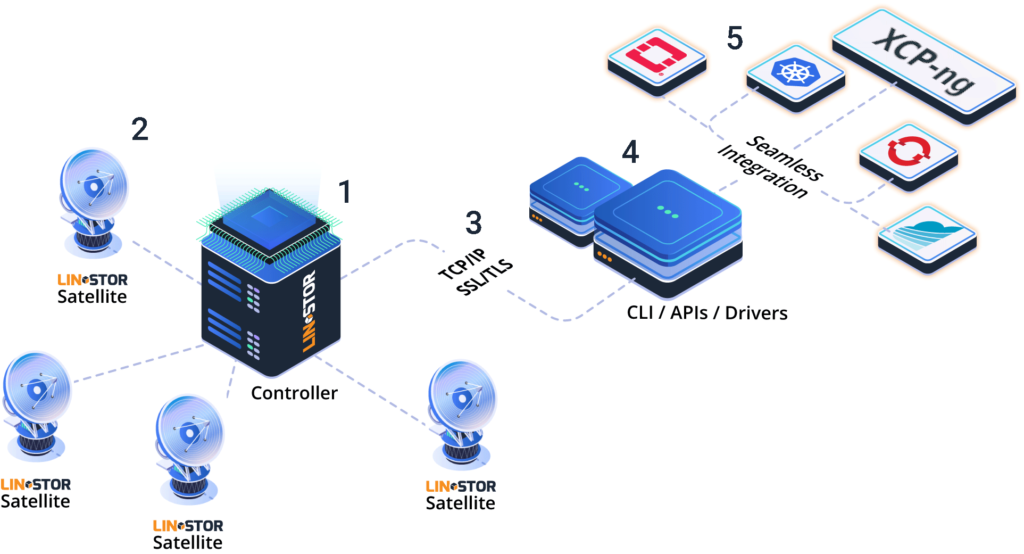
-
It might be done in the future, but that's not the priority for a v1
")
-
@olivierlambert
I just checked the sm repository, and it looks like it wouldn't be that complicated to add a new sm-config and pass it down to the volume creation. Do you accept PR/Contributions on that repository? We're really interested in this feature and I think I can take the time to write the code to handle this. -
The problem will be about to compute the available space if you have different replication number.
But in any cases, contributions are always welcome, we'll discuss details in PR.
-
I am trying this on pool with 5 hosts. Each host has a 4TB HDD installed that I am using for this.
Following the instructions here I download the installer and run it with
./install --disks /dev/sda --force- this runs through and no errors are shown but right at the end it displays:Volume group "linstor_group" not found Cannot process volume group linstor_group Physical volume "/dev/sda" successfully created. Volume group "linstor_group" successfully createdBut then checking the disk I don't see the expected partitions:
[09:12 XCPNG01 ~]# lsblk ... sda 8:0 0 3.7T 0 disk <nothing here> ...Versions
[09:34 XCPNG01 ~]# uname -a Linux XCPNG01 4.19.0+1 #1 SMP Thu Jan 13 12:55:45 CET 2022 x86_64 x86_64 x86_64 GNU/Linux [09:28 XCPNG01 ~]# rpm -qa | grep -E "^(sm|xha)-.*linstor.*" sm-2.30.6-1.1.0.linstor.1.xcpng8.2.x86_64 xha-10.1.0-2.2.0.linstor.1.xcpng8.2.x86_64I should mention that this disk was previously mounted as an SR but is no longer, and also was part of a glusterfs store but is no longer.
If I run
./install --disks /dev/sda --forcea second time it obviously has not much to do as it has installed everything but now I get a slightly different error:Package python-linstor-1.12.0-1.noarch already installed and latest version Nothing to do VG #PV #LV #SN Attr VSize VFree linstor_group 1 0 0 wz--n- <3.64t <3.64t Volume group "linstor_group" successfully removed Volume group "sda" not found Cannot process volume group sda Failed to execute vgremove properly.What should I do to work out what the problem is?
-
Just reading through the
installscript, if thin provisioning is not used (i.e thick provisioning is) then the volume grouplinstor_groupwill get created but no logical volume is created:if subprocess.call(['vgcreate', LINSTOR_GROUP] + disks): print('Failed to execute vgcreate properly.') return os.EX_SOFTWARE if thin and subprocess.call(['lvcreate', '-l', '100%FREE', '-T', '{}/thin_device'.format(LINSTOR_GROUP)]): print('Failed to create thin device properly.') return os.EX_SOFTWARESo are the installation instructions incorrect? Step 3 where it states to check the config before proceeding it states to use
lsblkto check that the LVM logical volumes are created - but it looks to me like this does not occur unless thin provisioning is used?I can see that the volume group has been created as you would expect by looking at the install script.
[08:41 XCPNG01 ~]# pvscan ... PV /dev/sda VG linstor_group lvm2 [<3.64 TiB / <3.64 TiB free] ... [08:35 XCPNG01 ~]# vgdisplay ... --- Volume group --- VG Name linstor_group System ID Format lvm2 Metadata Areas 1 Metadata Sequence No 1 VG Access read/write VG Status resizable MAX LV 0 Cur LV 0 Open LV 0 Max PV 0 Cur PV 1 Act PV 1 VG Size <3.64 TiB PE Size 4.00 MiB Total PE 953861 Alloc PE / Size 0 / 0 Free PE / Size 953861 / <3.64 TiB VG UUID uidJ13-juc7-2cm0-NnkV-wdhA-4fNm-HAWrghAm I misunderstanding the instructions somehow or missing something?
-
Pinging @ronan-a
-
@geoffbland Without thin option, no LVM volume is created. It's expected. You must just have a VG
:# vgs VG #PV #LV #SN Attr VSize VFree VG_XenStorage-11daa412-d2b5-cb7c-e8ae-847821e367a6 1 1 0 wz--n- 144.23g 144.23g linstor_groupA LVM volume is only required for the thin driver of LINSTOR.
I updated the main post, it was not totally clear.")
Regarding the force option, I fixed it here: https://gist.githubusercontent.com/Wescoeur/7bb568c0e09e796710b0ea966882fcac/raw/6aacde6b5c55f8e7b70ed585c59b9c2d54a2ea69/gistfile1.txt
It must be:
subprocess.call(['vgremove', '-f', LINSTOR_GROUP, '-y'])instead of:
subprocess.call(['vgremove', '-f', LINSTOR_GROUP, '-y'] + disks) -
@ronan-a said in XOSTOR hyperconvergence preview:
I updated the main post, it was not totally clear.
Thanks for that. I expected this was the case but wanted to be sure.
Looks like this is working so far then I will continue with my installation & testing. -
XOSTOR is now successfully installed on all 5 of my nodes in the cluster.
I ran this command (I'm assuming that this only needs running on one host?).
xe sr-create type=linstor name-label=XOSTOR01 host-uuid=28af0626-7788-4104-9449-xxxxxxxxxxxx device-config:hosts=XCPNG01,XCPNG02,XCPNG03,XCPNG04,XCPNG05 device-config:group-name=linstor_group device-config:redundancy=3 shared=true device-config:provisioning=thickAnd this returned the SR UUID
cf896912-cd71-d2b2-488a-xxxxxxxxxxxxthis looks like it worked as expected.Running
linstor node listshows the following:[12:01 XCPNG01 ~]# linstor node list ╭─────────────────────────────────────────────────────────╮ ┊ Node ┊ NodeType ┊ Addresses ┊ State ┊ ╞═════════════════════════════════════════════════════════╡ ┊ XCPNG01 ┊ COMBINED ┊ 192.168.1.41:3366 (PLAIN) ┊ Online ┊ ┊ XCPNG02 ┊ COMBINED ┊ 192.168.1.42:3366 (PLAIN) ┊ Online ┊ ┊ XCPNG03 ┊ COMBINED ┊ 192.168.1.43:3366 (PLAIN) ┊ Online ┊ ┊ XCPNG04 ┊ COMBINED ┊ 192.168.1.44:3366 (PLAIN) ┊ Online ┊ ┊ XCPNG05 ┊ COMBINED ┊ 192.168.1.45:3366 (PLAIN) ┊ Online ┊ ╰─────────────────────────────────────────────────────────╯ [12:05 XCPNG01 ~]# linstor volume list ╭────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮ ┊ Node ┊ Resource ┊ StoragePool ┊ VolNr ┊ MinorNr ┊ DeviceName ┊ Allocated ┊ InUse ┊ State ┊ ╞════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╡ ┊ XCPNG01 ┊ xcp-persistent-database ┊ DfltDisklessStorPool ┊ 0 ┊ 1000 ┊ /dev/drbd1000 ┊ ┊ InUse ┊ Diskless ┊ ┊ XCPNG02 ┊ xcp-persistent-database ┊ DfltDisklessStorPool ┊ 0 ┊ 1000 ┊ /dev/drbd1000 ┊ ┊ Unused ┊ Diskless ┊ ┊ XCPNG03 ┊ xcp-persistent-database ┊ xcp-sr-linstor_group ┊ 0 ┊ 1000 ┊ /dev/drbd1000 ┊ 1.00 GiB ┊ Unused ┊ UpToDate ┊ ┊ XCPNG04 ┊ xcp-persistent-database ┊ xcp-sr-linstor_group ┊ 0 ┊ 1000 ┊ /dev/drbd1000 ┊ 1.00 GiB ┊ Unused ┊ UpToDate ┊ ┊ XCPNG05 ┊ xcp-persistent-database ┊ xcp-sr-linstor_group ┊ 0 ┊ 1000 ┊ /dev/drbd1000 ┊ 1.00 GiB ┊ Unused ┊ UpToDate ┊ ╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯Strangely running
linstor node listonly works on node XCPNO01, on the other 4 nodes I get the errorError: Unable to connect to linstor://localhost:3370: [Errno 99] Cannot assign requested address. Is this expected?However when I check on XO (from sources) it shows one of the hosts is disconnected.
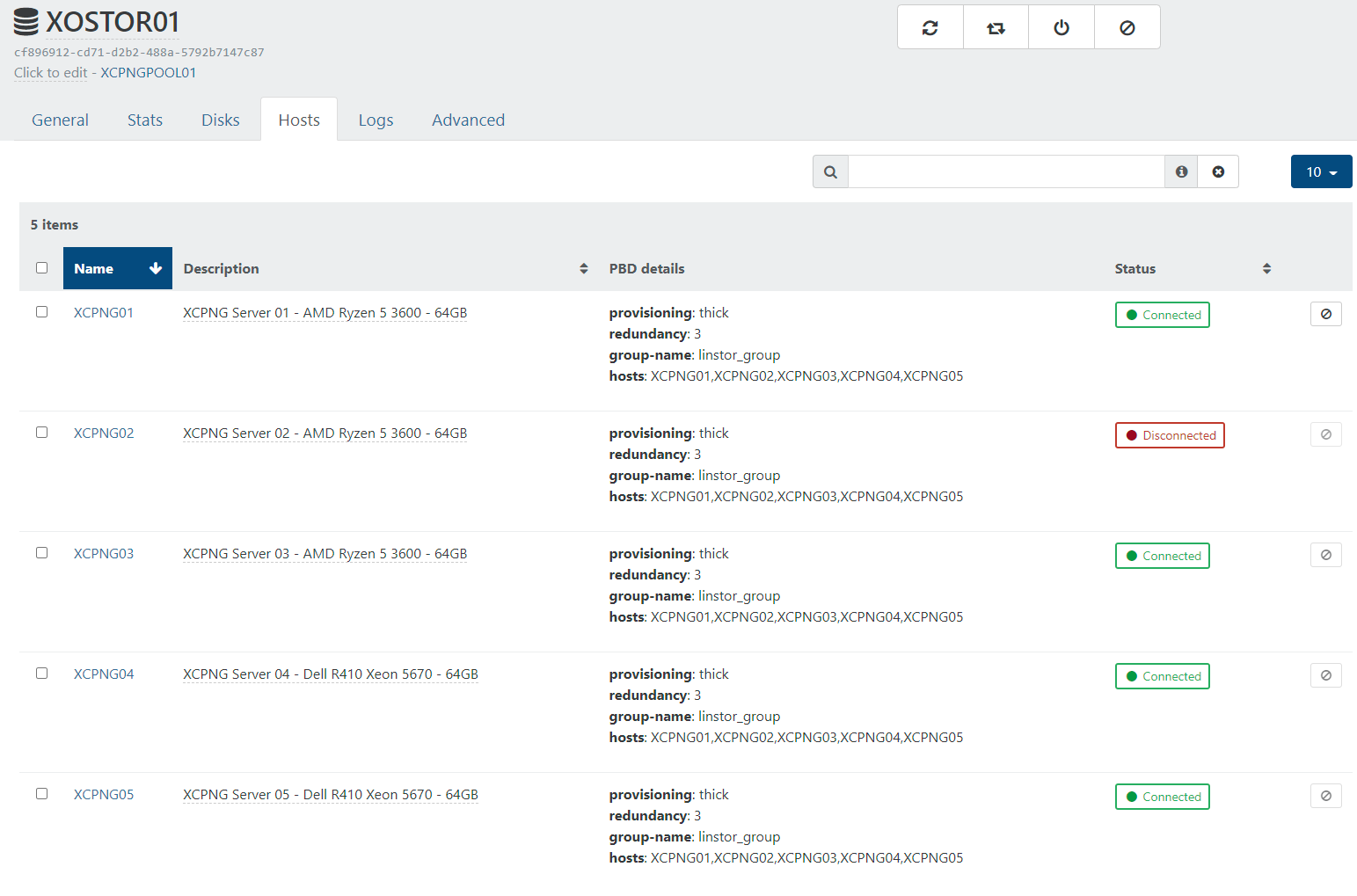
When I try to connect it from XO I get this error, is this related to the problem with linstor commands only working on one host XCPNG01?
pbd.connect { "id": "8040176c-16da-674d-e9bd-708c3a66e68a" } { "code": "SR_BACKEND_FAILURE_47", "params": [ "", "The SR is not available [opterr=Error: Unable to connect to any of the given controller hosts: ['linstor://XCPNG01']]", "" ], "task": { "uuid": "c92909b2-8a4e-e071-3c91-0c89a32b1e01", "name_label": "Async.PBD.plug", "name_description": "", "allowed_operations": [], "current_operations": {}, "created": "20220516T11:12:41Z", "finished": "20220516T11:13:11Z", "status": "failure", "resident_on": "OpaqueRef:a1e9a8f3-0a79-4824-b29f-d81b3246d190", "progress": 1, "type": "<none/>", "result": "", "error_info": [ "SR_BACKEND_FAILURE_47", "", "The SR is not available [opterr=Error: Unable to connect to any of the given controller hosts: ['linstor://XCPNG01']]", "" ], "other_config": {}, "subtask_of": "OpaqueRef:NULL", "subtasks": [], "backtrace": "(((process xapi)(filename lib/backtrace.ml)(line 210))((process xapi)(filename ocaml/xapi/storage_access.ml)(line 32))((process xapi)(filename ocaml/xapi/xapi_pbd.ml)(line 182))((process xapi)(filename ocaml/xapi/message_forwarding.ml)(line 128))((process xapi)(filename lib/xapi-stdext-pervasives/pervasiveext.ml)(line 24))((process xapi)(filename ocaml/xapi/rbac.ml)(line 231))((process xapi)(filename ocaml/xapi/server_helpers.ml)(line 103)))" }, "message": "SR_BACKEND_FAILURE_47(, The SR is not available [opterr=Error: Unable to connect to any of the given controller hosts: ['linstor://XCPNG01']], )", "name": "XapiError", "stack": "XapiError: SR_BACKEND_FAILURE_47(, The SR is not available [opterr=Error: Unable to connect to any of the given controller hosts: ['linstor://XCPNG01']], ) at Function.wrap (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/_XapiError.js:16:12) at _default (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/_getTaskResult.js:11:29) at Xapi._addRecordToCache (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/index.js:949:24) at forEach (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/index.js:983:14) at Array.forEach (<anonymous>) at Xapi._processEvents (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/index.js:973:12) at Xapi._watchEvents (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/index.js:1139:14)" }XCPNG02 is the XCPNG pool master and also the host that I ran the
xe sr-createcommand on to create the SR.What do I need to look at now to resolve this?
-
@geoffbland Well it's a known error resolved in this commit: https://github.com/xcp-ng/sm/commit/df92fcf7193f7f87fd03423293589fb50faa246d
You can modify
/opt/xensource/sm/linstorvolumemanager.pywith this fix on each node, it should repair the PBD connection.FYI, we planned to release a new beta with all our fixes before the end of this month.
-
@ronan-a Thanks that fixed it and all hosts now have the SR connected.
Running
linstor node listonly works on node XCPNO01, on the other 4 nodes I get the errorError: Unable to connect to linstor://localhost:3370: [Errno 99] Cannot assign requested addressstill. Is this expected? -
@geoffbland Yeah, you can only have one running controller in your pool, so you can use the command like this to use the controller remotely:
linstor --controllers=<node_ips> ...Where
node_ipsis a comma-separated list. -
@ronan-a you can only have one running controller in your pool
OK, got it, that makes sense. I think it is time I started reading up on Linstor rather than bugging you with what are probably easy questions to answer if I just read up a bit more. Thanks.
-
This post is deleted! -
What is the URL for the GitHub repo for XOSTOR in case I find some issues and need to report them? I looked under the xcpng project - only sm (Stroage Manager) seemed relevant.
-
@geoffbland Yes, https://github.com/xcp-ng/sm is the right repository.
-
@ronan-a Thanks.
There's no Issues tab on this repo so no way to open issues on this repo. Are Issues turned on for this? -
@geoffbland The entry for issues is this repo: https://github.com/xcp-ng/xcp
The sm repo is used for the pull requests. -
First tests with XOSAN with newly created VMs have been good.
I'm now trying to migrate some existing VMs from NFS (TrueNAS) to XOSAN to test "active" VMs.
With the VM running - pressing the Migrate VDI button on the Disks tab, pauses the VM as expected but when the VM restarts the VDI is still on the original disk. The VDI has not been migrated to XOSAN.
If I first stop the VM and then press the Migrate VDI button on the Disks tab, I then do get an error.
vdi.migrate { "id": "8a3520ad-328f-4515-b547-2fb283edbd91", "sr_id": "cf896912-cd71-d2b2-488a-5792b7147c87" } { "code": "SR_BACKEND_FAILURE_46", "params": [ "", "The VDI is not available [opterr=Could not load f1ca0b16-ce23-408a-b80e-xxxxxxxxxxxx because: No such file or directory]", "" ], "task": { "uuid": "8b3b47ee-4135-fea7-5f30-xxxxxxxxxxxx", "name_label": "Async.VDI.pool_migrate", "name_description": "", "allowed_operations": [], "current_operations": {}, "created": "20220522T12:20:12Z", "finished": "20220522T12:20:54Z", "status": "failure", "resident_on": "OpaqueRef:a1e9a8f3-0a79-4824-b29f-d81b3246d190", "progress": 1, "type": "<none/>", "result": "", "error_info": [ "SR_BACKEND_FAILURE_46", "", "The VDI is not available [opterr=Could not load f1ca0b16-ce23-408a-b80e-xxxxxxxxxxxx because: No such file or directory]", "" ], "other_config": {}, "subtask_of": "OpaqueRef:NULL", "subtasks": [], "backtrace": "(((process xapi)(filename ocaml/xapi-client/client.ml)(line 7))((process xapi)(filename ocaml/xapi-client/client.ml)(line 19))((process xapi)(filename ocaml/xapi-client/client.ml)(line 12325))((process xapi)(filename lib/xapi-stdext-pervasives/pervasiveext.ml)(line 24))((process xapi)(filename lib/xapi-stdext-pervasives/pervasiveext.ml)(line 35))((process xapi)(filename ocaml/xapi/message_forwarding.ml)(line 131))((process xapi)(filename lib/xapi-stdext-pervasives/pervasiveext.ml)(line 24))((process xapi)(filename lib/xapi-stdext-pervasives/pervasiveext.ml)(line 35))((process xapi)(filename lib/xapi-stdext-pervasives/pervasiveext.ml)(line 24))((process xapi)(filename ocaml/xapi/rbac.ml)(line 231))((process xapi)(filename ocaml/xapi/server_helpers.ml)(line 103)))" }, "message": "SR_BACKEND_FAILURE_46(, The VDI is not available [opterr=Could not load f1ca0b16-ce23-408a-b80e-xxxxxxxxxxxx because: No such file or directory], )", "name": "XapiError", "stack": "XapiError: SR_BACKEND_FAILURE_46(, The VDI is not available [opterr=Could not load f1ca0b16-ce23-408a-b80e-xxxxxxxxxxxx because: No such file or directory], ) at Function.wrap (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/_XapiError.js:16:12) at _default (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/_getTaskResult.js:11:29) at Xapi._addRecordToCache (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/index.js:949:24) at forEach (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/index.js:983:14) at Array.forEach (<anonymous>) at Xapi._processEvents (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/index.js:973:12) at Xapi._watchEvents (/opt/xo/xo-builds/xen-orchestra-202204291839/packages/xen-api/src/index.js:1139:14)" }Exporting the VDI from NFS and (re)importing as a VM on XOSTOR does work.
I'm guessing this is not a problem with XOSTOR specifically but with XO or NFS, still I would like to work out what is causing migration and how to fix it?
Also I have noticed that the underlying volume on XOSTOR/linstor that was created and started to be populated does get cleaned up when the migrate fails.
This is using XO from the sources - updated fairly recently (commit 8ed84) and XO server 5.92.0.
-
It could be interesting to understand why the migration failed the first time. Is there absolutely no error during this first migration?
