We went the route of copying all the VMs, deleting the old, starting up the new versions. Snapshots all working after machines created.
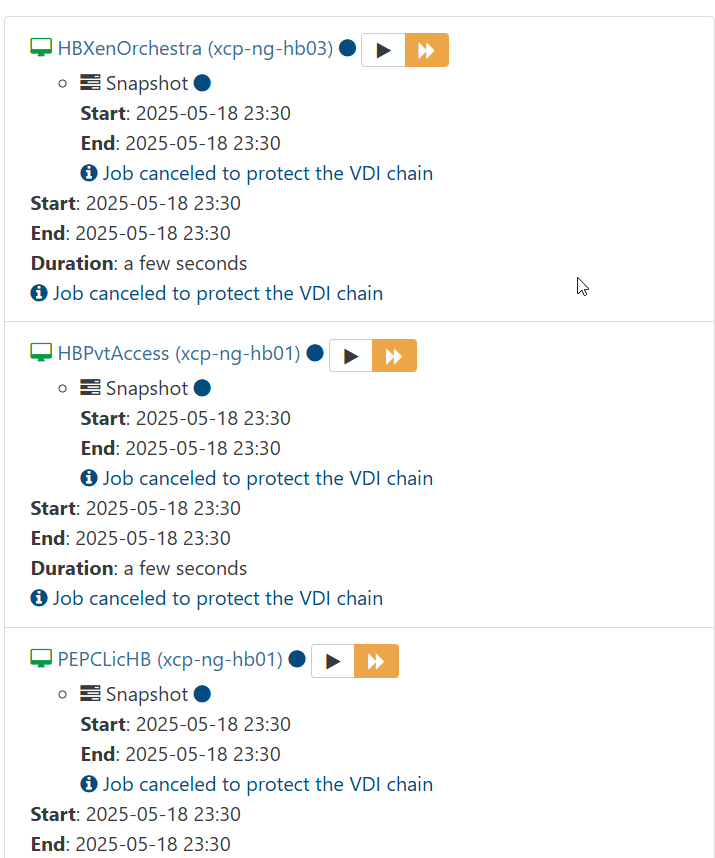
This weekend my fulls ran and 4 of the machines continue to have VDI chain issues. The other 4 back up correctly now.
Any other thoughts we might pursue? The machines still failing don't seem to have any consistency about them. Windows 2022, 11, and linux in the mix. All 3 of my hosts are in play. 2 are on 1 and the other 2 machines are split amongst the other two hosts. All hosts are fully up-to-date patch-wise as is XO.
The machines DO backup right now if we choose force restart button in the XO interface for backups. For now. That worked before for a few months then also stopped working. When we do the force restart it does create a snapshot at that time. During the failed scheduled backup the snapshot is not created.
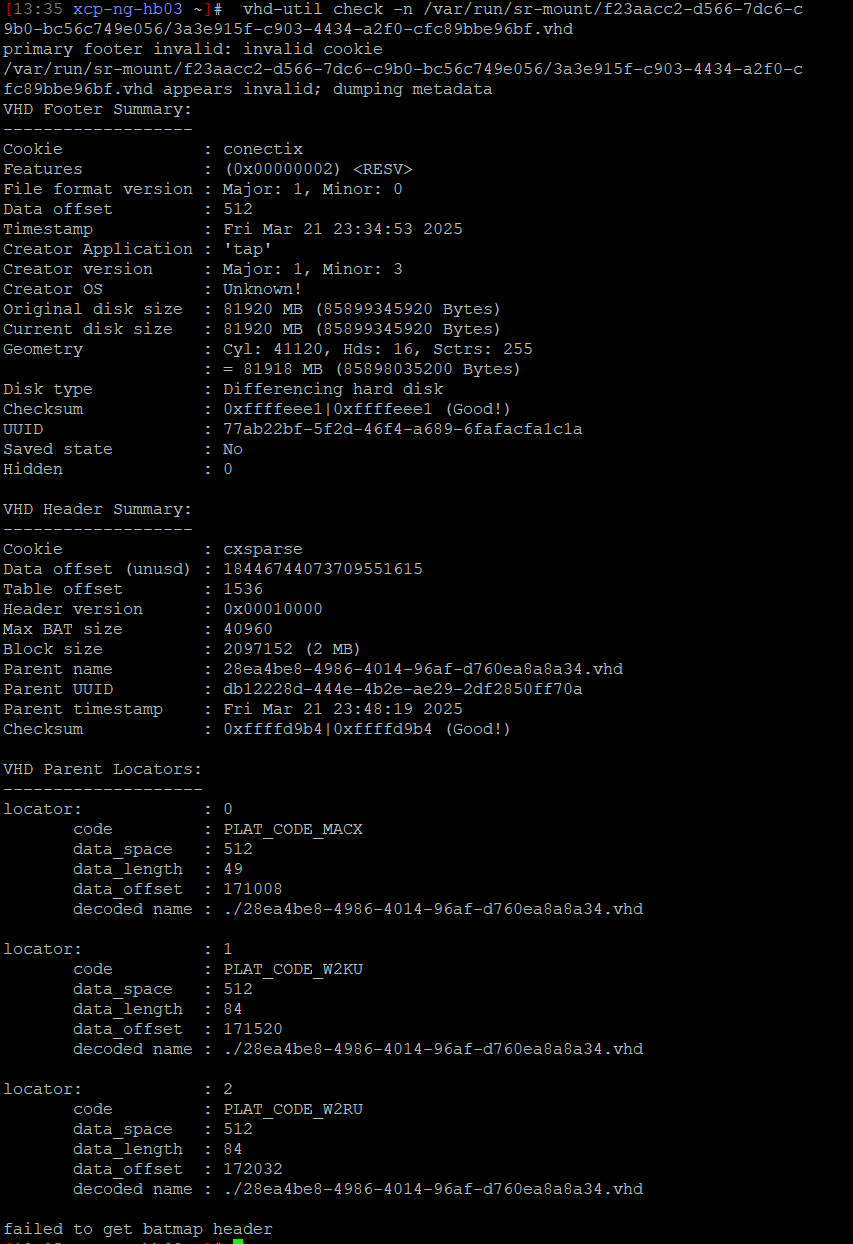
Somehow despite these being brand new copied VMs I see the same things in the SMlog file (attached is a segment of that file where at least 3 of those undo coalesce errors show) where it looks like an undo leaf-coalesce but no other real specifics.
Anything else we can troubleshoot with?
Thanks,
Nick
") -- just a shade out of my depth!
-- just a shade out of my depth!