Alert: Control Domain Memory Usage
-
Hi, i have some strange reccuring memory usage problems after upgrading to XCP-NG 8.0.
Sometimes, after about a month of uptime, the control domain memory usage on some hosts grows until its full. But there is no visible process eating up the RAM.
When i don`t reboot the Server, I can see those errors beeing reported for a week or so, before something crashes on the Host. Mostly its ovs-vswitchd, which breaks network connectivity, of course.
This happens to several servers in several pools which were running for months or even years with Xenserver versions from 7.0 upwards. It even happened on servers which were running XCP-NG 7.4 for hundreds of days without problems.
This server is in maintanance mode now. Here is the output of top, sorted by %MEM:
top - 17:42:23 up 49 days, 13:38, 1 user, load average: 1.07, 1.14, 1.33 Tasks: 345 total, 1 running, 198 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.7 us, 0.2 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.1 st KiB Mem : 7498176 total, 96436 free, 7149172 used, 252568 buff/cache KiB Swap: 1048572 total, 895996 free, 152576 used. 126440 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2010 root 10 -10 1302552 155772 9756 S 1.0 2.1 1043:23 ovs-vswitchd 2651 root 20 0 589132 28908 4540 S 11.3 0.4 227:39.22 xapi 1525 root 20 0 288660 25012 1564 S 0.0 0.3 655:22.71 xcp-rrdd 2663 root 20 0 214868 16268 6432 S 0.0 0.2 48:49.51 python 2650 root 20 0 496804 15624 5912 S 0.0 0.2 162:33.50 xenopsd-xc 1179 root 20 0 158980 15392 6876 S 0.0 0.2 21:29.70 message-switch 1601 root 20 0 62480 10408 3848 S 0.0 0.1 118:33.49 xcp-rrdd-xenpm 1597 root 20 0 119764 10292 3660 S 0.0 0.1 270:19.65 xcp-rrdd-iostat 1516 root 20 0 76588 9796 3248 S 0.0 0.1 159:55.67 oxenstored...
See free -m:[17:54 xs03 ~]# free -m total used free shared buff/cache available Mem: 7322 6992 83 0 247 114 Swap: 1023 148 875and:
[17:54 xs03 ~]# cat /proc/meminfo MemTotal: 7498176 kB MemFree: 85376 kB MemAvailable: 117788 kB Buffers: 12300 kB Cached: 97024 kB SwapCached: 23740 kB Active: 131240 kB Inactive: 118996 kB Active(anon): 79400 kB Inactive(anon): 75292 kB Active(file): 51840 kB Inactive(file): 43704 kB Unevictable: 168644 kB Mlocked: 168644 kB SwapTotal: 1048572 kB SwapFree: 897276 kB Dirty: 24 kB Writeback: 0 kB AnonPages: 305640 kB Mapped: 56028 kB Shmem: 376 kB Slab: 144436 kB SReclaimable: 38100 kB SUnreclaim: 106336 kB KernelStack: 11520 kB PageTables: 14236 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 4797660 kB Committed_AS: 3936576 kB VmallocTotal: 34359738367 kB VmallocUsed: 0 kB VmallocChunk: 0 kB Percpu: 12160 kB HardwareCorrupted: 0 kB CmaTotal: 0 kB CmaFree: 0 kB DirectMap4k: 7897600 kB DirectMap2M: 0 kBHow can i find out what is using the RAM?
-
Announcement
Here's an updated
ixgbedriver package that is meant as an update candidate without updating to a higher version. If need all feedback we can get on this one, because this is the candidate for the official fix as would be delivered to everyone. Of course theintel-igb-altwill remain available for those who need a more recent driver, and I even moved it to theupdatesrepository so that one doesn't need to add--enablerepo=xcp-ng-testingto install it anymore.To test the official update candidate on XCP-ng 8.1 or 8.2.
- If you had previously installed
intel-ixgbe-alt:yum remove intel-ixgbe-alt -y- Check that the
/lib/modules/4.19.0+1/override/ixgbe.kofile was properly deleted. I've seen, once, a situation where a .ko file from an-altpackage wasn't deleted, so I'm being cautious here and ask you to report you see that it is still present. In theory, this is impossible, but as I've seen it once I don't know anymore")
- Run
depmod -a
- Update the
intel-ixgbepackage from the testing repo:yum update intel-ixgbe --enablerepo=xcp-ng-testing - Reboot
Note: I'm not 100% sure that I picked the right patch, nor that this patch alone is sufficient.
- If you had previously installed
-
htopwill be better to spot things You can alternatively use Netdata -
@olivierlambert said in Alert: Control Domain Memory Usage:
Netdata
Hello Oliver,
thanks for your quick Response.Yes, htop is much prettier, but it doen`t see more the top, at least in this case:
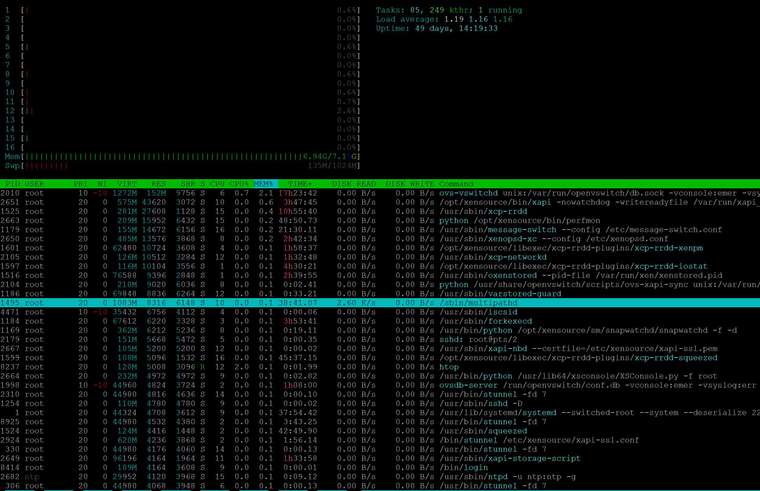
I think, Netdata will also just see those things?
-
- Can you restart the toolstack and see if it changes memory footprint?
- Anything suspicious in
dmesg?
-
- toolstack restart didn`t change much
- good idea: Indeed there are some entries in dmesg:
[4286099.036105] Status code returned 0xc000006d STATUS_LOGON_FAILURE [4286099.036116] CIFS VFS: Send error in SessSetup = -13With "mount" i can see two old cifs iso libaries, which have allready been detached from the pool.
I was able to unmount one of them.
The other one is busy:
umount: /run/sr-mount/43310179-cf17-1942-7845-59bf55cb3550: target is busy.I will have a look into it a little later and report.
Thanks.
-
I was not able to find what was keeping the target busy.
I did a lazy unmount "umount -l", since then i have no new dmesg lines, but the memory isn`t freed.
So i`m not sure, if this is/was the reason for the Problem. Other Servers in the pool have this same old mount, but do not use this much of RAM. But i will check cifs mounts, the next time i see this Problem.
I`m still looking for a way how to find out what is using this memory, when there is no process visible which uses it. Even though this may be a common Linux question
-
I had a look at another server in another pool this morning, which also had memory alerts.
Gues what: There was an unresponsive CIFS ISO share too.
The share looked like it was online form XCP-NG Center, but the containing isos were not shown.
I could not detach it from XCP-NG Center, but after a few tries i could do a pbd-unplug.
This share was on a smal NAS, which may have been restarted during the pool was running.
So maybe something happens when you have a unresponsive CIFS ISO share, that eats up your RAM.
If this is realy the reason, i think this behaviour changed in never versions om XCP-NG/Xenserver. I had dozens of servers, where the ISO store credentials changed or/and the CIFS servers has been restarted, without this Problem.
-
We're seeing the same kind of development on two servers. Nothing interesting in dmesg or so.
Will have to resize for now I guess.
-
@dave said in Alert: Control Domain Memory Usage:
@olivierlambert said in Alert: Control Domain Memory Usage:
Netdata
Hello Oliver,
thanks for your quick Response.Yes, htop is much prettier, but it doen`t see more the top, at least in this case:
I think, Netdata will also just see those things?
Hi there! Hope it's okay that I answer regarding this topic....
We've also this Error and in 'Notifications' in the XCP-NG Center I can see the following:

Is there any possibility to resolve this error without restarting the hole host? How can I restart the toolstack? Can I do it without an interrupt of the business?
We've also raised up the Memory for the Controller Domain from 4 --> 8GB..... -
In Xen Orchestra, restarting the toolstack is clicking on a button. This won't affect running VMs (except if you are in the middle of an hypervisor operation, like migrating/exporting). Restarting the toolstack won't fundamentally solve your issue.
Adding more memory into the dom0 is a good idea in general (depending on the total memory you have). 8GiB is a good start. This will require a host reboot in any case, to be taken into account.
-
@olivierlambert said in Alert: Control Domain Memory Usage:
In Xen Orchestra, restarting the toolstack is clicking on a button. This won't affect running VMs (except if you are in the middle of an hypervisor operation, like migrating/exporting). Restarting the toolstack won't fundamentally solve your issue.
Adding more memory into the dom0 is a good idea in general (depending on the total memory you have). 8GiB is a good start. This will require a host reboot in any case, to be taken into account.
Hi Olivier, thanks for your fast reply. We've identified on our systems that the Openvswitch needs a lot of memory and therefore we wanna restart it.
Is it possible to do this without restarting the hole host and without an downtime? -
Just use systemd restart to do that (eg
systemctl restart <whatever>).Regarding growing memory on your host, this will require a reboot though.
-
Hi, i still have this problem on 5 hosts in 2 pools. I increased the dom0 memory to 12GB and 16GB, but its still happening. XCP 8.0 and 8.1 involved. On hosts with more VMs it occures more often then on hosts with less VMs. Its happens between 40 - 140 days, depending on the number of VMs running.
Yes, ownvswitch has the greatest memory usage, but ist still only a small percentage. I still cant see, what eats up the memory. Restarting XAPI doensn`t change anything.
top - 18:37:06 up 144 days, 19:43, 1 user, load average: 2.23, 2.12, 2.16 Tasks: 443 total, 1 running, 272 sleeping, 0 stopped, 0 zombie %Cpu(s): 1.3 us, 1.7 sy, 0.0 ni, 95.7 id, 0.8 wa, 0.0 hi, 0.1 si, 0.4 st KiB Mem : 12205932 total, 91920 free, 11932860 used, 181152 buff/cache KiB Swap: 1048572 total, 807616 free, 240956 used. 24552 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2248 root 10 -10 1302696 158708 9756 S 1.0 1.3 2057:54 ovs-vswitchd 3018 root 20 0 597328 25804 4 S 0.3 0.2 635:40.46 xapi 1653 root 20 0 255940 20628 1088 S 0.0 0.2 1517:12 xcp-rrdd 1321 root 20 0 142596 15100 7228 S 0.3 0.1 40:49.02 message-switch 6571 root 20 0 213720 12164 4920 S 0.0 0.1 9:30.58 python 1719 root 20 0 62480 9980 3488 S 0.0 0.1 269:35.54 xcp-rrdd-xenpm 13506 root 20 0 43828 9652 2856 S 0.0 0.1 0:05.11 tapdisk 1721 root 20 0 111596 8684 1592 S 0.0 0.1 337:51.20 xcp-rrdd-iostat 2342 root 20 0 138220 8656 2744 S 0.0 0.1 218:17.74 xcp-networkd 1639 root 20 0 1241012 8428 6024 S 0.0 0.1 150:25.56 multipathd 6092 root 20 0 42428 7924 3924 S 17.2 0.1 2987:48 tapdisk 1649 root 20 0 75116 6980 2192 S 0.0 0.1 294:06.89 oxenstored 5436 root 10 -10 35432 6760 4112 S 0.0 0.1 0:00.03 iscsid 13898 root 20 0 40824 6648 2856 S 0.0 0.1 0:09.13 tapdisk 3547 root 20 0 39852 5564 3376 S 0.7 0.0 54:01.72 tapdisk 3006 root 20 0 40028 5460 2496 S 14.2 0.0 19:10.48 tapdisk 1326 root 20 0 67612 5220 2840 S 0.0 0.0 529:23.01 forkexecd 3027 root 20 0 108028 5176 5176 S 0.0 0.0 0:00.02 xapi-nbd 15298 root 20 0 39644 5156 3940 S 0.7 0.0 853:39.92 tapdisk 3694 root 20 0 238044 5084 5084 S 0.0 0.0 0:01.39 python 6945 root 20 0 39484 4860 3804 S 15.8 0.0 591:05.22 tapdisk 24422 root 20 0 44980 4844 4756 S 0.0 0.0 0:00.22 stunnel 11328 root 20 0 44980 4684 4640 S 0.0 0.0 0:00.06 stunnel 2987 root 20 0 44980 4608 4440 S 0.0 0.0 0:00.29 stunnel 6095 root 20 0 38768 4588 2912 S 0.0 0.0 764:33.14 tapdisk 1322 root 20 0 69848 4388 3772 S 0.0 0.0 1:15.05 varstored-guard 14873 root 20 0 38688 4360 2744 S 0.0 0.0 57:33.78 tapdisk 1329 root 20 0 371368 4244 3664 S 0.0 0.0 0:41.49 snapwatchd 1328 root 20 0 112824 4212 4212 S 0.0 0.0 0:00.02 sshd 2219 root 10 -10 44788 4004 3064 S 0.0 0.0 138:30.56 ovsdb-server 3278 root 20 0 307316 3960 3764 S 0.0 0.0 3:15.34 stunnel 17064 root 20 0 153116 3948 3772 S 0.0 0.0 0:00.16 sshd 30189 root 20 0 38128 3716 2828 S 0.0 0.0 97:30.65 tapdisk@olivierlambert Do you have an idea how to get to the root of this? Is it maybe possible to get some (paid) support to check this?
-
Sounds like a memory leak. It's hard to pinpoint in general. I would say that investigating on 8.2 as soon it's out would be probably a better thing to do (it will be an LTS).
It will be out in beta soon
-
Just to add that us too have been experiencing the issue pointed out by Dave since we upgraded to 8.0. Even if the in place upgrade did bump the Dom0 memory from 4 to 8GB, we started to get out of memory errors on the pool master after an uptime of around 60 to 70 days.
Our current solution as mentioned in the thread too, is to icrease the memory for Dom0 to 32GBs but this does only buys us more time until the next reboot.
The main problem is that once this happens, backups start to fail and the only solution is to empty the host and reboot, which can be disruptive to some large VMs that don't seem to support live migration very well.
To add some more data, here is a graph of the memory consumption in the master of one of our pools, uptime starts at around week 33 and week 43 is current time (pending a reboot and memory increase for that host). This is a pool of three hosts and 80 vms.
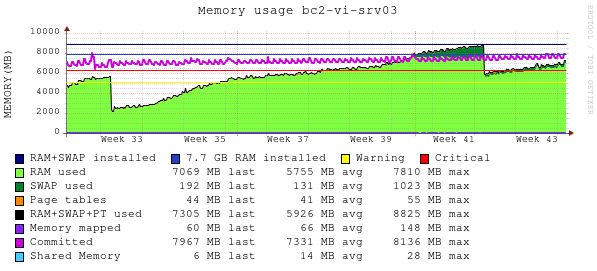
Let me know if we can help with log data or anything else.
-
Please migrate to 8.1 and report if you have the same behavior.
-
@inaki-martinez Could you find out if a specific program uses that memory?
-
@olivierlambert will upgrade our test environment and see if we can see the issue happening again.
@stormi there is nothing using particularly too much ram, listing processes by their RSS rss_usage.txt -
@olivierlambert this still happens at 8.1 also
@stormi it seems that the memory is eating somewhere and doesn't point to specific program. @dave also described here https://xcp-ng.org/forum/post/31693 -
I'd be interested in accessing remotely any host that has this kind of high memory usage without any specific process being an obvious culprit, if someone can give me such access.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login