Xen Orchestra Load Balancer - turning on hosts
-
Well, the hosts are shutting down with no issues.
What is happening is that usually LB will migrate all the VMs to the pool master and then shut down all other hosts. My issue is with LB sending (or in my case not sending) WoL packets when I try to start/deploy new VM that doesn't fit on pool master anymore.
-
Oh yes, your hosts will shutdown OK
")
But IIRC, when you'll try to make a SR operation (like a VM snapshot) while one host is down, you'll have an error. Feel free to test it so we can be 100% sure

-
@olivierlambert I see what you did there
- My mistake - currently I use SMB shared storage, not NFS.
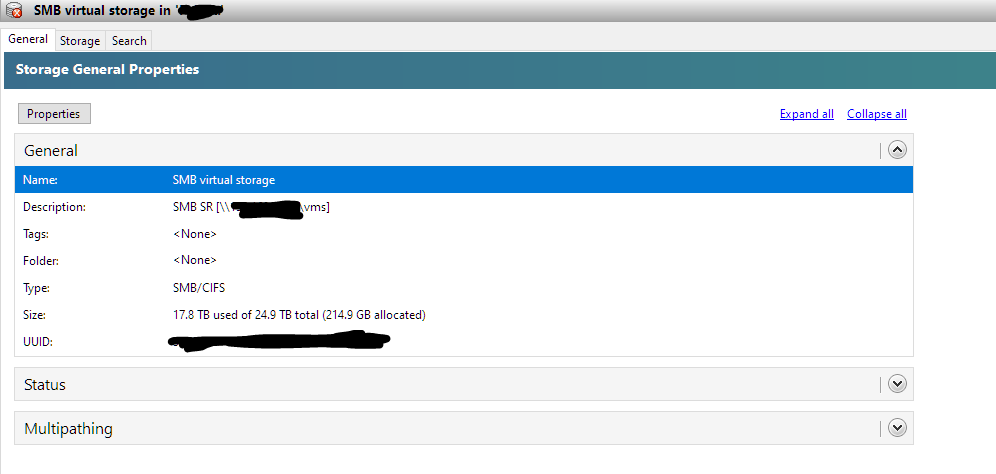
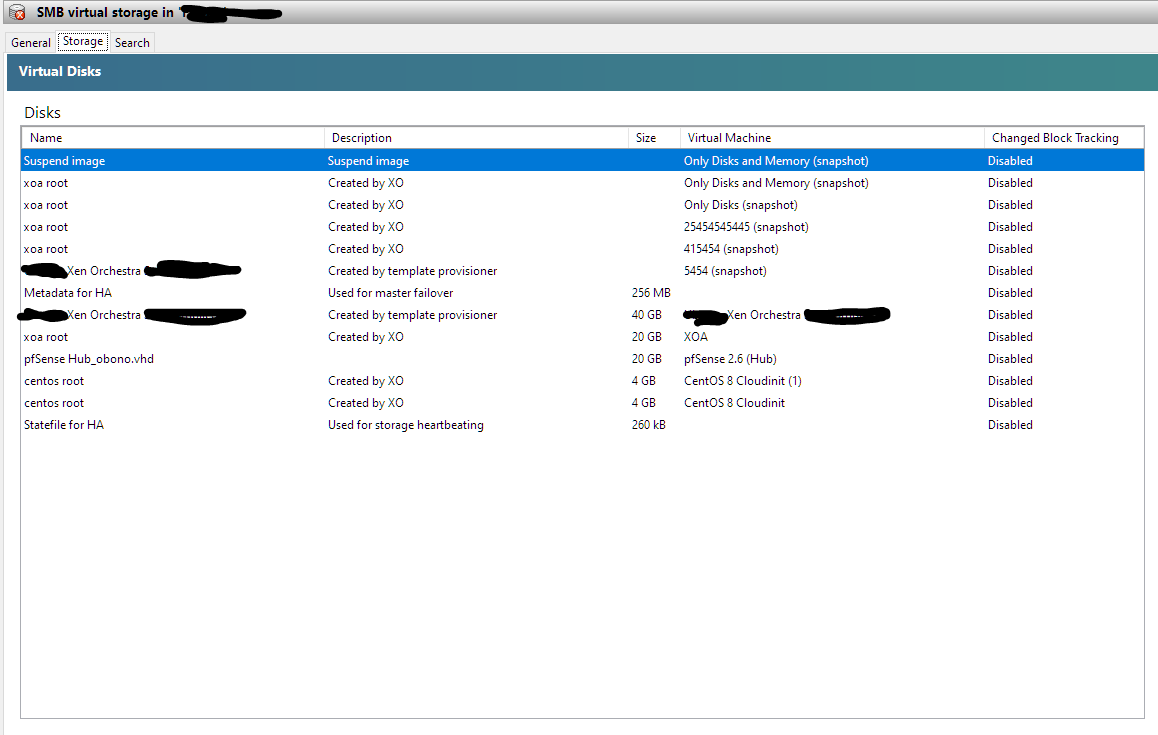
- Booted up the pool, waited for LB to shut down everything except master. Then decided to snapshot the XOA itself using XCP-ng center.
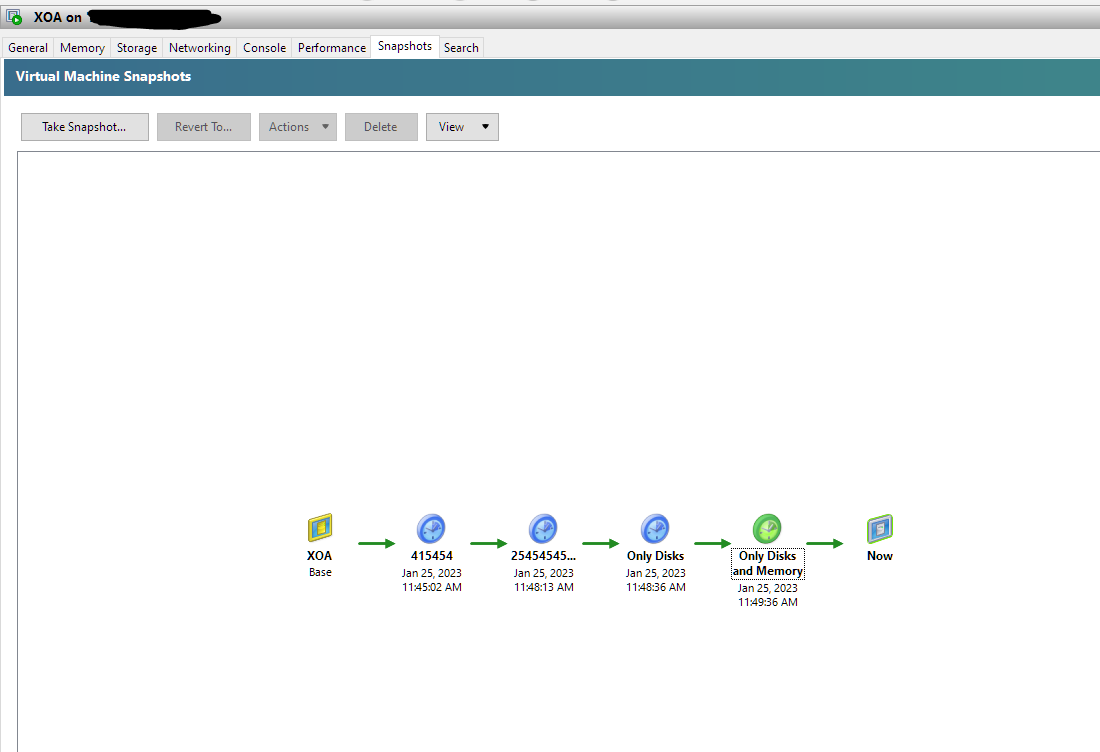
No issues whatsoever. Just disks, with memory, everything is fine. The XOA is on SMB SR.
- Snapshoted the XOA using... XOA.
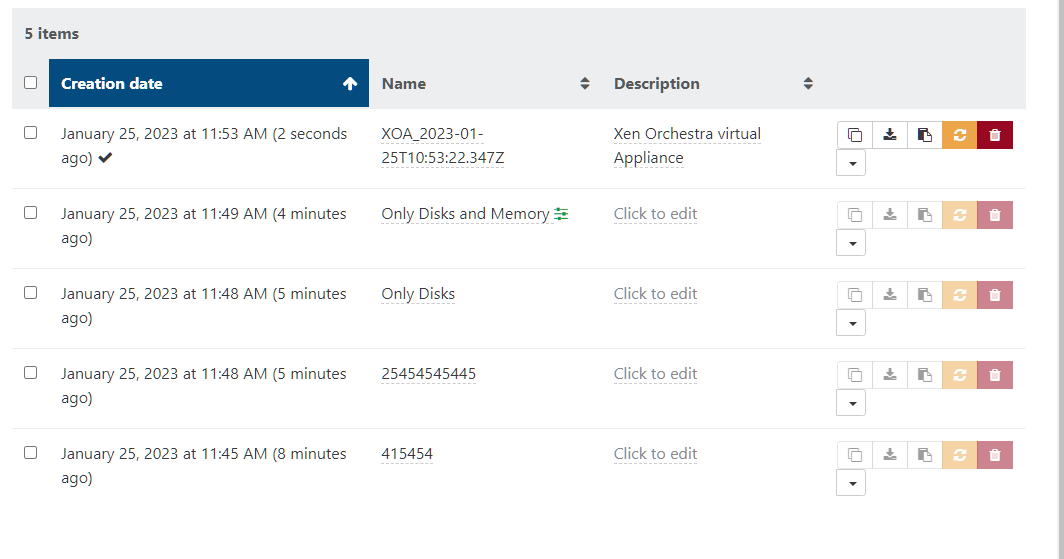
Also no issues.

-
 I would have asked to live migrate on the left host, but IDK how many hosts you have in your pool. Also, please don't provide XCP-ng Center screenshot, I'm allergic to this tool, that I will hope will die at some point
I would have asked to live migrate on the left host, but IDK how many hosts you have in your pool. Also, please don't provide XCP-ng Center screenshot, I'm allergic to this tool, that I will hope will die at some point  (when XO Lite will replace it)
(when XO Lite will replace it) -
Live migrate VM from one host to another? That was working yesterday, as long as I exclude the host from LB. I can do that if you come up with a test-case
You may be allergic to XCP-ng, but sometimes it is the single reason to have windows installed
There are some things that are easier to find (like WoL settings, I found it by mistake in XCP-ng, no idea where it is in Orchestra), but most important thing is that Center is outside the pool, so in case of screw-up I can control the pool and start Orchestra -
As it will be possible with XO Lite
")
Anyway, back to the topic, I wonder if the behavior is different between NFS and SMB shared SR
I do remember seeing those limitation with "half powered on" pool, but I don't remember which operations exactly. -
@olivierlambert said in Xen Orchestra Load Balancer - turning on hosts:
Anyway, back to the topic, I wonder if the behavior is different between NFS and SMB shared SR I do remember seeing those limitation with "half powered on" pool, but I don't remember which operations exactly.
State right now is that SR is "Broken" because it is Unplugged from hosts... because, you know... the hosts are down.
Snapshotting works, migration works as well (when hosts in pool are down). Also, IIRC there are no issues when hosts in a pool are down and VMs are hosted on the SR storage. That is something that happened quite often in many previous projects.
So my issue with LB plugin is deterministic way of knowing under which conditions will it spin hosts back up.
@olivierlambert said in Xen Orchestra Load Balancer - turning on hosts:
As it will be possible with XO Lite
That is awesome, no more Windows for me
-
This post is deleted! -
By looking into the source of the plugin, it looks like all the currently implemented behavior is observed.
It calculates/simulates the best plan, moves VMs and tries to shut down the host. Nothing about waking the hosts up.
And that makes sense, as the feature of spinning hosts back up should be implemented elsewhere (in context of density plan) - when starting VM, instead of providing the error message "No hosts that are able to run this VM are online", there should/could/may be:
- Evaluation of which host is the smallest one which would be able to host the desired VM (partially implemented in density-plan) and WoL/iDrac/iLO packet send to it(implemented in performance plan)
- Some timeout/waiting for boot pop-up/dialog/having this thing in queue
- After set time (let's say 5 min), call the currently implemented logic of starting VM in a pool.
P.S. Would be nice to be able to set, how often the plan is evaluated (currently 1 minute), so until "spinning hosts back up" functionality is implemented, at least host started manually won't be shut down by plan immediately.
-
Adding @ronan-a in the loop so we don't forget this
-
@olivierlambert Thank you!
-
@berish-lohith Just FYI I created a card in our backlog, I don't see too many blocking points to implement it correctly.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login