
DPUs and the future of virtualization
Today we'll talk about a new trend coming in the virtualization world: DPUs, or Data Processing Units.
Context
The traditional Xen virtualized infrastructure relied on 3 things:
- Compute: via your machine CPU, provided by Xen, where the hypervisor is scheduling the "real" CPUs time, but also isolating memory between virtual machines.
- Storage: accessed via your dom0, you have flexibility with a storage layer (eg creating virtual disks via LVM or VHD files on your local NVMe drive, or inside an NFS share).
- Network: also in your dom0, thanks to OVS (Open vSwitch), creating all the VLANs and such that you need
We could also add vGPU or PCI passthrough for specific needs. Note that PCI passthrough will deliver bare-metal performance, but removing entirely the flexibility you had with an extra layer (network or storage). All of this worked for almost 20 years. So why is there change now?
By the way, I did a presentation during the latest Xen Summit 2021, exactly on that topic:
End of an era
This model was fine, until we saw the combination of multiple events:
- Storage systems are getting a LOT faster. SSDs on SATA and now NVMe. The gap from HDD is so high that even affordable NVMe drives can saturate your CPU. And if you add encryption or compression on top of it, there's an obvious CPU bottleneck.
- Network is following the same trend. 10G is the basic thing, while 40G or even 100G is entirely possible even with a small budget. As for storage, the amount of data to move starts to be bigger than your CPU can handle (which isn't made to do a lot of parallel tasks). More than raw network speed, there's extra features costing your main CPU extra efforts (packet tagging, tunnels and so on).
- Finally, CPU context switches are "costing" more resources than before. Since big x86 flaws like Meltdown and Spectre, the mitigation price isn't small. Plus, x86 raw CPU power wasn't growing as fast as network or storage speed. Combine it with the two previous points, you have the 3 reasons why having only one big x86 processor is coming to an end!
We could also add another argument: all this main x86 CPU time is "wasted" on non-efficient tasks (network and storage), instead of being used for its main purpose (what we call "compute"). It's not huge when you have a few machines, but now imagine a big cloud provider like AWS: all this wasted money CPU time that could be sold!
So what's next?
DPU: move the data around
Since we've identified that your main CPU is overused for "non-compute" tasks, like moving data for network or storage tasks, the next step is to offload it. In fact, it's not a surprise that AWS spent a lot of effort with Nitro exactly for this (economy of scale).
Because of the nature of this massive amount of data, you need a chip that will be specialized enough (massively parallel) but also programmable so you can provide a versatile solution, eg both for storage or network. That's where the Data Processing Unit (DPU) enters.
What's inside
Inside an "average" DPU, you'll usually find what could be called "a PC inside your PC", via an SoC (System on Chip), running on Arm or other CPU architecture. Note that these products are very new. This means there isn't any consolidation yet, no specific unifying "standards".
Those DPUs are generally running on Linux (easy to get drivers for NVMe or to get OVS running into it for example).
You can find various vendors:
- Broadcom (Stingray SmartNIC, Arm SoC based)
- Nvidia (BlueField 2, via Mellanox, Arm SoC based)
- Intel (N3000, Intel Arria FPGA based)
- AMD (via Xilinx and its Alveo U25, Xilinx Zynq based)
- Netronome (OCP Agilio CX, unknown CPU)
- Fungible (F1, MIPS64 based)
- Marvell (LiquidIO III, Arm SoC based)
- Kalray (K200-LP, MPPA3 Coolidge based)
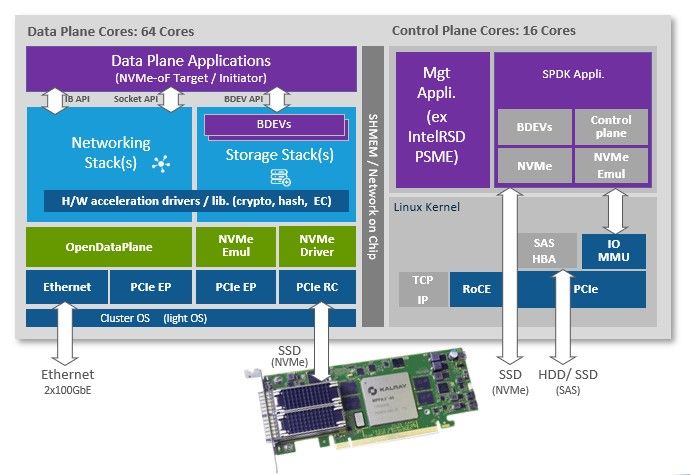
And here is what a DPU card looks like:


The Kalray card design is really interesting with an 80 core design, with 5 blocks with 16 cores each (MPPA3 Coolidge CPU design):
Example use cases
This technology is obviously great for any hosting company: more CPU time for your virtual machines, while providing more performances for network and storage. That's why companies like Scaleway are interested by those technologies. See the official announcement for more details.

But there's also other possibilities, where you need extreme level of performances while getting a flexible layer (virtualization) on top. This is what James Tervit said, CEO of EWI Tech Ltd (ETL), a new start-up focused on engineering more efficient network / Data Center architectures:
ETL through the benefits of reduced space, weight, power and increased encrypted data throughput created by its peering exchange technology, recognizes the bottleneck within conventional data storage architectures. DPU's have great potential to remove those bottlenecks, providing much needed efficiencies to data center infrastructure. As a company we have planned for the continual development of DPU technology within our roadmap to help clients reduce Ethernet/storage latency whilst increasing security.

Security bonus
In the Xen model with the usual privileged domain (dom0), offloading pre-existing software outside it (like OpenvSwitch or the storage stack) is also a way to reduce the dom0's attack surface. Then, the dom0 is only here to manage the API and that's it!
In the long run, we could even imagine to move the platform API in the DPU, so you don't need a dom0 anymore. In fact, the DPU could act "somehow" as your dom0.
Toward a product
A technical solution is great, but it's only part of solving the problem. You must have an integrated product. That's how we build things with XCP-ng and Xen Orchestra.
That's why we are working with Kalray, a DPU manufacturer: we want to build a solution with them, entirely integrated with our stack.
Read the official announcement here.
In the end, it means only dealing with the Xen Orchestra web UI to configure your storage/network through the DPU, and then you can enjoy the flexibility of our virtualization platform while having bare-metal level performance. Best of both worlds 🚀
A future devblog will show you our current initial tests and benchmarks. Stay tuned!


