backblaze b2 / amazon s3 as remote in xoa
-
@nraynaud ping
-
@dodgethis thank you, I will look harder into this.
-
@nraynaud glad to help somehow

-
Confirmed bumping to 12 Gb RAM allowed my "larger" VM's (60 GB+) to complete.
xo-server 5.73.0
xo-web 5.76.0 -
Can someone please test the issue with the current master branch please?
-
@nraynaud Will aim to do this over the weekend
-
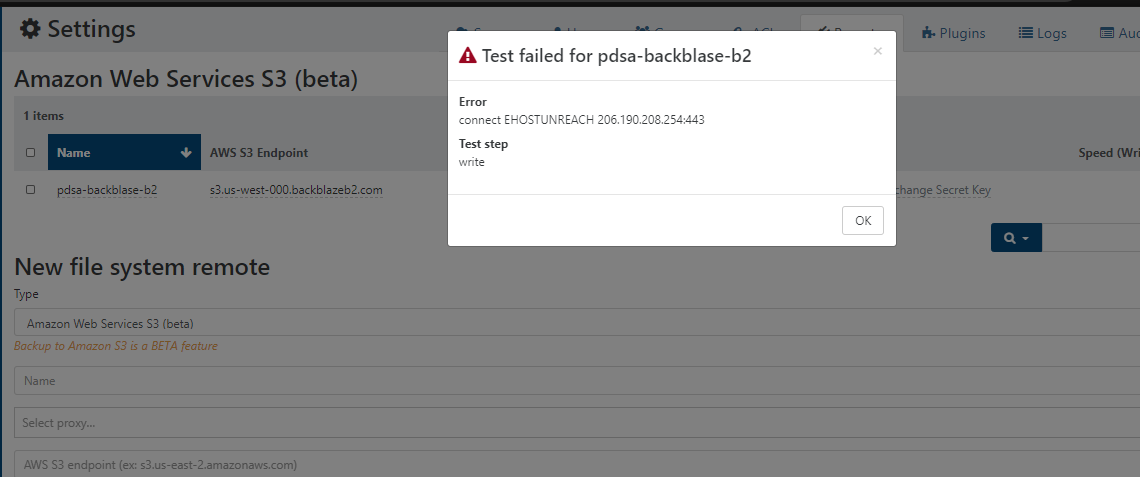
I cannot get the backup to run; I have now tried about 12 times to run a backup that should complete in under 2 hours; without a timeout it runs on (stopped it after 10 hours), with a timeout of 3 hours it consistently fails with 'interrupted' without explanation.
Looking through the logs, we've got a lot of buffer allocation errors, it starts with this:
xo:xo-server ERROR uncaught exception { error: Error [RangeError]: Array buffer allocation failed at new ArrayBuffer (<anonymous>) at new Uint8Array (<anonymous>) at new FastBuffer (internal/buffer.js:950:1) at createUnsafeBuffer (buffer.js:149:12) at allocate (buffer.js:419:10) at Function.allocUnsafe (buffer.js:384:10) at BufferList._getBuffer (/opt/xen-orchestra/@xen-orchestra/fs/node_modules/readable-stream/lib/internal/streams/buffer_list.js:166:24) at BufferList.consume (/opt/xen-orchestra/@xen-orchestra/fs/node_modules/readable-stream/lib/internal/streams/buffer_list.js:119:54) at fromList (/opt/xen-orchestra/@xen-orchestra/fs/node_modules/readable-stream/lib/_stream_readable.js:1073:24) at Transform.Readable.read (/opt/xen-orchestra/@xen-orchestra/fs/node_modules/readable-stream/lib/_stream_readable.js:465:20) at ManagedUpload.fillStream (/opt/xen-orchestra/node_modules/aws-sdk/lib/s3/managed_upload.js:422:25) at Response.<anonymous> (/opt/xen-orchestra/node_modules/aws-sdk/lib/s3/managed_upload.js:574:24) at Request.<anonymous> (/opt/xen-orchestra/node_modules/aws-sdk/lib/request.js:369:18) at Request.callListeners (/opt/xen-orchestra/node_modules/aws-sdk/lib/sequential_executor.js:106:20) at Request.emit (/opt/xen-orchestra/node_modules/aws-sdk/lib/sequential_executor.js:78:10) at Request.emit (/opt/xen-orchestra/node_modules/aws-sdk/lib/request.js:688:14) at Request.transition (/opt/xen-orchestra/node_modules/aws-sdk/lib/request.js:22:10) at AcceptorStateMachine.runTo (/opt/xen-orchestra/node_modules/aws-sdk/lib/state_machine.js:14:12) at /opt/xen-orchestra/node_modules/aws-sdk/lib/state_machine.js:26:10 at Request.<anonymous> (/opt/xen-orchestra/node_modules/aws-sdk/lib/request.js:38:9) at Request.<anonymous> (/opt/xen-orchestra/node_modules/aws-sdk/lib/request.js:690:12) at Request.callListeners (/opt/xen-orchestra/node_modules/aws-sdk/lib/sequential_executor.js:116:18) { code: 'RangeError', time: 2021-01-16T22:07:11.590Z } }...followed by this repeating numerous times:
xo:xo-server ERROR uncaught exception { error: RangeError: Array buffer allocation failed at new ArrayBuffer (<anonymous>) at new Uint8Array (<anonymous>) at new FastBuffer (internal/buffer.js:950:1) at createUnsafeBuffer (buffer.js:149:12) at allocate (buffer.js:419:10) at Function.allocUnsafe (buffer.js:384:10) at Function.concat (buffer.js:564:25) at ManagedUpload.fillStream (/opt/xen-orchestra/node_modules/aws-sdk/lib/s3/managed_upload.js:433:38) at Transform.<anonymous> (/opt/xen-orchestra/node_modules/aws-sdk/lib/s3/managed_upload.js:188:44) at Transform.apply (events.js:314:20) at Transform.patchedEmit (/opt/xen-orchestra/@xen-orchestra/log/src/configure.js:92:17) at Transform.EventEmitter.emit (domain.js:483:12) at emitReadable_ (/opt/xen-orchestra/@xen-orchestra/fs/node_modules/readable-stream/lib/_stream_readable.js:538:12) at processTicksAndRejections (internal/process/task_queues.js:83:21) }Going to try whacking the memory right up ; will report back later today.
-
Ok, been running this all weekend. In positive news, I've not had the timeout error once. In less positive news, I've yet to get a successful backup

With lots of memory and unlimited time, I'm afraid we consistently fail with HANDLE_INVALID. I'm unsure where to go with things from here - @nraynaud let me know what I can do to help rather than throw problems at you. I'm at your disposal.
-
@shorian thank you for your help. can you tell me what kind of backup you were launching and at what phase the error happened ?
-
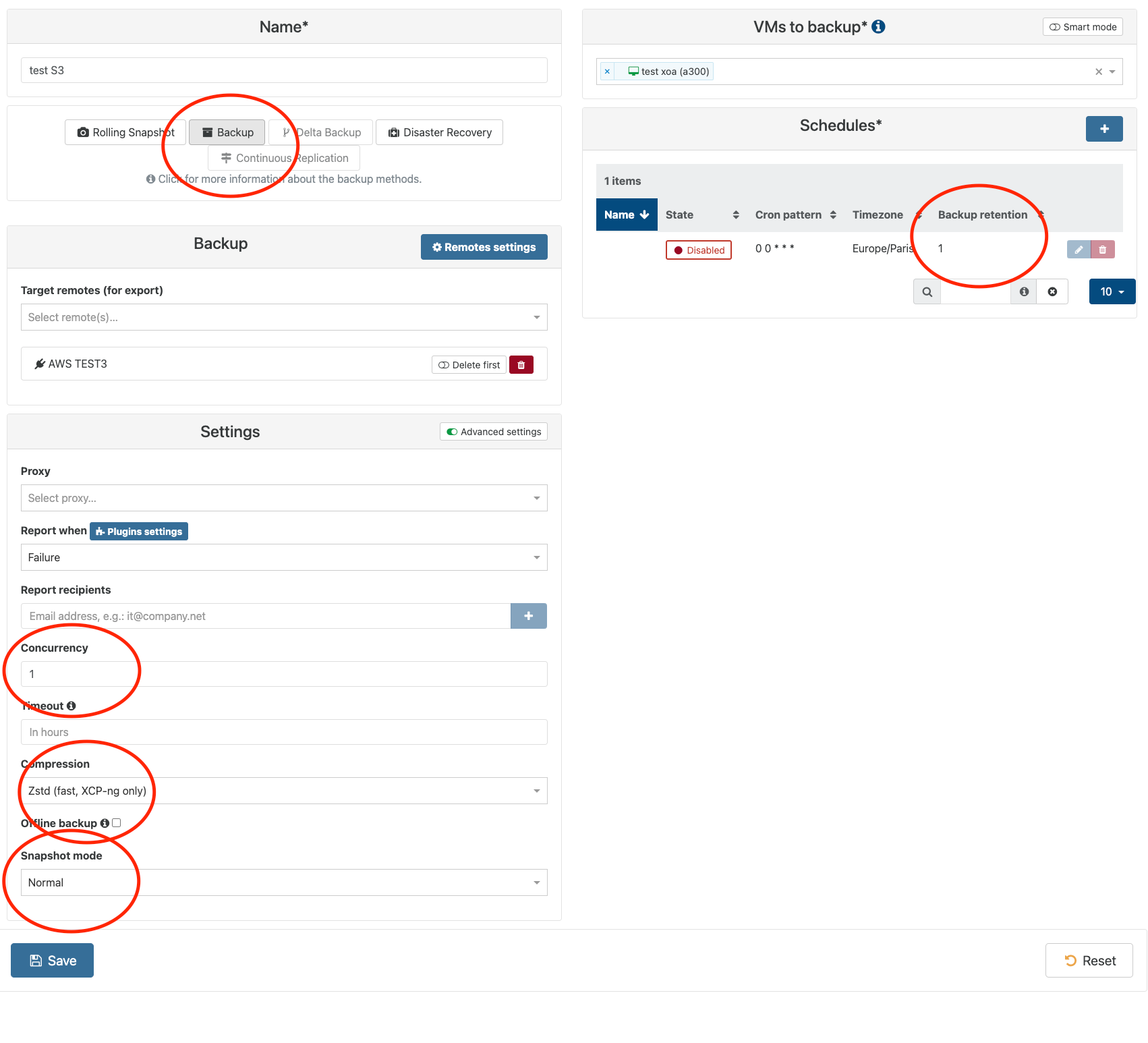
@nraynaud Normal backup to B2, concurrency set to 1, compression set to zsd - no other settings (ie no 'delete before' or 'with memory' - just a standard backup with zstd compression). I have also tried without compression without any variation in outcome.
Error occurs immediately after snapshot (about 5 mins later, but its the next line in the debug log), but we don't fail out for another 18 minutes; we get the bad allocation error every second until we finally die with a terminal 'bad allocation' error and completely fall over with an auto-restart of the script:
2021-01-16T22:20:00.164Z xo:xo-server ERROR uncaught exception { error: RangeError: Array buffer allocation failed at new ArrayBuffer (<anonymous>) at new Uint8Array (<anonymous>) at new FastBuffer (internal/buffer.js:950:1) at createUnsafeBuffer (buffer.js:149:12) at allocate (buffer.js:419:10) at Function.allocUnsafe (buffer.js:384:10) at Function.concat (buffer.js:564:25) at ManagedUpload.fillStream (/opt/xen-orchestra/node_modules/aws-sdk/lib/s3/managed_upload.js:433:38) at Transform.<anonymous> (/opt/xen-orchestra/node_modules/aws-sdk/lib/s3/managed_upload.js:188:44) at Transform.apply (events.js:314:20) at Transform.patchedEmit (/opt/xen-orchestra/@xen-orchestra/log/src/configure.js:92:17) at Transform.EventEmitter.emit (domain.js:483:12) at emitReadable_ (/opt/xen-orchestra/@xen-orchestra/fs/node_modules/readable-stream/lib/_stream_readable.js:538:12) at processTicksAndRejections (internal/process/task_queues.js:83:21) } terminate called after throwing an instance of 'std::bad_alloc' what(): std::bad_alloc error: Forever detected script was killed by signal: SIGABRT error: Script restart attempt #2 2021-01-16T22:20:17.950Z app-conf /opt/xen-orchestra/packages/xo-server/config.toml 2021-01-16T22:20:17.956Z app-conf /root/.config/xo-server/config.toml 2021-01-16T22:20:17.957Z app-conf /root/.config/xo-server/config.z-auto.json 2021-01-16T22:20:17.960Z xo:main INFO Configuration loaded. 2021-01-16T22:20:17.963Z xo:main INFO Web server listening on http://[::]:80Interestingly I've left the backup process to keep running every few hours, and we're now getting some success - I've yet to have the 3 VMs in question all back up in one pass, but the last couple of passes have resulted in one or two of them completing successfully. See sample logs:
2021-01-18T09_00_00.011Z - backup NG.log.txt
2021-01-18T03_00_00.009Z - backup NG.log.txt
In summary, we are now we are getting some timeouts - different than the 12,000ms that we were seeing originally, but now with the new errors in the attached logs of 'no object with UUID or opaque ref'.
If I lower the memory back down to 4gb we revert back to the buffer allocation errors.
I'm very happy to send over more extensive logs but would prefer to do so 1:1 rather than into a public forum.
-
@shorian thank you I will look at all that.
-
I just did a test with this configuration, would you mind checking that it as close as possible as yours? I got a backup to work with this configuration. That suggest we have to search for a limit and not plainly search for a bug.
If it's the same backup configuration, we'll have to look for a difference in the VMs (mine transfers 11.77 GiB of data).
Can you describe your VM please? in particular the number and size of the disks.
thank you for your help.
-
@nraynaud Identical setup, except using B2 not S3.
Initially looking at backing up 3 VMs, each with a single disk sized 100gb, 150gb and 25gb respectively, SR is thin provisioned (ext4), total backup size (compressed) is about 76gb over a 1gbps connection; takes about 90 mins for a clean backup.
Individually they back up fine, as a group they don't. (In total have about 1.2tb of VMs to back up but not trying for that one just yet).
-
Footnote to this - I have just tried to back up 20 small VMs and they all backed up fine; seems to be a function of VM size?
-
@shorian yes, VM size would make sense as a limit, I'll try to run with less memory.
-
@nraynaud I've been playing about with the larger VMs. It may be coincidence, but if I clear out the target (B2), then the backup seems to work ok with the XO that has 16gb mem. However, the second time the same back up is run, the larger machines fail with errors like the following:
Error calling AWS.S3.upload: class java.net.SocketTimeoutException - Read timed out (https://pod-xxx.backblaze.com/bz_internal/upload_part) after 324446 ms.I'll run some tests over the course of the next day or so to see if the above is 100% repeatable or a coincidence...
-
@shorian thank you for your help.
-
@nraynaud Good of you to say; we have a common end goal, and I'm very grateful for your development efforts that are somewhat more useful than mine!
Ok, quick update - I left the backup process running for the larger VMs to see what happened, and somehow the issue seems to flush through? After clearing out the target (Backblaze), the 3 VMs back up fine first time around, the second backup failed with two VMs not backing up but the third went through successfully, then on the second backup only one failed, and now they're all backing up fine. I then had 3 full backups in a row go through cleanly using the XO with 16gb memory and your code from the new master.
I've then cleared down the target, repeated the above, and had the exact same outcome. First pass, all 3 back up, second pass only 1 backs up, third pass 2 back up, third, fourth and fifth all 3 back up fine. Go figure.
Clearly there's something not quite right, but it seems to flush through in time - which is unusual for a technical issue
")
-
@shorian it's been a bit of time, would you mind updating your xen-orchestra and re-trying the bug byt starting a backup with low node.js memory please ?
I have not changed anything, but I'm hopping you had a problem of cached code last time.
-
@nraynaud Afraid re-occurs - it's size of VM dependent; small VMs go through fine, larger VMs as above.
- xo-server 5.74.1
- xo-web 5.77.0
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login