I had to revert to a Snapshot on one of my VMs. Now it's getting stuck at Boot device: Hard Disk - success. Please help if you can.
Thank you!
R
Offline
Posts
-
Boot device: Hard Disk - Success
-
RE: Snapshot Question
Sorry, I'm asking if I should be good deleting the snapshots
-
Snapshot Question
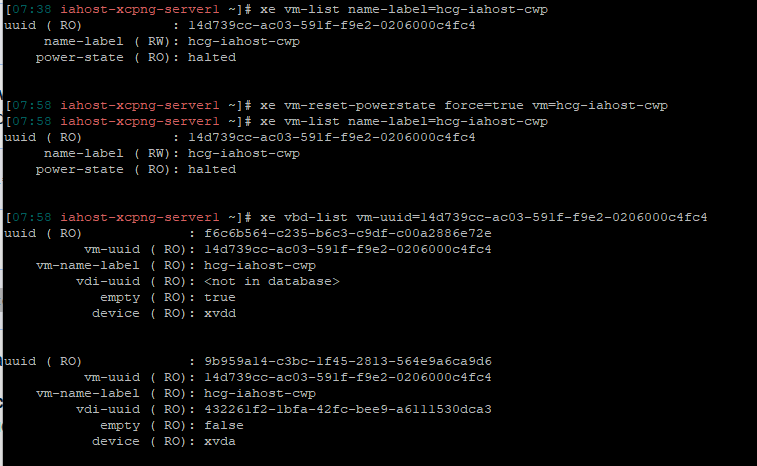
I had to use xcp-ng center to create a couple of snapshots as I fixed a VM. XOA was not accessible a the time so I couldn't use that. I plan on deleting those this weekend after I do some backups of accounts on it. First: should I use xcp-ng to delete them or should I use XOA? Second: does anything about the following results of " xe vdi-param-list uuid=c1cd8db9-1b75-4677-8e68-11d35689455f" stand out or show issues.
uuid ( RO) : c1cd8db9-1b75-4677-8e68-11d35689455f name-label ( RW): HCGS-IAHOST name-description ( RW): Created by template provisioner is-a-snapshot ( RO): false snapshot-of ( RO): <not in database> snapshots ( RO): 2e236fee-e9b6-4110-9ad3-f7eb95b21a31; aefd7cd0-d06f-41ae-95f3-438b3cce1898 snapshot-time ( RO): 20250909T23:06:59Z allowed-operations (SRO): snapshot; clone current-operations (SRO): sr-uuid ( RO): 88d7607c-f807-3b06-6f70-2dcb319d97ea sr-name-label ( RO): Synology iSCSI LUN vbd-uuids (SRO): e797fe13-4bc8-dd73-2115-65bb362f95aa crashdump-uuids (SRO): virtual-size ( RO): 644245094400 physical-utilisation ( RO): 645511774208 location ( RO): c1cd8db9-1b75-4677-8e68-11d35689455f type ( RO): System sharable ( RO): false read-only ( RO): false storage-lock ( RO): false managed ( RO): true parent ( RO) [DEPRECATED]: <not in database> missing ( RO): false is-tools-iso ( RO): false other-config (MRW): xenstore-data (MRO): sm-config (MRO): read-caching-reason-6985c3a2-091d-488b-8de6-4bf40985987b: SR_NOT_SUPPORTED; read-caching-enabled-on-6985c3a2-091d-488b-8de6-4bf40985987b: false; vmhint: OpaqueRef:ffa341bc-f174-4bef-9329-8fb7c08f7896; vdi_type: vhd; host_OpaqueRef:c6daa0e3-c9a4-4763-8bdd-2ca9c5d74ee2: RW; vhd-parent: abf2f2e3-cea0-46c8-8b6f-2eeb1b5ba6c2 on-boot ( RW): persist allow-caching ( RW): false metadata-latest ( RO): false metadata-of-pool ( RO): <not in database> tags (SRW): cbt-enabled ( RO): false -
RE: CBT Error when powering on VM
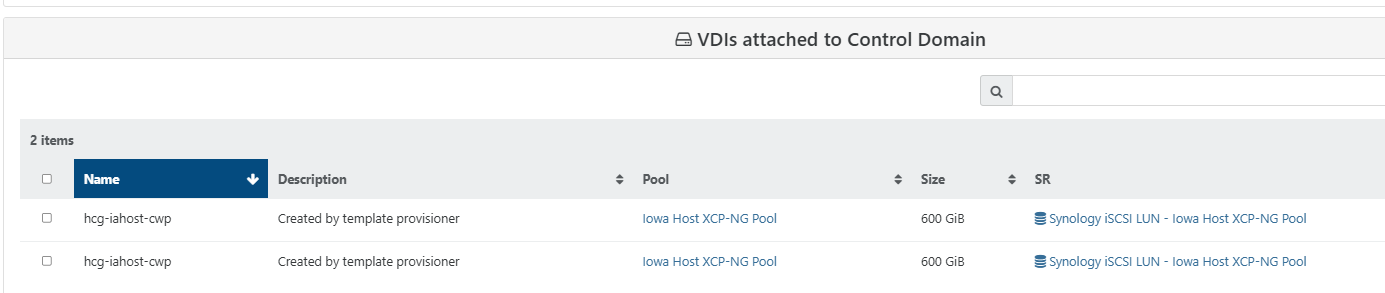
I am still hoping for a miracle with the original VM. Why are there two disks shown if I select the VM in XOA and click attach disk. Image attached
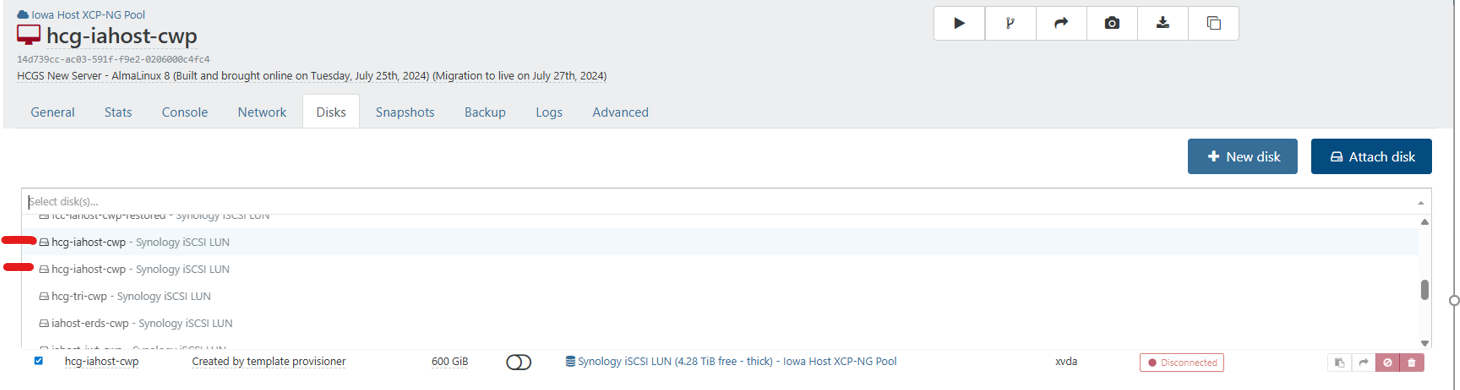
-
RE: CBT Error when powering on VM
Just passing this. I have created a new VM twice now. Once DNF updates are done and it reboots it boots to grub. I'm reinstalling now and will be updating grub before the reboot I guess.
-
RE: CBT Error when powering on VM
Can I do everything in XOA Lite that I can in XCP-NG Center?
-
RE: CBT Error when powering on VM
Center. I'm trying to get away from that and go with XO
-
RE: CBT Error when powering on VM
I understand. However, this is a bran new VM I just created with a new name.

-
RE: CBT Error when powering on VM
Ok, this is weird. I just created a new VM with new name. It is booting and hung at the same message.
vdb vdb-5696: 19 xenbu_dev_prob on device/vdb/5696Not sure what to think.
-
RE: CBT Error when powering on VM
Ok, thank you for looking. Is there anything in my previous screen shots that sticks out? Something else I can try?
-
RE: CBT Error when powering on VM
I tried the second Kernel. I can try safe from Grub. I am not familiar with that, but I will try.
-
RE: CBT Error when powering on VM
That last power on attempt log
{ "id": "0mfciiw3i", "properties": { "method": "vm.start", "params": { "id": "14d739cc-ac03-591f-f9e2-0206000c4fc4", "bypassMacAddressesCheck": false, "force": false }, "name": "API call: vm.start", "userId": "6b37221b-22b6-452b-ba2a-7bd46fc924a9", "type": "api.call" }, "start": 1757420053758, "status": "failure", "updatedAt": 1757420054029, "end": 1757420054029, "result": { "code": "INTERNAL_ERROR", "params": [ "Not_found" ], "call": { "duration": 267, "method": "VM.start", "params": [ "* session id *", "OpaqueRef:570f1cc5-9197-4bd4-8fc3-f75f90e36e4b", false, false ] }, "message": "INTERNAL_ERROR(Not_found)", "name": "XapiError", "stack": "XapiError: INTERNAL_ERROR(Not_found)\n at Function.wrap (file:///usr/local/lib/node_modules/xo-server/node_modules/xen-api/_XapiError.mjs:16:12)\n at file:///usr/local/lib/node_modules/xo-server/node_modules/xen-api/transports/json-rpc.mjs:38:21\n at runNextTicks (node:internal/process/task_queues:60:5)\n at processImmediate (node:internal/timers:454:9)\n at process.callbackTrampoline (node:internal/async_hooks:130:17)" } -
RE: CBT Error when powering on VM
It acts like it is starting normally and goes to the Kernel version selection for Alma, starts to boot then shows paused, then goes back to powered off state and shows the attached.
-
RE: CBT Error when powering on VM
The VM is now starting to the Alma boot page, goes past that then shows Paused. Then just goes back to a powered off state.