CU2 after installing XS71ECU2009. Until then the process came "stable for a while ", after installing I went back to having problems and unfortunately reinstalling and doing a rollback is not feasible... We opted to upgrade to CH8, but the problem remained...
-
Yeah that's why we are focusing on SMAPIv3 instead of trying to "fix" something that's probably flawed by design on SR with slow speed (in general, it works relatively well on SSDs)
-
@olivierlambert said in Delta backup fails for specific vm with VDI chain error:
SMAPIv3
But @olivierlambert, in other posts, even with a FULL SSD disk (SC5020F) we have failed the coalesce process ... when you talk about SMAPIv3 is this something to be implemented exclusively in XCP or will it be inherited from CH 8.x?
-
@_danielgurgel if you have failed coalesce even on SSD, you should have something that cause the issue. Majority of users don't have this problem, so I suppose the thing is to find what could cause it.
SMAPIv3 is done by Citrix, but we are doing stuff on our side (upstream as possible, harder since Citrix closed some sources). As soon we have something that people could test, we'll push it into testing
")
-
@olivierlambert said in Delta backup fails for specific vm with VDI chain error:
Thanks! So here is the logic: leaf coalesce will (or should
 ) merge a
) merge a base copyand its child ONLY if thisbase copyget only one child.Also, here is a good read: https://support.citrix.com/article/CTX201296
You can check if your SR got leaf coalesce enabled, there's no reason to not have it, but still a check to do.
With "only one child" you mean no nested child (aka grandchild)?
As I understand leaf-coalesce can be turned off explicitly and otherwise is on implicitely. It wasn't turned off.
Only thing I could do (I guess) was turn it on explicitely - just to make sure.[15:31 rigel ~]# xe sr-param-get uuid=f951f048-dfcb-8bab-8339-463e9c9b708c param-name=other-config param-key=leaf-coalesce trueNothing has changed so far, so I guess I should go on and see what happens this time if I migrate the vm to the other host?
-
Okay so it wasn't disabled, as it should.
To trigger a coalesce, you need to delete a snapshot. So it's trivial to test: create a snapshot, then remove it. Then you'll see a VDI that must be coalesce in Xen Orchestra.
To answer the question: doesn't matter if the child got child too. As long there is only one direct child, it means coalesce should be triggered.
-
That doesn't seem to have an effect in the behaviour other then a bunch of new messages in the log.
I'll check in a couple of hours. If the behaviour persists I'll migrate the vm and we'll see how it behaves on the other host.
-
Create a snap, display the chain with
xapi-explore-sr. Then remove the snap, and check again. Something should have changed -
It changed from
rigel: sr (30 VDIs) ├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ ├── customer server 2017 0 - dcdef81b-ec1a-481f-9c66-ea8a9f46b0c8 - 0.01 Gi │ └─┬ base copy - 775aa9af-f731-45e0-a649-045ab1983935 - 318.47 Gi │ └─┬ customer server 2017 0 - d7204256-488d-4283-a991-8a59466e4f62 - 24.54 Gi │ └─┬ base copy - 1578f775-4f53-4de4-a775-d94f04fbf701 - 0.05 Gi │ ├── customer server 2017 0 - 8bcae3c3-15af-4c66-ad49-d76d516e211c - 0.01 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 Gito
rigel: sr (29 VDIs) ├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ ├── customer server 2017 0 - dcdef81b-ec1a-481f-9c66-ea8a9f46b0c8 - 0.01 Gi │ └─┬ base copy - 775aa9af-f731-45e0-a649-045ab1983935 - 318.47 Gi │ └─┬ customer server 2017 0 - d7204256-488d-4283-a991-8a59466e4f62 - 24.54 Gi │ └─┬ base copy - 1578f775-4f53-4de4-a775-d94f04fbf701 - 0.05 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 Gi -
Can you use
--fullbecause we can't have colors in copy/paste from your terminal -
A moment later it changed to
rigel: sr (28 VDIs) ├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ ├── customer server 2017 0 - dcdef81b-ec1a-481f-9c66-ea8a9f46b0c8 - 0.01 Gi │ └─┬ base copy - 775aa9af-f731-45e0-a649-045ab1983935 - 318.47 Gi │ └─┬ base copy - 1578f775-4f53-4de4-a775-d94f04fbf701 - 0.05 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 GiUnfortunately I cannot do a --full, as it gives me an error:
✖ Maximum call stack size exceeded RangeError: Maximum call stack size exceeded at assign (/usr/lib/node_modules/xapi-explore-sr/node_modules/human-format/index.js:21:19) at humanFormat (/usr/lib/node_modules/xapi-explore-sr/node_modules/human-format/index.js:221:12) at formatSize (/usr/lib/node_modules/xapi-explore-sr/dist/index.js:66:36) at makeVdiNode (/usr/lib/node_modules/xapi-explore-sr/dist/index.js:230:60) at /usr/lib/node_modules/xapi-explore-sr/dist/index.js:241:26 at /usr/lib/node_modules/xapi-explore-sr/dist/index.js:101:27 at arrayEach (/usr/lib/node_modules/xapi-explore-sr/node_modules/lodash/_arrayEach.js:15:9) at forEach (/usr/lib/node_modules/xapi-explore-sr/node_modules/lodash/forEach.js:38:10) at mapFilter (/usr/lib/node_modules/xapi-explore-sr/dist/index.js:100:25) at makeVdiNode (/usr/lib/node_modules/xapi-explore-sr/dist/index.js:238:15) -
Hmm strange. Can you try to remove all snapshots on this VM?
-
Sure. Did it.
The depth in the sr's advanced tab now displays a depth of 3.
rigel: sr (27 VDIs) ├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ └─┬ base copy - 775aa9af-f731-45e0-a649-045ab1983935 - 318.47 Gi │ └─┬ customer server 2017 0 - 1d1efc9f-46e3-4b0d-b66c-163d1f262abb - 0.15 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 GiThis is something new.. we may be on to something:
Aug 27 16:23:39 rigel SMGC: [11997] Num combined blocks = 255983 Aug 27 16:23:39 rigel SMGC: [11997] Coalesced size = 500.949G Aug 27 16:23:39 rigel SMGC: [11997] Coalesce candidate: *775aa9af[VHD](500.000G//319.473G|ao) (tree height 3) Aug 27 16:23:39 rigel SMGC: [11997] Coalescing *775aa9af[VHD](500.000G//319.473G|ao) -> *43454904[VHD](500.000G//500.949G|ao)And after a while:
Aug 27 16:26:26 rigel SMGC: [11997] Removed vhd-blocks from *775aa9af[VHD](500.000G//319.473G|ao) Aug 27 16:26:27 rigel SMGC: [11997] Set vhd-blocks = (omitted output) for *775aa9af[VHD](500.000G//319.473G|ao) Aug 27 16:26:27 rigel SMGC: [11997] Set vhd-blocks = eJztzrENgDAAA8H9p/JooaAiVSQkTOCuc+Uf45RxdXc/bf6f99ulHVCWdsDHpR0ALEs7AF4s7QAAgJvSDoCNpR0AAAAAAAAAAAAAALCptAMAYEHaAQAAAAAA/FLaAQAAAAAAALCBA/4EhgU= for *43454904[VHD](500.000G//500.949G|ao) Aug 27 16:26:27 rigel SMGC: [11997] Num combined blocks = 255983 Aug 27 16:26:27 rigel SMGC: [11997] Coalesced size = 500.949GDepth is now down to 2 again.
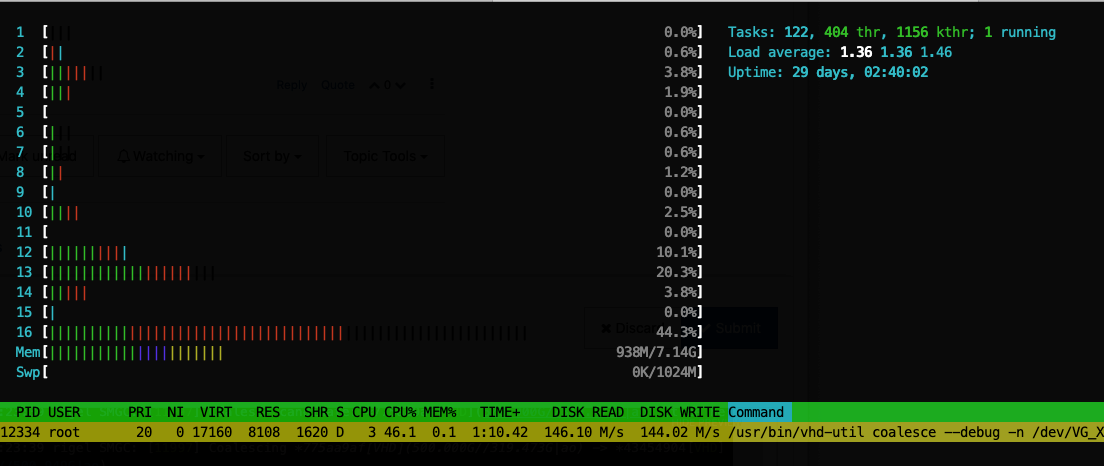
xapi-explore --full now works, but looks the same to me:rigel: sr (26 VDIs) ├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ └─┬ base copy - 775aa9af-f731-45e0-a649-045ab1983935 - 318.47 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 GiIt's busy coalescing. We'll see how that ends.
-
Yeah, 140MiB/s for coalesce is really not bad
Let's see! -
Hm...
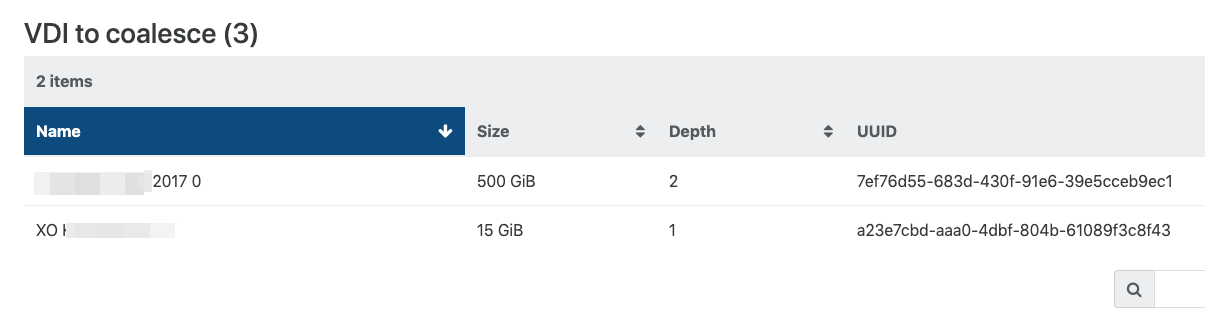
rigel: sr (26 VDIs) ├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ └─┬ customer server 2017 0 - 8e779c46-6692-4ed2-a83d-7d8b9833704c - 0.19 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 Gi -
Yes, it's logical:
7ef76is the active disk, and it should be merged in8e77, then this last one should be merged in4345 -
But that never seems to happen. It's always just merging the little VHD in the middle:
Aug 28 10:00:22 rigel SMGC: [11997] SR f951 ('rigel: sr') (26 VDIs in 9 VHD trees): showing only VHD trees that changed: Aug 28 10:00:22 rigel SMGC: [11997] *43454904[VHD](500.000G//500.949G|ao) Aug 28 10:00:22 rigel SMGC: [11997] *3378a834[VHD](500.000G//1.520G|ao) Aug 28 10:00:22 rigel SMGC: [11997] 7ef76d55[VHD](500.000G//500.984G|ao) Aug 28 10:00:22 rigel SMGC: [11997] Aug 28 10:00:22 rigel SMGC: [11997] Coalescing parent *3378a834[VHD](500.000G//1.520G|ao)├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ └─┬ customer server 2017 0 - 3378a834-77d3-48e7-8532-ec107add3315 - 1.52 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 GiRight before this timestamp and probably just by chance I got this:
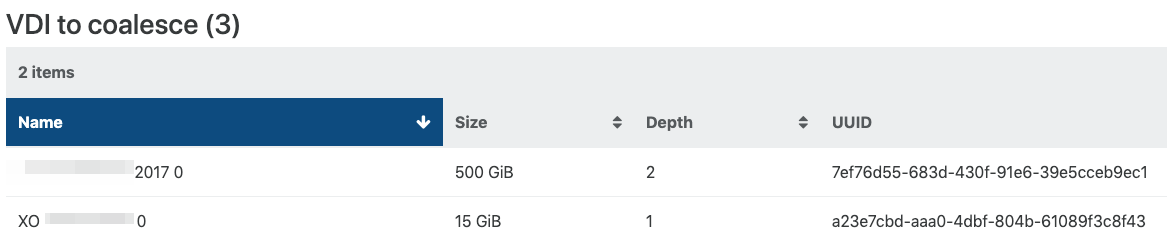
├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 GiBut still....
-
That's strange. The child is bigger than the parent. I wonder how it's possible but I forgot how the size is computed on LVM (I'm mainly using file backend).
You could try to do a
vhd-util repairon those disks. See https://support.citrix.com/article/CTX217757 -
The bigger number is equal to the configured virtual disk size.
The repair seems to work only if a disk is not in use - eq offline:
[10:24 rigel ~]# lvchange -ay /dev/mapper/VG_XenStorage--f951f048--dfcb--8bab--8339--463e9c9b708c-VHD--7ef76d55--683d--430f--91e6--39e5cceb9ec1 [10:26 rigel ~]# vhd-util repair -n /dev/mapper/VG_XenStorage--f951f048--dfcb--8bab--8339--463e9c9b708c-VHD--7ef76d55--683d--430f--91e6--39e5cceb9ec1 [10:27 rigel ~]# lvchange -an /dev/mapper/VG_XenStorage--f951f048--dfcb--8bab--8339--463e9c9b708c-VHD--7ef76d55--683d--430f--91e6--39e5cceb9ec1 Logical volume VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/VHD-7ef76d55-683d-430f-91e6-39e5cceb9ec1 in use. -
Have you tried:
- repair on both UUIDs in the chain?
- trying again when it's halted
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login