VDI_IO_ERROR Continuous Replication on clean install.

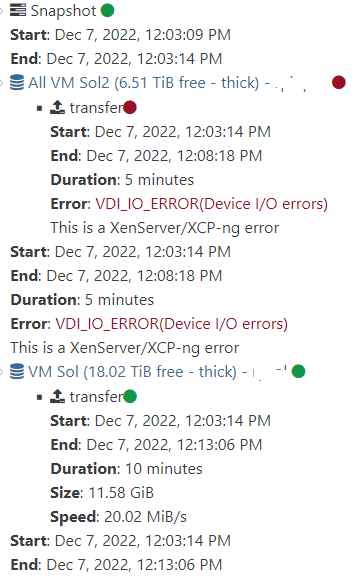
-
Also with iSCSI storage, right?
-
@olivierlambert not really. This time is just local ext storage, SATA drives.
-
In LVM or thin? It might be 2 different problems, so I'm trying to sort this out.
-
@olivierlambert both! I have both mixed in my servers and I tried in both when I did the tests
-
just remember i have one server with fresh 8.2.1 and nfs backups to TrueNAS. it working.
will do other tests tomorrow. -
@olivierlambert
sr_not_supportedthat not a error and not a reason. That because of default multipath Dell config for 3xxx series. Persist at 8.2.0 where CR working, so that just a warning.
As we have no any problems before, we never investigate to this setting. My bad again") yay.
yay.Replaced it to official for 4xxx and this warning gone. I see at 8.3 it already more universal for any generation.
device { vendor "DellEMC" product "ME4" path_grouping_policy "group_by_prio" path_checker "tur" hardware_handler "1 alua" prio "alua" failback immediate path_selector "service-time 0" }since it no default config for huawei, so we always used the official one.
device { vendor "HUAWEI" product "XSG1" path_grouping_policy multibus path_checker tur prio const path_selector "round-robin 0" failback immediate fast_io_fail_tmo 5 dev_loss_tmo 30 }-
8.2.1:
-
CR not working:
both huawei, dell iscsi - multipath enabled
both huawei, dell iscsi - multipath disabled -
working:
nfs vm disk
local thin\ext
local thick\lvm -
8.3
-
working:
both huawei, dell iscsi - multipath enabled
local thick\lvm
and now interesting. After i solved this false warning, detach extra hosts from pool, detach all additional links (trunk, backup) to decrease comunications and log itself - it's no any SMlog generated during backup task.
MP enabled - with 2nd link for backup https://pastebin.com/URcnDckR
MP enabled - only Mng link, no SMlog generated https://pastebin.com/RHw40uzg -
-
 I have the impression it's good news, but I'm not 100% sure to get it, can you rephrase a bit your conclusion?
I have the impression it's good news, but I'm not 100% sure to get it, can you rephrase a bit your conclusion? -
if i have no smlog - xen\dom0 not related with backup task. right?
smlog that usualy i got during this 5min have no any errors anyway, only some locking operations.
And it always takes 5min, some hardcoded timings?don't forget that problem also happens with FC connection, so it may concern any block based storage types.
-
I don't understand your sentence, can you take time to re-read it or rephrase it, because I doesn't make sense to me, sorry

What do you mean by "if i have no smlog - xen\dom0 not related with backup task. right?"?
-
i mean it could be XO issue, since it not communicate with xen. Otherwise it should write some logs.
-
I don't see the logical connection with XO, since it works on some SR and not on others. XO has no idea (or doesn't care) about the underlying storage.
-
well, i'm just made some tests and got some result. Have no idea how it should work)
-
i don't understand what happens.
Reinstalled xen to 8.2.0, CR was succeed for few times, but now i got this error again.Tried few tests - 2-3 fails in row then it succeed again.
Only way to never use this pool for CR. -
I also have some fresh installation 8.2.1 with similar error at 5 mins 2seconds 5 min 1 sec
-
On my side, yesterday I did the only test I haven't done so far: Installing XenOrchestra in a NON xcp-ng server.
Basically, since always, I had a separated XCP-NG server with just a single VM inside: The XO VM (Just in case, that VM was Ubuntu, Centos, Debian over time, so the base OS has nothing to do with this).
My solution for this was simple: Bare metal Linux. So the problem wasn't the XCP version on the source server, nor the destination server. It was the host server of the XO VM itself
Why? I have no idea, but it's definitely working now since I started a CR task yesterday, of a 1TB VM, with a destination server over internet, and is still exporting after 14 hours without any issues:
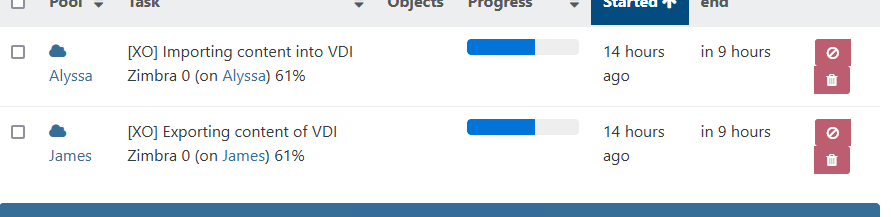
-
@yomono And to clarify, for this XO host, I tested 8.2.0, 8.2.1, and 8.3.0 fresh installs and all failed at exactly 5 minutes
-
This means your Node version was still using the default timeout.
-
@olivierlambert when you say "node" you mean node.js? How that timeout can be changed? Thanks
-
changing the node will fix this vdi error ?
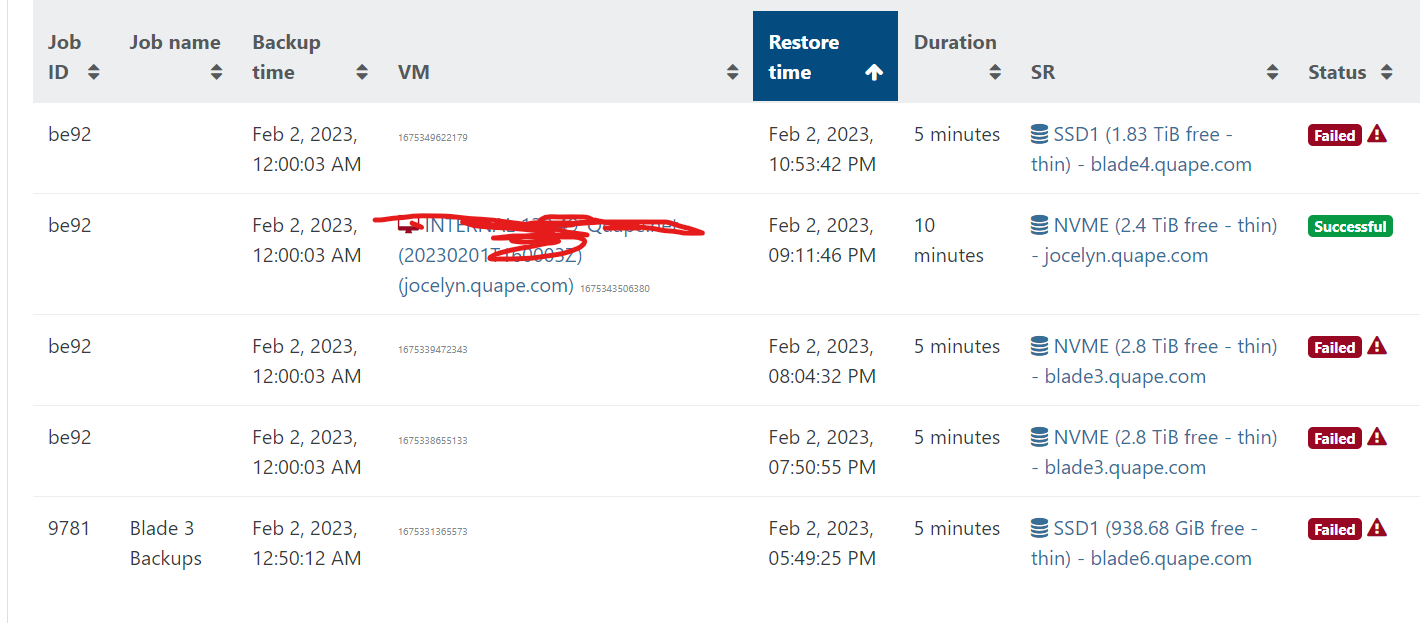
-
@EddieCh08666741 The one which works is the fresh install without any updates.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login