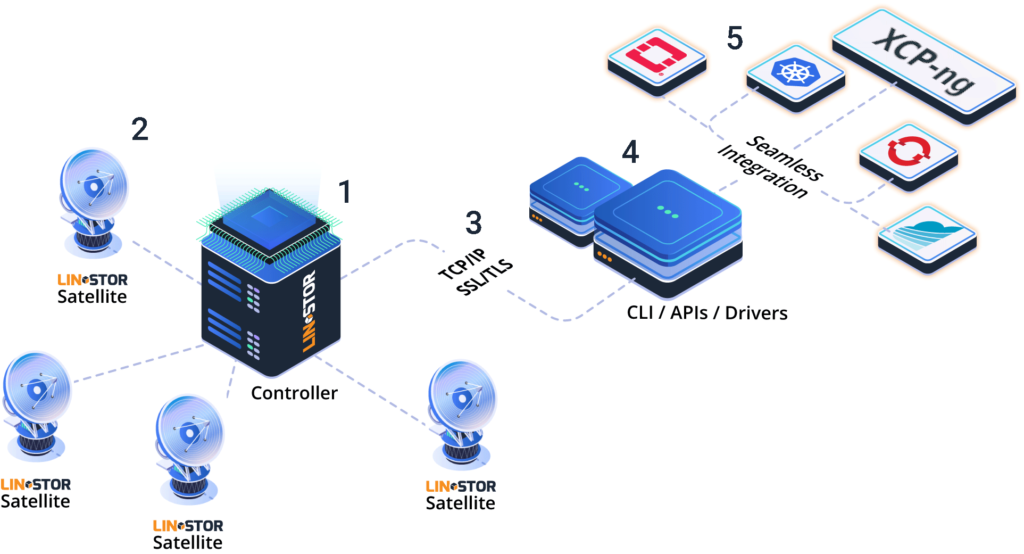
-
@ronan-a I started updating xcp-ng so it can both restart and update on my four nodes (eva, phoebe, mike, ozly).
The nodes were updated with the rolling method, and all three node updated fine, except the forth (mike) (different that the ones that refuses to connect the PBD(eva)) since it is task was stuck at 0.000 progress for 3 hours, so i restarted the toolstack for it(mike) but it didnt do anything, so i restarted the master(eva) node stack. Then when I went to manually update it from XOA, it gives me this error.-1(global name 'commmand' is not defined, , Traceback (most recent call last): File "/etc/xapi.d/plugins/xcpngutils/__init__.py", line 101, in wrapper return func(*args, **kwds) File "/etc/xapi.d/plugins/updater.py", line 96, in decorator return func(*args, **kwargs) File "/etc/xapi.d/plugins/updater.py", line 157, in update raise error NameError: global name 'commmand' is not defined )The good news is, the linstor controller have moved to a different node(phoebe) from the old one(mike) and I was able to delete all volumes in the
linstor --controllers=... resource-definition listexcept for the database, yet the PBD(eva) could not be connected. And the XOA still shows me a lot of disk, and when I scan it I get this errorSR_HAS_NO_PBDS.So now mike server cant update, and eva server cant connect its PBDs while all the other servers are connected. Note eva was the server that I started my linstor installation on.
Do you have any thoughts on what I can do to fix this without reinstalling xcp-ng on mike?
-
Figured out the issue, when I tried to update it from the cli instead. the
/var/logpartition was full due to/var/log/linstor-controllerhaving something like 3.5G+ data (90% of the/var/logvolume). maybe it is due to the past errors it accumulated. I deleted these logs and mike updated normally.Now regarding plugging the PBD to eva (the one host that is not connecting to it). it says the following error.
Error code: SR_BACKEND_FAILURE_202 Error parameters: , General backend error [opterr=Base copy 36a23780-2025-4f3f-bade-03c410e63368 not present, but no original 45537c14-0125-4f6c-a1ad-476552888087 found],this is what linstor resource-definition is showing
[03:59 eva ~]# linstor --controllers=192.168.0.108 resource-definition list -p +---------------------------------------------------------------------------+ | ResourceName | Port | ResourceGroup | State | |===========================================================================| | xcp-persistent-database | 7000 | xcp-sr-linstor_group_thin_device | ok | +---------------------------------------------------------------------------+And here is the KV store for linstor from that script
[04:01 phoebe ~]# mountpoint /var/lib/linstor /var/lib/linstor is a mountpoint [04:01 phoebe ~]# ./linstor-kv-tool-modified --dump-volumes -u 192.168.0.108 -g xcp-sr-xcp-sr-linstor_group_thin_device { "xcp/sr/metadata": "{\"name_description\": \"\", \"name_label\": \"XOSTOR\"}" } [04:01 phoebe ~]# ./linstor-kv-tool-modified --dump-volumes -u 192.168.0.108 -g xcp-sr-linstor_group_thin_device { "xcp/sr/journal/clone/0fb10e9f-b9ef-4b59-8b31-9330f0785514": "86b1b2af-8f1d-4155-9961-d06bbacbb7aa_0e121812-fcae-4d70-960f-ac440b3927e3", "xcp/sr/journal/clone/14131ee4-2956-47b7-8728-c9790764f71a": "dfb43813-91eb-46b8-9d56-22c8dbb485fc_917177d5-d03b-495c-b2db-fd62d3d25b86", "xcp/sr/journal/clone/45537c14-0125-4f6c-a1ad-476552888087": "36a23780-2025-4f3f-bade-03c410e63368_3e419764-9c8c-4539-9a42-be96f92e5c2a", "xcp/sr/journal/clone/54ec7009-2424-4299-a9ad-fb015600b88c": "af89f0fc-7d5a-4236-b249-8d9408f5fb6d_f32f2e8f-a43f-43f5-824b-f673a5cbd988", "xcp/sr/journal/clone/558220bc-a900-4408-a62e-a71a4bb4fd7b": "d9294359-c395-4bed-ac3a-bf4027c92bd9_0e18bf3d-78f0-4843-9e8f-ee11c6ebbf5a", "xcp/sr/journal/clone/c41e0d47-5c1a-45c3-9404-01f3b5735c0d": "e191eb57-2478-4e3b-be9d-e8eaba8f9efe_41eae673-a280-439b-a4c6-f3afe2390fde", "xcp/sr/journal/relink/50170fa2-2ca9-4218-8217-5c99ac31f10b": "1" }I destroyed the PBD and then recreated it to make it just connect so I can destroy the SR, but the same error happened when I tried to connect with the new PBD that has the same config as the other PBD
-
those two UUIDs are in the
./linstor-kv-tool-modified --dump-volumes -u 192.168.0.108 -g xcp-sr-linstor_group_thin_devicedevice output./linstor-kv-tool-modified --dump-volumes -u 192.168.0.108 -g xcp-sr-linstor_group_thin_device { "xcp/sr/journal/clone/0fb10e9f-b9ef-4b59-8b31-9330f0785514": "86b1b2af-8f1d-4155-9961-d06bbacbb7aa_0e121812-fcae-4d70-960f-ac440b3927e3", "xcp/sr/journal/clone/14131ee4-2956-47b7-8728-c9790764f71a": "dfb43813-91eb-46b8-9d56-22c8dbb485fc_917177d5-d03b-495c-b2db-fd62d3d25b86", "xcp/sr/journal/clone/45537c14-0125-4f6c-a1ad-476552888087": "36a23780-2025-4f3f-bade-03c410e63368_3e419764-9c8c-4539-9a42-be96f92e5c2a", "xcp/sr/journal/clone/54ec7009-2424-4299-a9ad-fb015600b88c": "af89f0fc-7d5a-4236-b249-8d9408f5fb6d_f32f2e8f-a43f-43f5-824b-f673a5cbd988", "xcp/sr/journal/clone/558220bc-a900-4408-a62e-a71a4bb4fd7b": "d9294359-c395-4bed-ac3a-bf4027c92bd9_0e18bf3d-78f0-4843-9e8f-ee11c6ebbf5a", "xcp/sr/journal/clone/c41e0d47-5c1a-45c3-9404-01f3b5735c0d": "e191eb57-2478-4e3b-be9d-e8eaba8f9efe_41eae673-a280-439b-a4c6-f3afe2390fde", "xcp/sr/journal/relink/50170fa2-2ca9-4218-8217-5c99ac31f10b": "1" }So I basically deleted all of the keys here, Maybe I should not have done that, but when I did, eva plugged in correctly to the SR and I was able to finally destroying the SR from XOA. So yeah happy ending. Will try the next beta version. Thank you @ronan-a for your work.
-
@ronan-a I tried following the guide that you posted to remove the linstor volumes manually but the resource-definition list command already showed a bunch of resources in a "DELETING" state.
[22:24 xcp-ng-node-1 ~]# linstor --controllers=192.168.10.211 resource-definition list ╭──────────────────────────────────────────────────────────────────────────────────────────────────────╮ ┊ ResourceName ┊ Port ┊ ResourceGroup ┊ State ┊ ╞══════════════════════════════════════════════════════════════════════════════════════════════════════╡ ┊ xcp-persistent-database ┊ 7000 ┊ xcp-sr-linstor_group_thin_device ┊ ok ┊ ┊ xcp-persistent-ha-statefile ┊ 7001 ┊ xcp-sr-linstor_group_thin_device ┊ ok ┊ ┊ xcp-persistent-redo-log ┊ 7002 ┊ xcp-sr-linstor_group_thin_device ┊ ok ┊ ┊ xcp-volume-13a94a7a-d433-4426-8232-812e3c6dc52e ┊ 7004 ┊ xcp-sr-linstor_group_thin_device ┊ DELETING ┊ ┊ xcp-volume-4b70d69b-9cca-4aa3-842f-09366ac76901 ┊ 7006 ┊ xcp-sr-linstor_group_thin_device ┊ ok ┊ ┊ xcp-volume-50aa2e9f-caf0-4b0d-82f3-35893987e53b ┊ 7010 ┊ xcp-sr-linstor_group_thin_device ┊ DELETING ┊ ┊ xcp-volume-55c5c3fb-6782-46d6-8a81-f4a5f7cca691 ┊ 7012 ┊ xcp-sr-linstor_group_thin_device ┊ ok ┊ ┊ xcp-volume-5ebca692-6a61-47ec-8cac-e4fa0b6cc38a ┊ 7016 ┊ xcp-sr-linstor_group_thin_device ┊ ok ┊ ┊ xcp-volume-668bcb64-1150-43ac-baaa-db7b92331506 ┊ 7014 ┊ xcp-sr-linstor_group_thin_device ┊ ok ┊ ┊ xcp-volume-6f5235da-8f01-4057-a172-5e68bcb3f423 ┊ 7007 ┊ xcp-sr-linstor_group_thin_device ┊ DELETING ┊ ┊ xcp-volume-70bf80a2-a008-469a-a7db-0ea92fcfc392 ┊ 7009 ┊ xcp-sr-linstor_group_thin_device ┊ ok ┊ ┊ xcp-volume-92d4d363-ef03-4d3c-9d47-bef5cb1ca181 ┊ 7015 ┊ xcp-sr-linstor_group_thin_device ┊ ok ┊ ┊ xcp-volume-9a413b51-2625-407a-b05c-62bff025b947 ┊ 7005 ┊ xcp-sr-linstor_group_thin_device ┊ ok ┊ ┊ xcp-volume-a02d160d-34fc-4fd6-957d-c7f3f9206ae2 ┊ 7008 ┊ xcp-sr-linstor_group_thin_device ┊ DELETING ┊ ┊ xcp-volume-ed04ffda-b379-4be7-8935-4f534f969a3f ┊ 7003 ┊ xcp-sr-linstor_group_thin_device ┊ DELETING ┊ ╰──────────────────────────────────────────────────────────────────────────────────────────────────────╯Executing resource-definition delete has no impact on them. I just get the following output:
[22:24 xcp-ng-node-1 ~]# linstor resource-definition delete xcp-volume-13a94a7a-d433-4426-8232-812e3c6dc52e SUCCESS: Description: Resource definition 'xcp-volume-13a94a7a-d433-4426-8232-812e3c6dc52e' marked for deletion. Details: Resource definition 'xcp-volume-13a94a7a-d433-4426-8232-812e3c6dc52e' UUID is: 52aceda9-b19b-461a-a119-f62931ba1af9 WARNING: Description: No active connection to satellite 'xcp-ng-node-3' Details: The controller is trying to (re-) establish a connection to the satellite. The controller stored the changes and as soon the satellite is connected, it will receive this update. SUCCESS: Resource 'xcp-volume-13a94a7a-d433-4426-8232-812e3c6dc52e' on 'xcp-ng-node-1' deleted SUCCESS: Resource 'xcp-volume-13a94a7a-d433-4426-8232-812e3c6dc52e' on 'xcp-ng-node-2' deletedI can confirm that node-1 can reach node-3 which it is complaining about for some reason. And I can see node-3 in XO as well and can run VMs on them.
-
@TheiLLeniumStudios In this case, if DRBD is completely stuck, you can reboot your hosts. There is probably a lock or processes that have a lock on them.
")
-
@AudleyElwine Thank you for your feedbacks, I will update the script to handle the journal cases.
")
-
@ronan-a 2 of the nodes broke after restarting. I just kept getting the blinking cursor at the top left of the screen for hours. I'm going to have to reprovision all the nodes again sadly

-
Hey @ronan-a ,
What should I do to lower the chance of something in the past installation of xostor to affect my new installation?
lsblkis still showing the linstor volumes,vgsis also showinglinstor_group.
Will awipefs -afbe enough? Or is the "Destroying SR" button in XOA is enough? -
@AudleyElwine The PVs/VGs are kept after a
SR.destroycall but it's totally safe to reuse them for a new installation. The content of/var/lib/linstoris not removed after a destroy call, but it's normally not used because the linstor database is shared between hosts using a DRBD volume and mounted in this directory by the running controller. So you don't have manual steps to execute here.Of course if you want to reuse your disks for another thing,
wipefsis nice for that. -
@TheiLLeniumStudios There are always a solution to repair nodes, what's the output of
linstor --controllers=<HOST_IPS> node list?(Use a comma separated values for HOST_IPS.)
-
We just hit a weird issue that we managed to fix, but wasn't really clear at first what was wrong, and might be a good idea for you guys to add some type of healthcheck / error handling to catch this and fix it.
What happened was that for some unknown reason, our
/var/lib/linstormount (xcp-persistent-database) became read only, but everything kinda kept working-ish, but some stuff would randomly fail, like attempting to delete a ressource. Upon looking at the logs, saw this :Error message: The database is read only; SQL statement: UPDATE SEC_ACL_MAP SET ACCESS_TYPE = ? WHERE OBJECT_PATH = ? AND ROLE_NAME = ? [90097-197]We did a quick write test on the mount
/var/lib/linstorand saw that it was indeed in RO mode. We also noticed that the last update time on the db file was 2 days ago.Unmounting the mount and remounting it had the controller start back again, but the first time, some nodes were missing from the node list, so we restarted the linstor-controller service again and everything is now up and healthy.
-
I think we have a relatively important number of updates coming, fixing various potential bugs
Stay tuned! -
@olivierlambert any eta for the next beta release? Looking forward to test it.
-
Very soon

-
@Maelstrom96 said in XOSTOR hyperconvergence preview:
What happened was that for some unknown reason, our /var/lib/linstor mount (xcp-persistent-database) became read only
There is already a protection against that: https://github.com/xcp-ng/sm/commit/55779a64593df9407f861c3132ab85863b4f7e46 (2021-10-21)
So I don't understand how it's possible to have a new time this issue. Without the log files I can't say what's the source of this issue, can you share them?
Did you launch a controller manually before having this problem or not? There is a daemon to automatically mount and start a controller:
minidrbdcluster. All actions related to the controllers must be executed by this program.Another idea, the problem can be related to: https://github.com/xcp-ng/sm/commit/a6385091370c6b358c7466944cc9b63f8c337c0d
But this commit should be present in the last release. -
@ronan-a Is there a way to easily check if the process is managed by the daemon and not a manual start? We might have some point restarted the controller manually.
Edit :
● minidrbdcluster.service - Minimalistic high-availability cluster resource manager Loaded: loaded (/usr/lib/systemd/system/minidrbdcluster.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2023-01-25 15:58:01 EST; 1 weeks 0 days ago Main PID: 2738 (python2) CGroup: /system.slice/minidrbdcluster.service ├─2738 python2 /opt/xensource/libexec/minidrbdcluster ├─2902 /usr/sbin/dmeventd └─2939 drbdsetup events2[11:58 ovbh-pprod-xen10 system]# systemctl status var-lib-linstor.service ● var-lib-linstor.service - Mount filesystem for the LINSTOR controller Loaded: loaded (/etc/systemd/system/var-lib-linstor.service; static; vendor p reset: disabled) Active: active (exited) since Wed 2023-01-25 15:58:03 EST; 1 weeks 0 days ago Process: 2947 ExecStart=/bin/mount -w /dev/drbd/by-res/xcp-persistent-database /0 /var/lib/linstor (code=exited, status=0/SUCCESS) Main PID: 2947 (code=exited, status=0/SUCCESS) CGroup: /system.slice/var-lib-linstor.serviceAlso, what logs would you like to have?
Edit2 : Also, I don't believe that service would've actually caught what happened, since it was mounted first using RW, but seems like DRBD had an issue while the mount was active and changed it to RO. The controller service was still healthy and active, just impacted on DB writes.
-
@Maelstrom96 It's fine to restart the controller on the same host where it was running. But if you want to to move the controller on another host, just temporarily stop
minidrbdclusteron the host where the controller is running. Then you can restart it.The danger is to start a controller on a host where the shared database is not mounted in
/var/lib/linstor.To resume, if the database is mounted (check using
mountpoint /var/lib/linstor) and if there is a running controller: no issue.Edit2 : Also, I don't believe that service would've actually caught what happened, since it was mounted first using RW, but seems like DRBD had an issue while the mount was active and changed it to RO. The controller service was still healthy and active, just impacted on DB writes.
So if it's not related to a database mount, the system may have changed the mount point to read only for some reason yes, it's clearly not impossible.
Also, what logs would you like to have?
daemon.log, SMlog, kern.log, (and also drbd-kern.log if present)
-
@ronan-a I will copy those logs soon - Do you have a way I can provide you the logs off forum since it's a production systems?
-
Not sure what we're doing wrong - Attempted to add a new host to the linstor SR and it's failing. I've run the install command with the disks we want on the host, but when running the "addHost" function, it fails.
[13:25 ovbh-pprod-xen13 ~]# xe host-call-plugin host-uuid=6e845981-1c12-4e70-b0f7-54431959d630 plugin=linstor-manager fn=addHost args:groupName=linstor_group/thin_device There was a failure communicating with the plug-in. status: addHost stdout: Failure stderr: ['VDI_IN_USE', 'OpaqueRef:f25cd94b-c948-4c3a-a410-aa29a3749943']Edit : So it's not documented, but it looks like it's failing because the SR is in use? Does that mean that we can't add or remove hosts from linstor without unmounting all VDIs?
-
@Maelstrom96 No you can add a host with running VMs.
I suppose there is a small issue here... Please send me a new time your logs (SMlog of each host).
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login