Hi All,
I came across a similar topic, which you can find here: Old Topic.
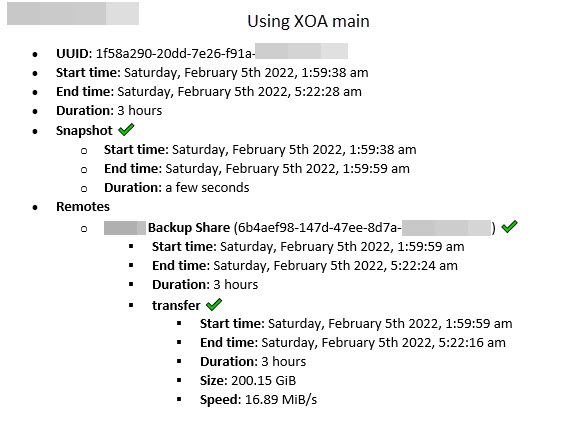
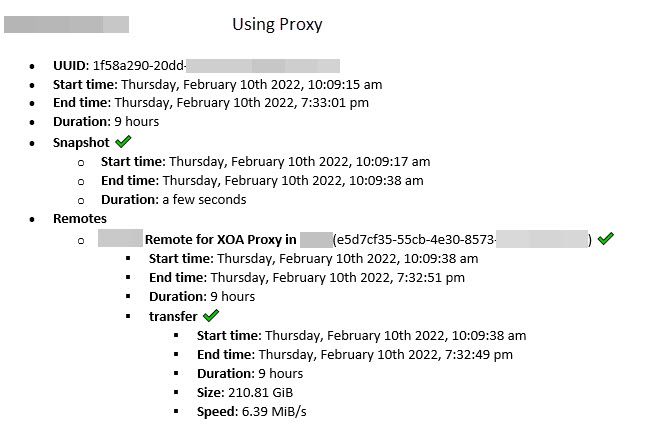
I initially replied to it but decided it would be better to start a new thread. We have several pools, and a few VMs in some pools consistently fail during the full backup with the below error.
In the previous discussion, it was mentioned that rebooting the host resolved the issue. However, I recently performed a rolling pool upgrade on one of our pools, so all nodes were rebooted, and I also rebooted the VMs. Does anyone have any suggestions on what might be causing this problem? I'm considering cloning the problematic VMs, but that seems a bit drastic.
Build: 2024-10-30
Version: 8.2
DBV: 0.0.1
Thank you
Neil
result": {
"name": "BodyTimeoutError",
"code": "UND_ERR_BODY_TIMEOUT",
"message": "Body Timeout Error",
"stack": "BodyTimeoutError: Body Timeout Error\n at Timeout.onParserTimeout [as callback] (/usr/local/lib/node_modules/@xen-orchestra/proxy/node_modules/undici/lib/dispatcher/client-h1.js:626:28)\n at Timeout.onTimeout [as _onTimeout] (/usr/local/lib/node_modules/@xen-orchestra/proxy/node_modules/undici/lib/util/timers.js:22:13)\n at listOnTimeout (node:internal/timers:569:17)\n at process.processTimers (node:internal/timers:512:7)"
}
```.