A "socket" was not created for HTTP request before 300000ms
-
@olivierlambert
v19 is not working also . i have tested last friday and theare is no difference -
Okay thanks
")
-
@olivierlambert
i have also checked bios settings , raid settings and everyhing is same , the only difference betwen the working server and non working server is Hard Drive producer, but i cannot blame hard disk caz they are working perfect and to write and to read. Honestley i do not know what to try anymore -
My case is the same. All Dell servers with same hardware. The disks are all Western Digital disks in all servers. They are just different models in the different servers. (Of course each server as same models).
Everything works good in 2 hosts only in host 3 I have these Issues.
-
@olivierlambert
commit 1fbe870884a426b35f762a77fd6f3bba6dfa75b0 with node 19.7 same problem.
On XOA I can't, I am on trial now. -
@olivierlambert I tested few weeks back with 19 not working too.
-
@olivierlambert
any news regarding this bug , -
@julien-f is currently investigating on it.
-
btw continuous replication is not working also
-
After several tests, it seems that the error occurs in the transfer differential. Below VM 2 finishes approximately 14 minutes earlier than VM 1, which is more than 300 seconds. If I have a transfer of an single VM on a single NFS Share (NAS) everything is ok. Another thing is that I switched the XOCE on Debian 11.6 instead of Ubuntu server 22.04.2.
For example, below I have a transfer difference between the two VMs that are on two separate servers with same backup job.
Another example is the transfer difference for the same VM on several Storage NAS, I have on 3 different NFSs Share as backup.
-
well for me the error apears even if i start only one backup at a time from only one server, the problem is at source backup not destination for example same machine can be copied from one server and on the other server same machine cannot be copied and error apears after 5 minutes, the migration works well. This error is on the oficial xoa also i have tried from sources on debian ubuntu and rocky linux 9 , the error is not fro OS
-
On backup I see this.
This is the job
this is the error
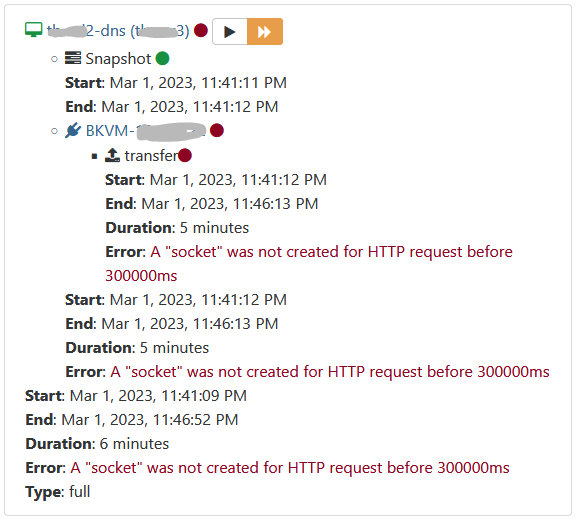
server 2 is more slow that server 3, and the error is on server 3 that finish in first 6 min in comparison with server 2 that it finish in 20 min and basically says that server 3 it hasn't responded for 5+ min.
-
After I made some change on slow server I manage to get under 5 min difference and is green. Same setup, less VM running.
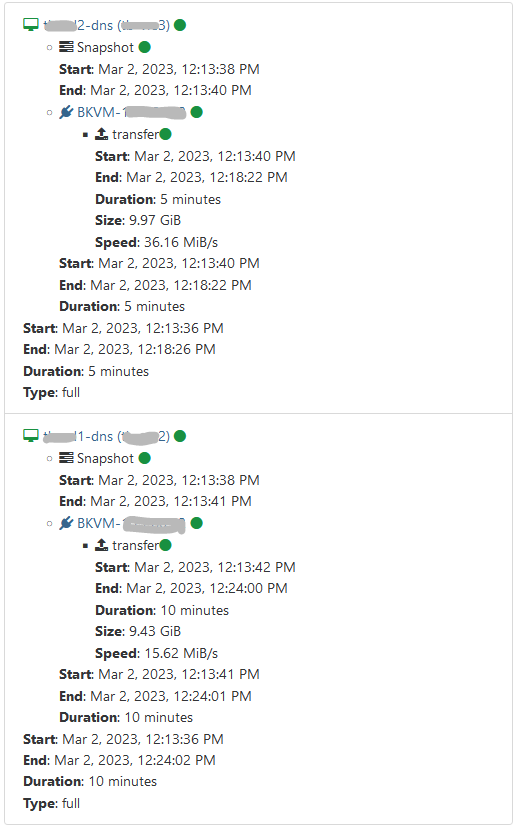
-
@Gheppy
what changes have u did ? -
@arsenieciprian
For me, server 2 moves slower because it is busier and I opted to stop some virtual machines in such a way that I have almost the same transfer speed. I rebuilt XOCE from scratch with the latest version in two versions, one on debian 11.6 and the other on rocky linux 9, both behave the same.Edit:
this is working with only one backup connexion (NFS share) -
@Gheppy
is not about speed, i have in one datacenter some ancient servers and backups and restore are working well and speed is much slower than this one that give;s this error -
@arsenieciprian
not the speed itself but the transfer speed, it must be about the same on all sources or destinations or the time difference should not exceed 5 minutesEdit:
if you have a connection on the source to the first of 10000 and the second of 1000 and on the destination of 10000, you will more than likely have the error -
@Gheppy
it does not have to be a problem speed transfer TCP must do his job and limit transfer between , what about if we transfer over internet , is not allways gigabit or 10 gb, i allready tested if this must be a reason -
@arsenieciprian.
For me all backups are working now, except that one. And that I split it into 2 simple backups -
I am not sure this adds much to the discussion, but I am also experiencing this issue since the latest update a day or two ago.
xoa 5.80.0
xo-server 5.110.0I have two hosts in a pool and a single backup location but some backups have completed (all under 5 minutes) and then others have failed at the 5 minute mark from both hosts - I was originally thinking maybe just one host but have success and failure form both to the same location.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login