How to improve backup performance, where's my bottleneck
-
- Check the write speed you can have on the NFS share, from XOA (eg using
fio). We can assist if you open a support ticket. - If you add more backup and overall speed is capped at some point, it means XOA, its network, or its remote are a bottleneck somewhere. So you need to isolate each of one to find the culprit.
- Check the write speed you can have on the NFS share, from XOA (eg using
-
Hi,
I've been struggling with this for many years and I havent found any solution yet.
Our setup is not exactly like yours, but it is simular.We have 10st XenServer's with 2x10Gb each in 2 different pools, the SR's are located on a NFS share over 4x10Gb and benchmarks from within a VM gives 450-600MB/s in both read and write so I know that is not the limiting factor.
XOA runs in Pool A, so the physical host that it runs on has 2x10Gb NIC.The backup NFS are 2 different FreeNAS machines with 2x1Gbit nic in each, running a VM from there and running a disk-benchmark gives me around 100-110MB/s per NFS share, in total around ~200MB/s which is fine.
When we backup we backup about 100 VM's to the 2 NFS shares, Pool A backups to NFS Backup A and Pool B backups to NFS Backup B and no matter what we do the network seems to be limited to 800Mbit/s.
If we backup a single VM it goes up to 800Mbit/s, if we backup 4 at the same time it is still limited to 800Mbit/s, since all traffic passes through XOA I am under the understanding that this must be a limitation in XOA or the XAPI-mechanism used by XOA to export the VM's. -
In this case, we did some benchmarks in support ticket, and saw that the NFS share write speed in random 4K were pretty low, explaining likely the speed observed.
-
@nikade said in How to improve backup performance, where's my bottleneck:
Hi,
I've been struggling with this for many years and I havent found any solution yet.
Our setup is not exactly like yours, but it is simular.We have 10st XenServer's with 2x10Gb each in 2 different pools, the SR's are located on a NFS share over 4x10Gb and benchmarks from within a VM gives 450-600MB/s in both read and write so I know that is not the limiting factor.
XOA runs in Pool A, so the physical host that it runs on has 2x10Gb NIC.The backup NFS are 2 different FreeNAS machines with 2x1Gbit nic in each, running a VM from there and running a disk-benchmark gives me around 100-110MB/s per NFS share, in total around ~200MB/s which is fine.
When we backup we backup about 100 VM's to the 2 NFS shares, Pool A backups to NFS Backup A and Pool B backups to NFS Backup B and no matter what we do the network seems to be limited to 800Mbit/s.
If we backup a single VM it goes up to 800Mbit/s, if we backup 4 at the same time it is still limited to 800Mbit/s, since all traffic passes through XOA I am under the understanding that this must be a limitation in XOA or the XAPI-mechanism used by XOA to export the VM's.It's interesting that you mention that number. As that's pretty much spot on the wall that my transfers hit, at around 750Mbit. It's not a network thing as network transfers have been tested at 10 times that speed.
I have 12x spinning SAS disks in RAID0. Doing a normal sequential file copy (while backups are happening) they can manage about 450MBtyes/sec transfer. But the test using FIO I did was Olivier pointed to transfer speeds of more like 13Mbtyes/second for random access. A pretty huge difference. Which if the backups aren't streaming in entirely sequentially - as they wouldn't be if there's like 10 happening at once, then that's going to limit the speed somewhat.
Notably if I look at my XOA server (on the same box as the NFS server) I can see traffic coming in at a very stead 70MBytes/sec but passed onto NFS in bursts of around 300MBytes/sec.
-
That's because on how streams are working, there's a back pressure applied. I don't think we keep any buffer (or a very tiny one) on the buffer level.
I'll ask @julien-f about this.
-
@olivierlambert said in How to improve backup performance, where's my bottleneck:
That's because on how streams are working, there's a back pressure applied. I don't think we keep any buffer (or a very tiny one) on the buffer level.
I'll ask @julien-f about this.
Yes indeed, I've noticed that over a long time and the amount varies with the amount of memory XOA is given. The default of 2GB very little, I've given it 32GB so it stores quite a bit.
-
That's a good question, I have a very partial understanding on how Node streams are working at low-level. This is more a question for Node experts

-

The main question being. If the disks can take 300MByte/s in burst, could they maintain that all the time? Perhaps not. Just that nikade's post above makes me wonder if there is some 1Gbit (with overheads) limit in node itself.
It's most likely disk speed limited, but interesting to explore all the same.
-
I don't think it's a Node limit, my bet is the content that require a lot of random seeks everywhere, limiting the storage speed. It would be interesting to do your same backup on a very fast NVMe drive, just for the benchmark.
-
As it happens I do have an expiring server I can use for testing with NVME. So XOA stays where it is and I establish a new CentOS7 VM on this host to act as a remote. It's using a standard xcp-ng VDI not passthrough disk like the other one.
An
fiotest gives: write: IOPS=135k, BW=526MiB/s (551MB/s)(1950MiB/3711msec)Now keep in mind my current backups are still running through XOA - it's a production backup.
However I kick off a backup from a different subset of servers that the current live backup is runing from. It hits the NVME NFS server and writes to disk at .... 30MBps :Z
The most interesting aspect is the incoming bandwidth to XOA. You'd think if it were a backpressure issue due to not being able to write to the disk of the remote fast enough, that the incoming bandwidth would increase as it's sending it out to two hosts. In fact the opposite seems to happen, plus the bandwdith being sent to my 'live' backup decreases in proportion to the bandwidth now being sent to the NVME remote.

I'm not sure what this means but it is interesting.
-
Indeed, it's interesting. You did the
fiorandwrite test with 4k? -
I used the command line you sent to me
fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=test --bs=4k --iodepth=64 --size=4G --readwrite=randwrite --ramp_time=4 test: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=64 fio-3.7 Starting 1 process test: No I/O performed by libaio, perhaps try --debug=io option for details?4s] test: (groupid=0, jobs=1): err= 0: pid=2290: Thu Jan 30 10:24:50 2020 write: IOPS=148k, BW=576MiB/s (604MB/s)(1905MiB/3306msec) bw ( KiB/s): min=554144, max=599104, per=99.60%, avg=587724.00, stdev=16710.46, samples=6 iops : min=138536, max=149776, avg=146931.00, stdev=4177.61, samples=6 cpu : usr=11.56%, sys=42.24%, ctx=30262, majf=0, minf=23 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=215.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0% issued rwts: total=0,487662,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=64 Run status group 0 (all jobs): WRITE: bw=576MiB/s (604MB/s), 576MiB/s-576MiB/s (604MB/s-604MB/s), io=1905MiB (1998MB), run=3306-3306msec Disk stats (read/write): xvdb: ios=0/1037381, merge=0/2159, ticks=0/437297, in_queue=437329, util=98.68% -
Great, so indeed, this storage should be able to deal with a lot of random write IOPS
")
-
I think the next experiment would be to use the upcoming backup proxies to remove XOA from the equation and allow for multiple locations feeding into the NFS remote.
-
Yes, but to compare apples to apples, you'll need to avoid using "bigger" network bandwidth (combining proxies bandwidth). You have already 10G everywhere, right?
-
@olivierlambert said in How to improve backup performance, where's my bottleneck:
Yes, but to compare apples to apples, you'll need to avoid using "bigger" network bandwidth (combining proxies bandwidth). You have already 10G everywhere, right?
No. The backups server has 10G but the server it's backing up have a mixture of 1G and 2G.
At the moment things are acceptable, and disk performance is going to be a limitation anyway, this is now from a personal interest side!
-
And this is great that you are interested to that, because it helps to push things forward
Eager to have proxies coming in beta. -
server has 10G DAC to dedicated 10G SW, Disk its writing to is a NAS iSCSI Target with a single 10GBe NIC. Network Traffic is low under 30Mb/s
 image url)
image url)
png)
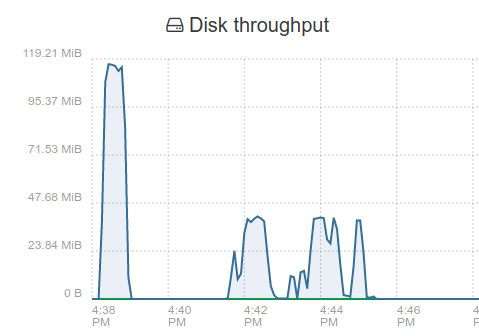
first peek is memory read.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login